





离散化可以根据题目的不同要求通过数组,哈希表等多种方式实现
离散化的本质,是映射,将间隔很大的点,映射到相邻的数组元素中。减少对空间的需求,也减少计算量。
以下题为列
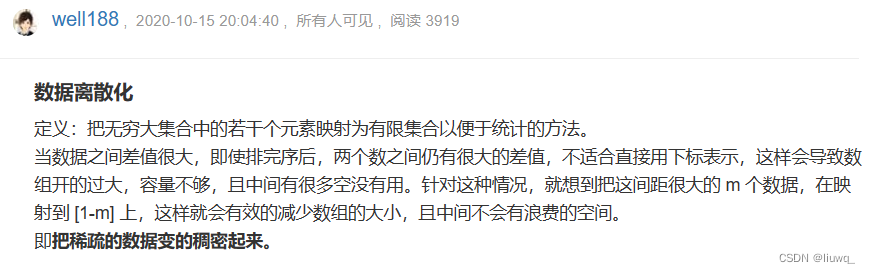
注意关注数据范围
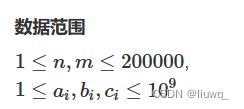
a,b,c的数据范围非常的大高达10^9当其作为数组下标使用时会爆,但是这么大的范围其实只使用了很少一部份(200000),原始的编号过于稀疏,浪费空间,因此我们通过离散化将编号稠密化
#include<bits/stdc++.h>
using namespace std;
const int N=200010;
int n,m;
struct td{
int b,c;
}o[N];
unordered_map<int,int>q;
int main(){
cin>>n;
for(int i=1;i<=n;i++){
int a;
cin>>a;
q[a]++;//每种语言的科学家人数
//此时就是作为数组下标使用了
}
cin>>m;
for(int i=1;i<=m;i++)cin>>o[i].b;
for(int i=1;i<=m;i++)cin>>o[i].c;
int maxb=0,maxc=0,k=1;//如果没有合法方案就会直接输出k所以k需要付初值
for(int i=1;i<=m;i++){
if(q[o[i].b]>maxb){
maxb=q[o[i].b];
k=i;
}
}
for(int i=1;i<=m;i++){
if(maxb==q[o[i].b]){
if(maxc<q[o[i].c]){
maxc=q[o[i].c];
k=i;
}
}
}
cout<<k;
return 0;
}#include <cstdio> #include <algorithm> using namespace std; int n,m,k=0,tot=0; const int N=2e5+50; //3*N是因为语言的来源有3个地方,假设都不相同,则有3*N种语言 int lang[3*N],uni[3*N],a[N],b[N],c[N],ans[3*N]; //find作用是把稀疏编号转为稠密编号 int find(int x){ return lower_bound(uni+1,uni+1+k,x)-uni; } int main(){ //保存科学家会的语言,并用lang记录 scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",&a[i]); lang[++tot]=a[i]; } //保存电影音频的语言,并用lang记录 scanf("%d",&m); for(int i=1;i<=m;i++){ scanf("%d",&b[i]); lang[++tot]=b[i]; } //保存电影字幕的语言,并用lang记录 for(int i=1;i<=m;i++){ scanf("%d",&c[i]); lang[++tot]=c[i]; } //排序lang,为了去重复 sort(lang+1,lang+1+tot); //把lang数组去重复,保存到uni数组 //uni的数组下标做为每种语言(原有的1-10^9的稀疏编号)新的稠密编号 for(int i=1;i<=tot;i++){ if(i==1 || lang[i]!=lang[i-1]){ uni[++k]=lang[i]; } } //a[i]中保存原始的稀疏编号,用find转变成稠密编号,并用ans数组记录每种语言出现的次数。 