









阿里巴巴的druid在开源中国上排名靠前,且据说性能评测比常见的dbcp和cp30好。看了看druid的同时正好学习学习数据库连接池。
目录:
1.数据库连接池基本概念
2.几种常见的数据库连接池
3.druid的使用和配置
<!----分割线---->
1.数据库连接池基本概念
数据库连接创建过程:
最原始的数据库操作方式就是jvm加载数据库驱动然后建立连接,在一系列数据库操作之后关闭数据库连接。Java通过JDBC将数据库抽象成为对象,然后对该对象进行操作。数据库是本身存在的,不需要Java进行创建,我们要做的只是将一个正常运行的数据库实例在我们的Java程序中进行访问。
外部程序要被Java访问首先一点,该外部程序要有被Java调用的接口,并且有符合Java命名规则的类名。Java接口就是被JVM控制程序行为的Java驱动器,也就是JDBC。该接口是由数据库厂商提供的,所以类名也是由数据库厂商提供,像MySQL的命名为:com.sql.jdbc.Driver。
forName:
a.当程序运行之后,该接口的类名以及以及句柄会记录到该程序的进程信息中;
b.forName传入该类名之后会到操作系统中找到具有该类名的线程,找到对应的线程就会找到该线程对应的驱动器,然后就将该驱动器加载到JVM中;
c.之后就可以在Java程序中通过类名调用该进程的功能。
forName加载完成后会发现这是个数据库类的驱动,之后会进行一些特殊操作。JDBC是用DriverManager类管理数据库驱动,而且DriverManager只用来管理JDBC驱动。加载完成的数据驱动会抽象成Java类型保存在DriverManager的静态变量driver中。JDBC规定,一个Java进程只能有一个JDBC驱动,而且数据库访问也是要先建立连接。
之后DriverManager的静态同步方法getConnection方法利用driver建立与数据库的连接,返回值是一个Connection对象,Java程序通过该对象对数据库进行操作。
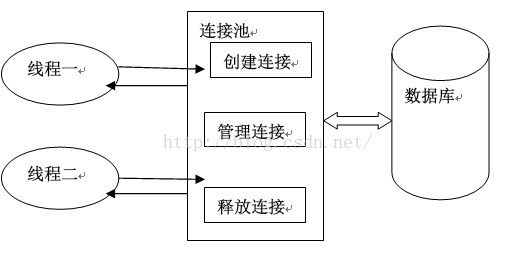
为什么需要数据库连接池:
数据库连接是一种关键的、有限的、昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
我感觉这东西和线程池好像,就像使用线程池实现伪异步io一样主要功能就是复用。
数据库连接池影响因素:
最小连接a--应用启动后随即打开的连接数以及后续最小维持的连接数。
最大连接数b--应用能够使用的最多的连接数
应用程序随着启动会最少维护a个连接,当业务需求的连接数目需要的连接个数大于a,那么jvm就会创建新的连接(当然连接数不会超过b)。加入业务需求的连接数目大于b,那么只能等前面的连接随着事务提交而返回给连接池之后才能复用这些连接。
数据库连接池使用过程:
总之数据库连接池就是提前打开多个数据库连接,避免程序运行期间频繁打开和关闭数据库连接造成的性能损耗。整个过程分为四步:
程序初始化时创建连接池、 使用时向连接池申请可用连接、使用完毕,将连接返还给连接池、 程序退出时,断开所有连接,并释放资源
2.几种常见的数据库连接池
(1)dbcp
简介:dbcp是 apache 上的一个Java连接池项目。特点是包含基本功能且配置简单,没有连接池监控功能,稳定性尚可,据说大并发下面速度稍慢。
配置文件:
| 参数 | 默认值 | 说明 |
| username | \ | 传递给JDBC驱动的用于建立连接的用户名 |
| password | \ | 传递给JDBC驱动的用于建立连接的密码 |
| url | \ | 传递给JDBC驱动的用于建立连接的URL |
| driverClassName | \ | 使用的JDBC驱动的完整有效的Java 类名 |
| initialSize | 0 | 初始化连接:连接池启动时创建的初始化连接数量,1.2版本后支持 |
| maxActive | 8 | 最大活动连接:连接池在同一时间能够分配的最大活动连接的数量, 如果设置为非正数则表示不限制 |
| maxIdle | 8 | 最大空闲连接:连接池中容许保持空闲状态的最大连接数量,超过的空闲连接将被释放, 如果设置为负数表示不限制 |
| minIdle | 0 | 最小空闲连接:连接池中容许保持空闲状态的最小连接数量,低于这个数量将创建新的连接, 如果设置为0则不创建 |
| maxWait | 无限 | 最大等待时间:当没有可用连接时,连接池等待连接被归还的最大时间(以毫秒计数)超过时间则抛出异常,如果设置为-1表示无限等待 |
| testOnReturn | false | 是否在归还到池中前进行检验 |
| testWhileIdle | false | 连接是否被空闲连接回收器(如果有)进行检验.如果检测失败, 则连接将被从池中去除.设置为true后如果要生效,validationQuery参数必须设置为非空字符串 |
| minEvictableIdleTimeMillis | 1000 * 60 * 30 | 连接在池中保持空闲而不被空闲连接回收器线程 (如果有)回收的最小时间值,单位毫秒 |
| numTestsPerEvictionRun | 3 | 在每次空闲连接回收器线程(如果有)运行时检查的连接数量 |
| timeBetweenEvictionRunsMillis | -1 | 在空闲连接回收器线程运行期间休眠的时间值,以毫秒为单位. 如果设置为非正数,则不运行空闲连接回收器线程 |
| validationQuery | null | SQL查询,用来验证从连接池取出的连接,在将连接返回给调用者之前.如果指定, 则查询必须是一个SQL SELECT并且必须返回至少一行记录 |
| testOnBorrow | true | 是否在从池中取出连接前进行检验,如果检验失败, |
(2)cp30
简介:
特点是包含基本功能且配置简单,没有连接池监控功能,稳定性尚可,据说大并发下面稳定性有一定保证。
配置文件:
| 属性(Parameter) | 默认值(Default) | 描述(Description) |
| user |
|
|
| password |
|
|
| jdbcUrl |
|
|
| driverClass |
|
|
| autoCommitOnClose | false | 默认值false表示回滚任何未提交的任务,设置为true则全部提交,而不是在关闭连接之前回滚 (C3P0's default policy is to rollback any uncommitted, pending work. Setting autoCommitOnClose to true causes uncommitted pending work to be committed, rather than rolled back on Connection close.) *参见DBCP中的defaultAutoCommit属性 |
| initialPoolSize | 3 | 初始化连接:连接池启动时创建的初始化连接数量(The initial number of connections that are created when the pool is started. *参见DBCP中的initialSize属性 |
| maxPoolSize | 15 | 连接池中保留的最大连接数(Maximum number of Connections a pool will maintain at any given time.) *参见DBCP中的maxIdle属性 |
| minPoolSize | 3 | 连接池中保留的最小连接数(Minimum number of Connections a pool will maintain at any given time.) *参见DBCP中的maxIdle属性 |
