



 这篇博客探讨了二分类问题中的Logistic回归,介绍了sigmoid激活函数和损失函数的概念。文章深入讲解了梯度下降法在优化参数w和b中的应用,并提到了向量化在提升效率中的作用。此外,还讨论了SVM、正则化、神经网络的构建,以及在训练过程中防止过拟合的方法。卷积神经网络(CNN)的部分,解释了卷积层、池化层的工作原理和参数计算,同时提到了数据增强和权重初始化的重要性。最后,上采样的概念被提及,用于解决CNN输出尺寸减小的问题。
这篇博客探讨了二分类问题中的Logistic回归,介绍了sigmoid激活函数和损失函数的概念。文章深入讲解了梯度下降法在优化参数w和b中的应用,并提到了向量化在提升效率中的作用。此外,还讨论了SVM、正则化、神经网络的构建,以及在训练过程中防止过拟合的方法。卷积神经网络(CNN)的部分,解释了卷积层、池化层的工作原理和参数计算,同时提到了数据增强和权重初始化的重要性。最后,上采样的概念被提及,用于解决CNN输出尺寸减小的问题。
二分类法
logistic回归是一个用于二分分类的算法,是一个二元分类问题,用于输出y等于0还是1的概率是多大

由两个参数w,b组成一个线性方程,我们需要学习这个w和b,但是y hot 可能大于1,所以我们要引入sigmoid函数将它变换为0-1之间,具体计算带入过程如图所示

这里是表示loss函数,损失函数由自己定义,是对于单个样本而言的,而下面的成本函数是针对整个训练集的,在损失函数当中我们会把w和b带入进去计算
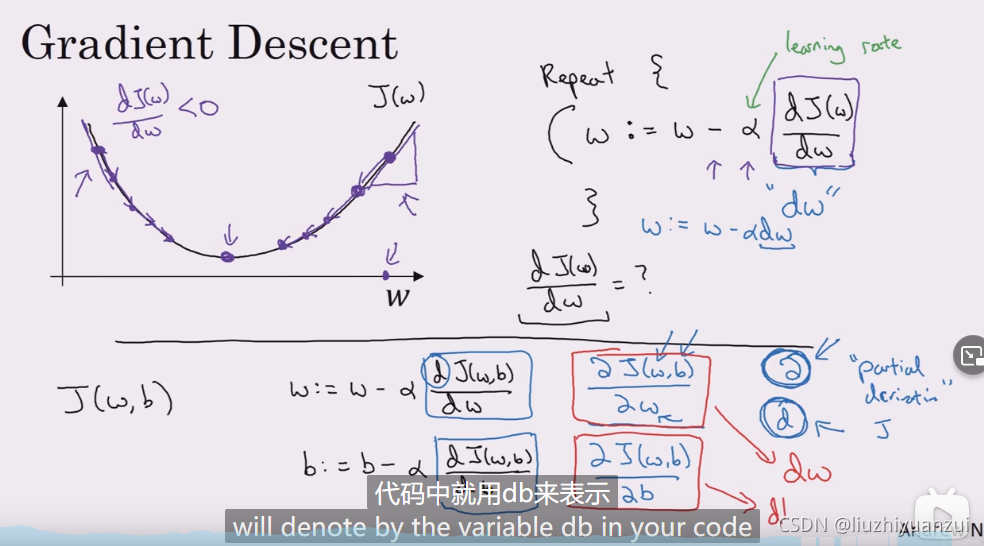
梯度下降法就是让成本函数取得局部最优值,使用的是梯度下降法,这里是对w和b进行求导,不断迭代,,更新w和b,更新的公式如上图所示

注意这里的w是一个矩阵,而不是一个数,所以展开后的式子如上图所示
向量化SVM一般是用来消除代码中的for循环,因为for循环会比较浪费资源