for(int i=1;i<=n;i++) ans[find(a[i])]++; //此时如果直接将a[i]作为数组下标使用就会爆!!! //遍历所有电影,按要求找到最多科学家会的电影 int ans0,ans1,ans2; //ans0保存最终结果,ans1和ans2为中间结果 ans0=ans1=ans2=0; for(int i=1;i<=m;i++){ //算出第i个电影音频语言的科学家数,和第i个字幕语言的科学家数 int anx=ans[find(b[i])],any=ans[find(c[i])]; //如果ans大于ans1或者前者相等且any大于ans2时,更新 if(anx>ans1 || (anx==ans1 && any>ans2)){ ans0=i,ans1=anx,ans2=any; } } //如果所有的电影的声音和字幕的语言,科学家们都不懂,随便选一个 if(ans0==0){ printf("%d\n",1); }else{ printf("%d\n",ans0); } return 0; } /*作者:well188 链接:https://www.acwing.com/solution/content/22662/ 来源:AcWing 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。*/
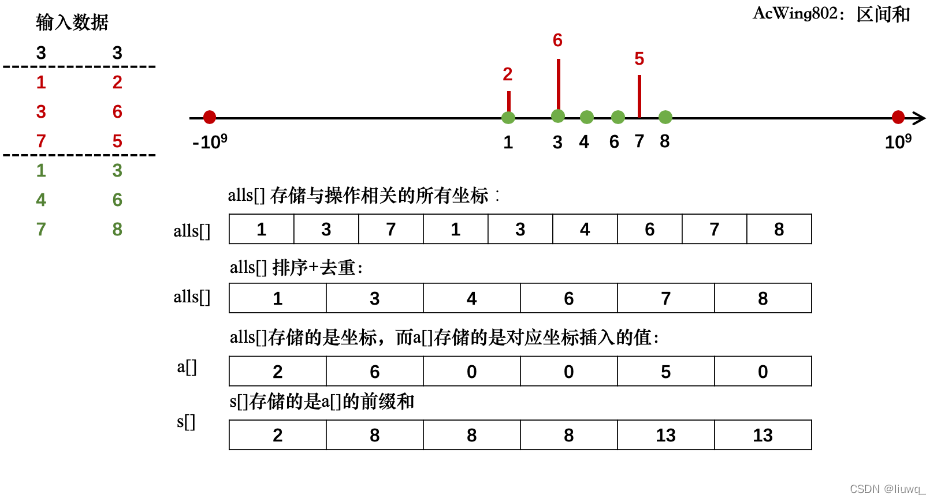
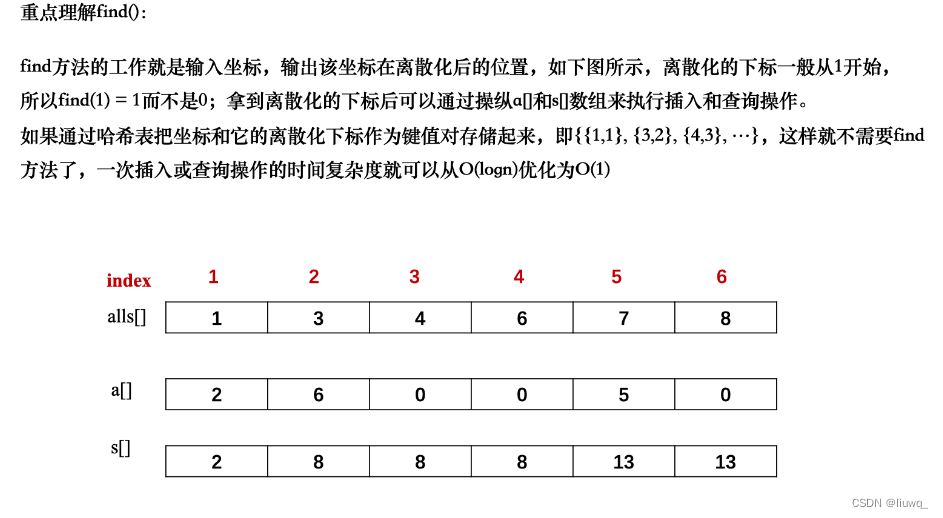
#include<bits/stdc++.h>
using namespace std;
typedef pair<int, int> PII;
const int N = 300010;
int n, m;
int a[N], s[N];
vector<int> alls;
vector<PII> add, query;
int find(int x)
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1;
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ )
{
int x, c;
cin >> x >> c;
add.push_back({x, c});
alls.push_back(x);
}
for (int i = 0; i < m; i ++ )
{
int l, r;
cin >> l >> r;
query.push_back({l, r});
alls.push_back(l);
alls.push_back(r);
}
// 去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
// 处理插入
for (auto item : add)
{
int x = find(item.first);
a[x] += item.second;
}
// 预处理前缀和
for (int i = 1; i <= alls.size(); i ++ ) s[i] = s[i - 1] + a[i];
// 处理询问
for (auto item : query)
{
int l = find(item.first), r = find(item.second);
cout << s[r] - s[l - 1] << endl;
}
return 0;
}


















 8223
8223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









