







一、需求
表中有1,1.2,1.1.1数据到6.12.222的数据,现需实现根据分隔符“ . ”将其拆分为三段,并进行排序。
二、代码
select TID,(substr(tid,instr(tid,'.',1)+1))
from TEST
ORDER BY to_number(REGEXP_SUBSTR(tid, '[[:alnum:]]+', 1, 1)) NULLS FIRST,
to_number(REGEXP_SUBSTR(tid, '[[:alnum:]]+', 1, 2)) NULLS FIRST,
to_number(REGEXP_SUBSTR(tid, '[[:alnum:]]+', 1, 3)) NULLS FIRST
三、使用的函数
- substr() 取得字符串中指定起始位置和长度的字符串 substr( string, start_position, [ length ] )
- instr() instr函数返回要截取的字符串在源字符串中的位置。返回索引。
语法如下:
instr( string1, string2 [, start_position [, nth_appearance ] ] )
| 参数 | 含义 |
|---|---|
| string1 | 源字符串,查找此字符串中的数据。 |
| string2 | 目标字符串,需要在string1中查找的字符串,如分隔符。 |
| start_position | 代表从string1哪个位置开始查找。可选项,默认为1。 |
| nth_appearance | 代表从第几次出现string2处开始查找。可选项,默认为1。 |
- REGEXP_SUBSTR() R延伸SUBSTR函数的功能,搜索一个正则表达式模式字符串。
语法如下:
REGEXP_SUBSTR(source_char, pattern [, position [, occurrence [, match_parameter ]]])
| 参数 | 含义 |
|---|---|
| source_char | 源字符串,查找此字符串中的数据。 |
| pattern | 正则表达式。 |
| position | 从第几个位置开始正则表达式的查找。 |
| occurrence | 代表从第几个匹配位置开始执行。 |
| match_parameter | 模式选择,i表示不区分大小写,c表示区分大小写等。 |
四、执行结果
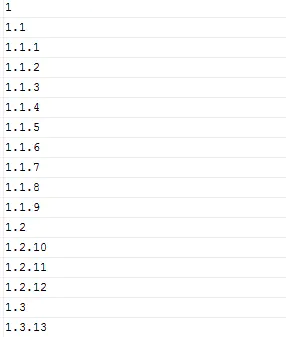
执行结果
作者:jocy_G
链接:https://www.jianshu.com/p/415aca46b575
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