非向量化就是左边的for形式,SVM就是右边的代码形式,一步到位,向量化也就是将其表示为矩阵的形式,然后调用函数进行计算
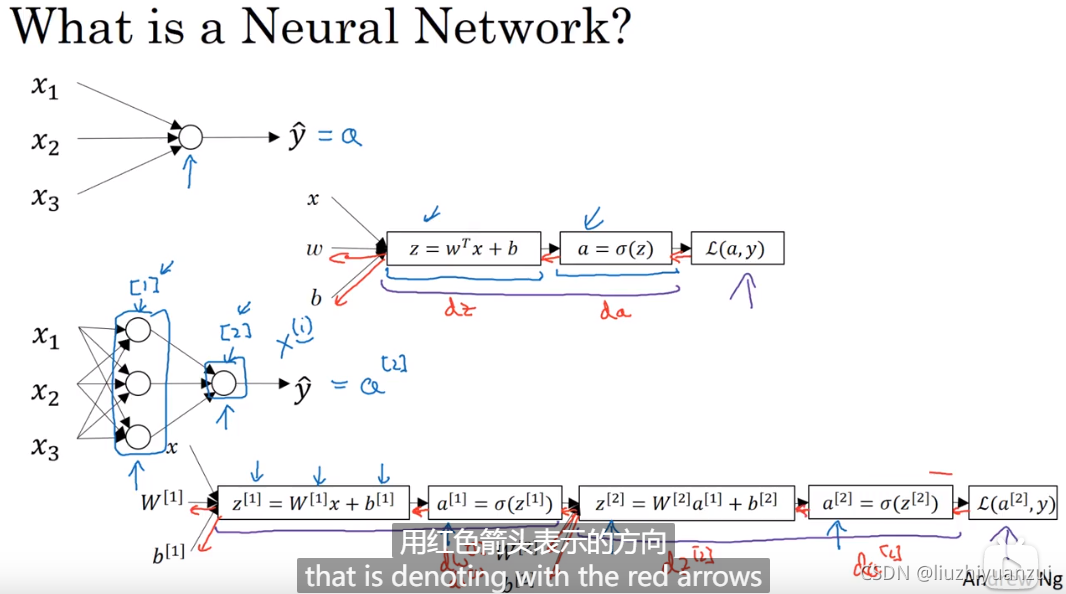
这个图总结了上述所有的知识点,构建出了一个神经网络
激活函数可以是的ð函数,这个激活函数用在二分类中
但现在基本上都用正切函数来坐激活函数,或者relu函数
反向传播相当于求导数
我们再选择w和b的时候可以随机的生成然后*0.01,b可以设置为0
有些参数决定了w和b的取值,这种就叫做超参数
尽量要确保训练集和测试集处于同一分布

第一行为训练集的误差,第二行为验证集的误差,第一列当二者相差较大时,称之为过拟合,因为只有训练集一开始参加训练,验证集是在训练好的网络上进行的
如果过度拟合了,可以采用正则化
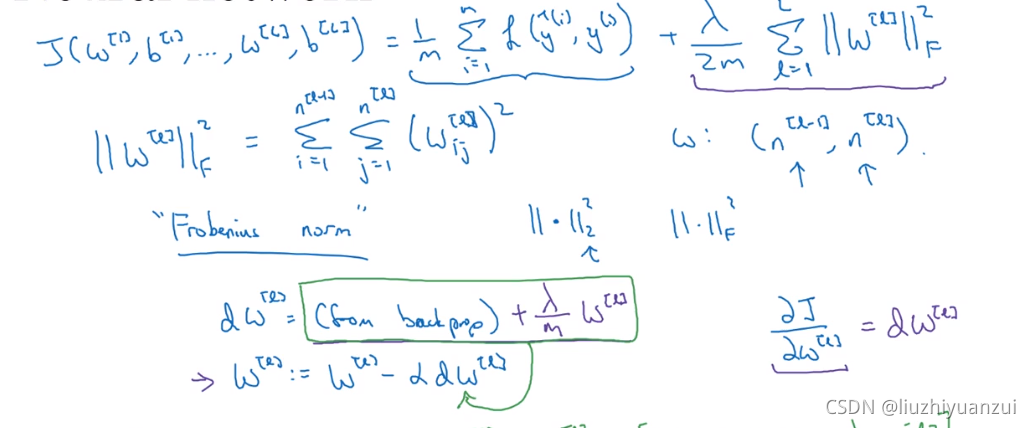
正则化就是在损失函数中加一项,这一项是一个范数,还可以减少方差,然后继续带入到代价函数中去,上述正则化方法叫做L2正则化
加速训练的一个方法是归一化输入:假如输入的两个特征取值不同,一个是0-1,另一个是0-10000,则此时需要归一化
使用softmax回归可以做多个分类器,而不仅仅只能是识别二分类
tensorflow,pytorch是一个深度学习框架
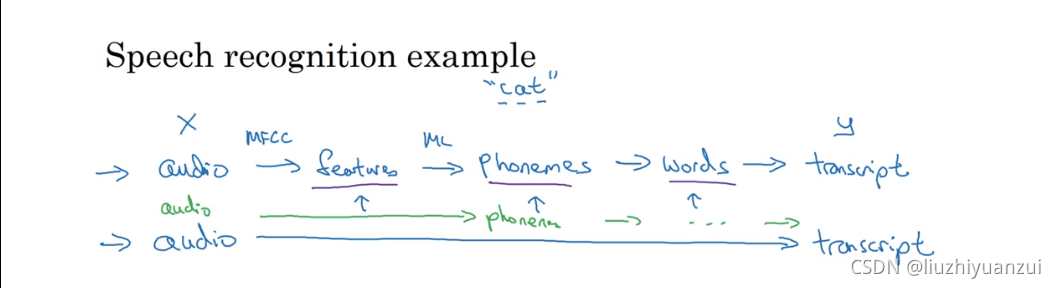
端到端的学习就是输入,然后直接输出,省去了很多中间过程
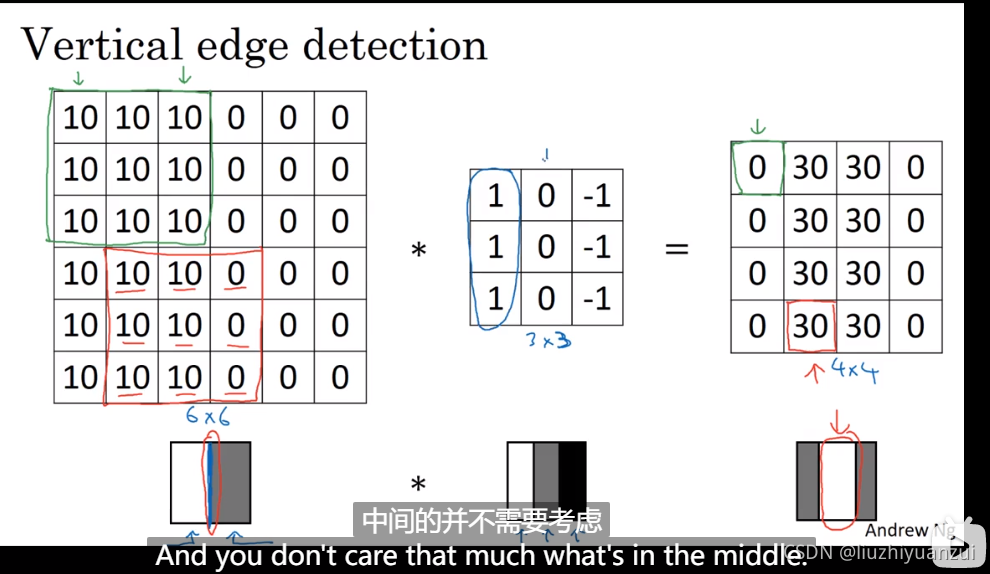
这里是黑白图像的垂直边沿检测,如果数组大一些将会更好的检测到
padding就是在原图像矩阵中填充0
一个nn的图像经过一个ff的卷积核会输出一个n-f+1大小的矩阵,f通常是奇数的
如果加入步长s,p表示padding,则此时的输出层数为(n+29-f)/s+1
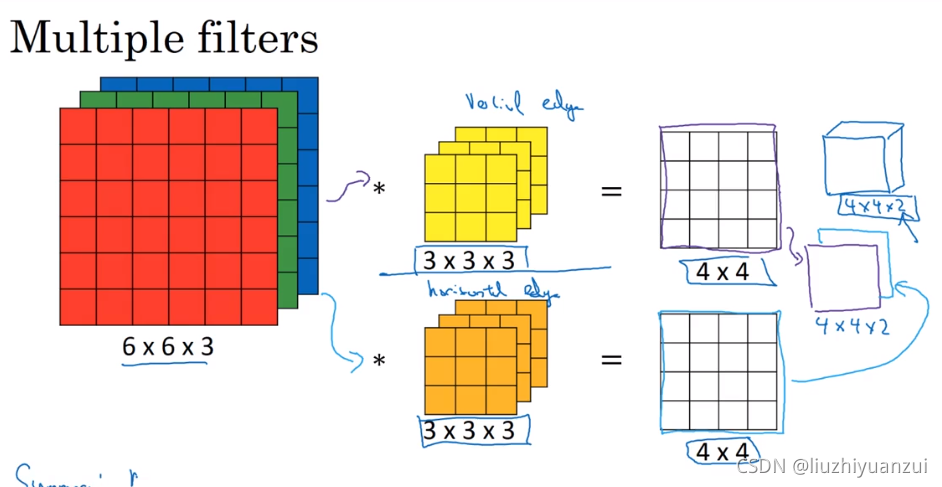
图像的通道数必须和卷积核的通道数匹配
输出图像的维度和有几个卷积核一样,一个卷积核相当于检测一个特征
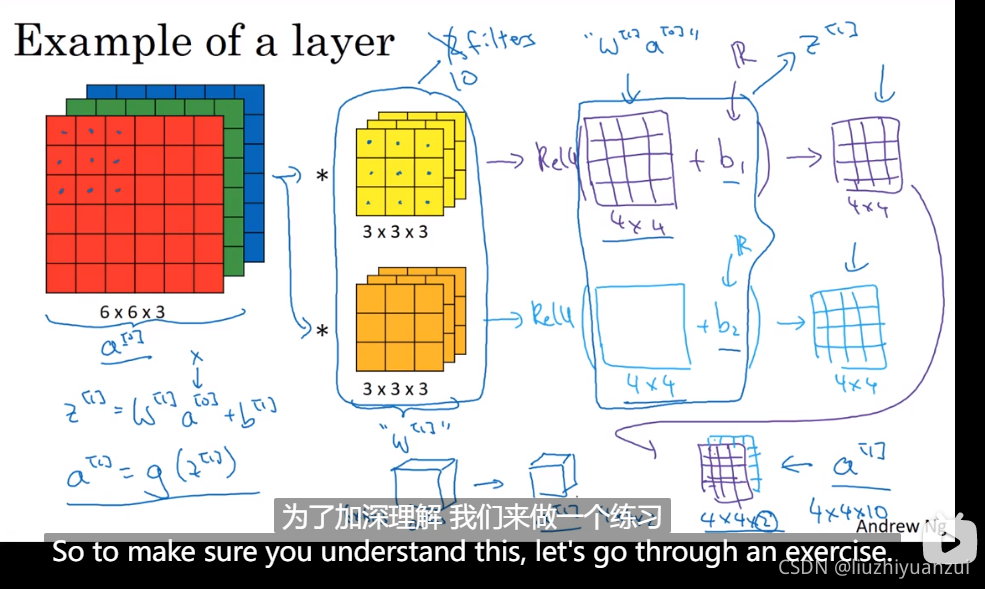
这里阐述了一个663的输入经过一个333的两个卷积核,然后出来了一个442的,对它加上偏差b,再对其整体取激活函数。使其成为神经网络中的一层
计算conv层的输入输出层数在池化层同样适用,池化层有两个超级参数,一个是步长,一个是过滤器大小
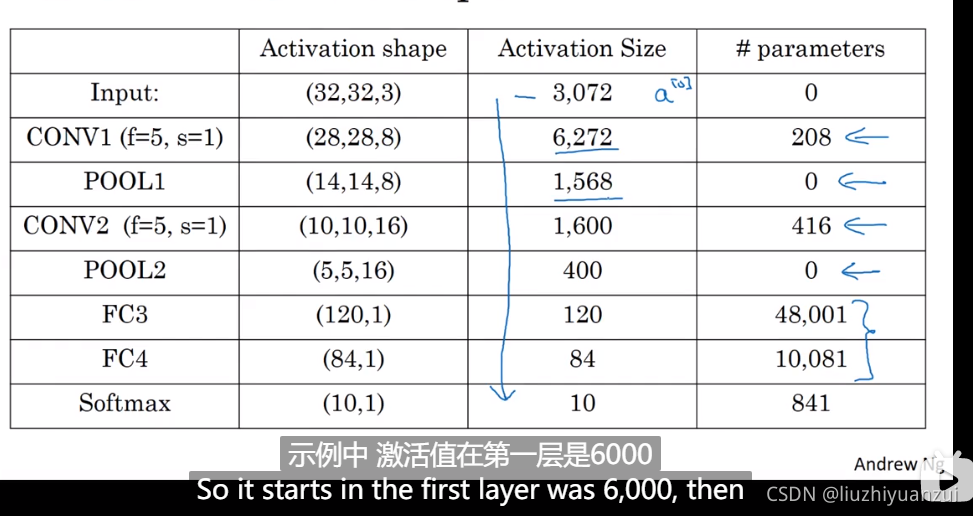
第一列表示激活值的xyz大小的形状,第二列表示激活值的参数,第三列表示参数多少
LeNet-5神经网络
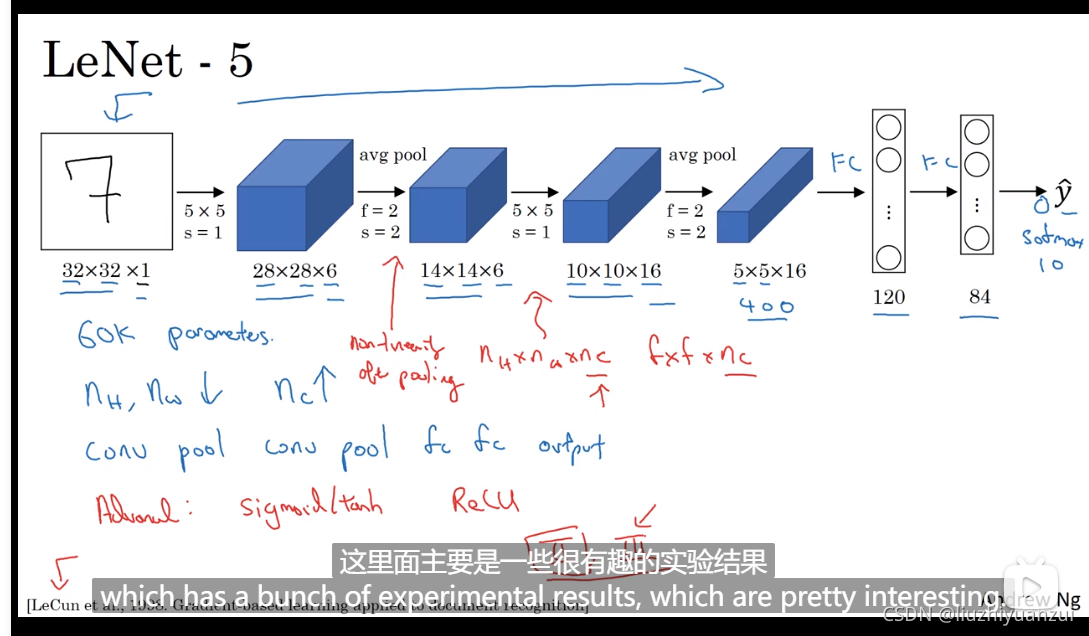
识别数字用的,最后输出一个5516的图像,总共400个参数,将其排列为一列,找出含有120个元素的全连接层,400个参数每一个都对应120,然后送入softmax网络进行分类
inception网络的作用就是替你决定是用多少层的卷积核,是否需要池化层
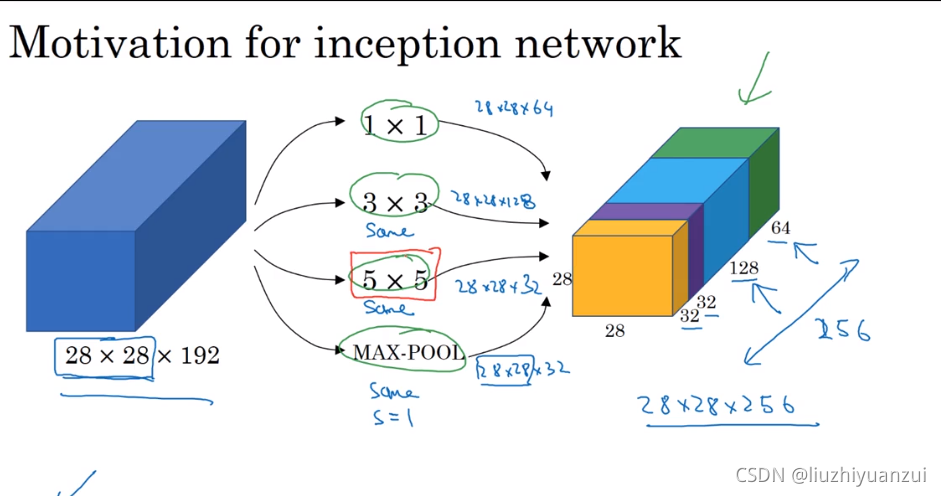
由网络自己决定,需要多少卷积层,多少多少池化层,最后使得输入输出维数不变

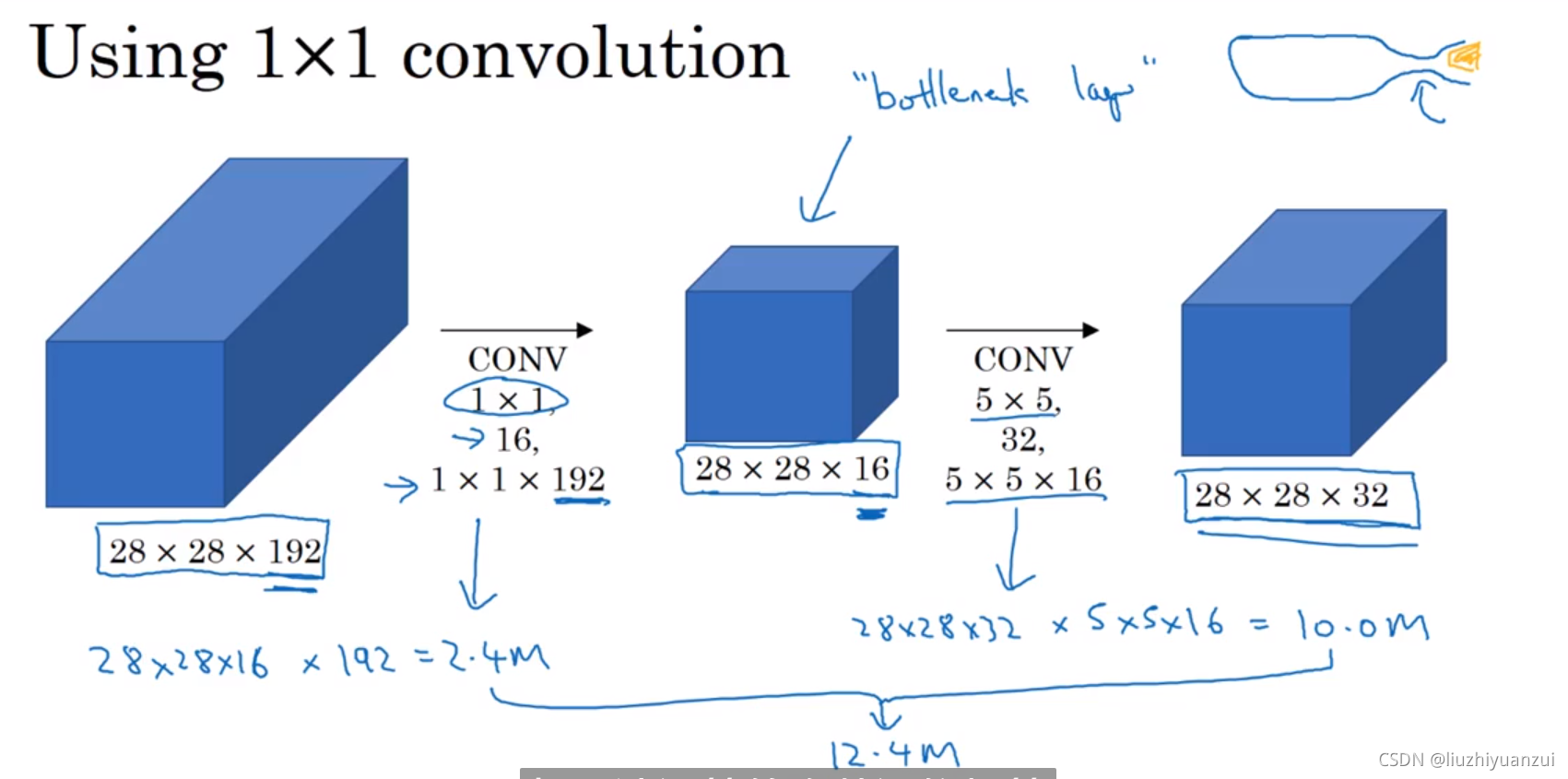
上图总共要进行1.2亿次的计算,而如果使用下面的办法的话只需要进行1200万次计算,节省了十倍
如果数据集较小,我们可以从网上把代码下下来,只改CNN网络中的某一层参数,然后其他层的参数我们可以照搬,如果数据集较大,那么就可以多改几层的参数
数据增强的技巧:将图像进行翻转、对图像进行随机裁剪,再放入数据集当中,
将色彩值进行转化,对RGB的值进行相加R+20 G-20 B+2
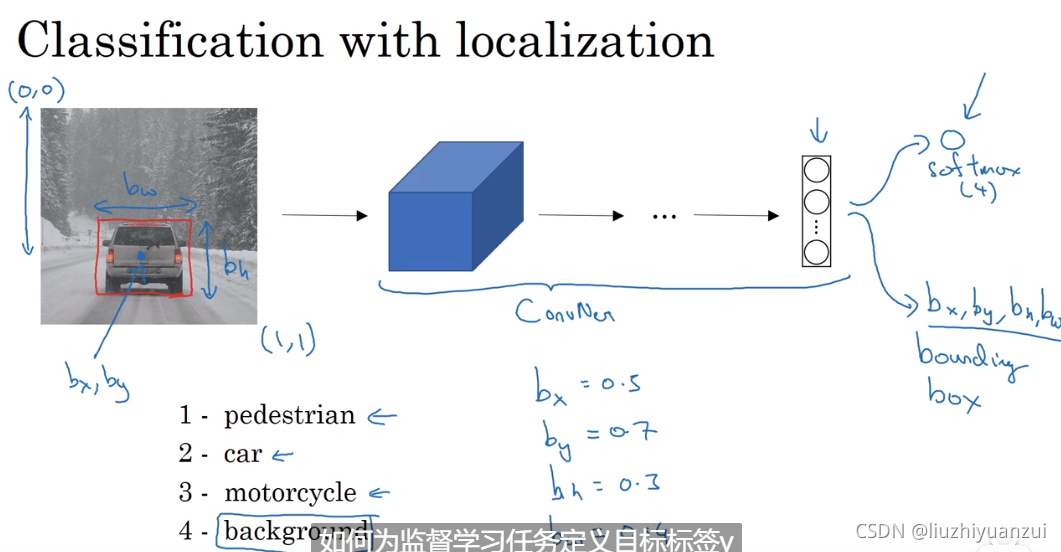
定位就是让softmax多输出四个参数,框框的中心坐标,高和宽
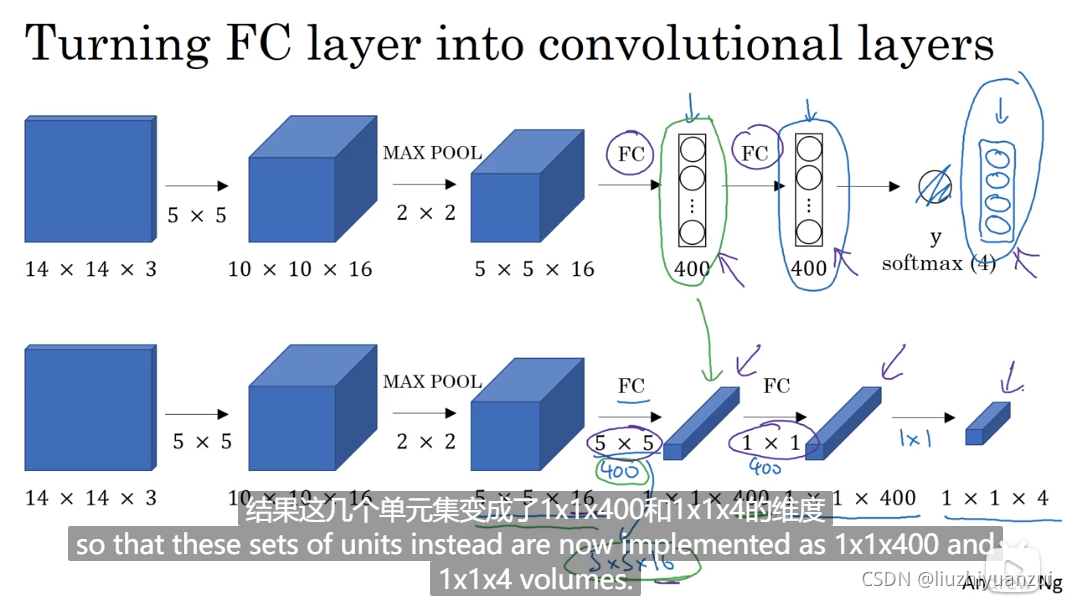
将全连接层转化为卷积的过程,最后的114是softmax分类出来的

交并比,红色的框是我们所定义好的标签,我们预测出的是紫色框,我们要做的就是让训练出来的y^尽可能的接近我们的真实标签y
一般将iou的阈值设备为0.5

做非极大值抑制的时候,对于多个物体类别,我们做多次非极大值抑制
权重初始化
神经网络的训练过程:
1、定义网络的结构,包含输入输出隐藏层
2、初始化权重和偏置
重复以下步骤
3、前向传播,得到预测值
4、计算损失函数,计算预测误差
5、反向传播,更新权重和偏置
直至最小化损失函数,且没有过拟合训练数据,则训练结束
不良的初始化容易造成梯度消失或者梯度爆炸,所以一般是不用从0开始训练一个新模型,可以在类似问题中训练过的模型入手,可以利用大公司设计出的网络架构,将他们的权重参数给保留下来,供我们利用
上采样
在应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(e.g.:图像的语义分割),这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling),我们这里只讨论反卷积。这里指的反卷积,也叫转置卷积,它并不是正向卷积的完全逆过程,用一句话来解释:反卷积是一种特殊的正向卷积,先按照一定的比例通过补 来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。

















 7969
7969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