| maxIdleTime | 0 | 最大等待时间:当没有可用连接时,连接池等待连接被归还的最大时间(以秒计数),超过时间则抛出异常,如果设置为0表示无限等待(Seconds a Connection can remain pooled but unused before being discarded. Zero means idle connections never expire.) *参见DBCP中maxWaitMillis 属性 |
| preferredTestQuery | null | 定义所有连接测试都执行的测试语句。在使用连接测试的情况下这个一显著提高测试速度。注意:测试的表必须在初始数据源的时候就存在。(Defines the query that will be executed for all connection tests, if the default ConnectionTester (or some other implementation of QueryConnectionTester, or better yet FullQueryConnectionTester) is being used. Defining a preferredTestQuery that will execute quickly in your database may dramatically speed up Connection tests.) |
| testConnectionOn- Checkin | false | 如果设为true那么在取得连接的同时将校验连接的有效性。(If true, an operation will be performed asynchronously at every connection checkin to verify that the connection is valid. Use in combination with idleConnectionTestPeriod for quite reliable, always asynchronous Connection testing.) *参见DBCP中的testOnBorrow属性 |
| testConnectionOn- Checkout | false | 如果设为true那么在每个connection提交的时候都将校验其有效性,但是要确保配置的preferredTestQuery的有效性(If true, an operation will be performed at every connection checkout to verify that the connection is valid. Be sure to set an efficient preferredTestQuery or automaticTestTable if you set this to true.) *参见DBCP中的testOnBorrow属性 |
| idleConnectionTest- Period | 0 | 如果设置大于0,表示过了多少秒检查一次空闲连接,结合testConnectionOnCheckin以及testConnectionOnCheckout使用(If this is a number greater than 0, c3p0 will test all idle, pooled but unchecked-out connections, every this number of seconds.) |
| acquireRetryAttempts | 30 | 定义在从数据库获取新连接失败后重复尝试的次数, 如果小于0则表示无限制的连接。(Defines how many times c3p0 will try to acquire a new Connection from the database before giving up. If this value is less than or equal to zero, c3p0 will keep trying to fetch a Connection indefinitely.) |
| acquireRetryDelay | 1000 | 两次连接中的间隔时间,单位毫秒。(Milliseconds, time c3p0 will wait between acquire attempts.) |
| breakAfterAcquire- Failure | false | 获取连接失败将会引起所有等待连接池来获取连接的线程抛出异常。但是数据源仍有效保留,并在下次调用 getConnection() 的时候继续尝试获取连接。如果为 true,那么在尝试获取连接失败后该数据源将声明已断开并永久关闭。(If true, a pooled DataSource will declare itself broken and be permanently closed if a Connection cannot be obtained from the database after making acquireRetryAttempts to acquire one. If false, failure to obtain a Connection will cause all Threads waiting for the pool to acquire a Connection to throw an Exception, but the DataSource will remain valid, and will attempt to acquire again following a call to getConnection().) |
| checkoutTimeo据网上测试对比,比目前的DBCP或C3P0数据库连接池性能更好ut | 0 | 当连接池用完时客户端调用 getConnection() 后等待获取新连接的时间,潮湿后将抛出SQLException,如设为0,则为无限期等待。单位毫秒。(The number of milliseconds a client calling getConnection() will wait for a Connection to be checked-in or acquired when the pool is exhausted. Zero means wait indefinitely. Setting any positive value will cause the getConnection() call to time-out and break with an SQLException after the specified number of milliseconds.) |
| maxStatements | 0 | 控制数据源内加载的PreparedStatements数量(Enable prepared statement pooling for this pool.) |
| maxStatementsPer- Connection | 0 | 定义了连接池内单个连接所拥有的最大缓存statements数(The maximum number of open statements that can be allocated from the statement pool at the same time, or negative for no limit.) |
(3)druid
简介:
据网上测试对比,比目前的DBCP或C3P0数据库连接池性能更好。且提供连接池监控功能。
配置文件:
3.druid的详细使用和配置
介绍:
DRUID是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池。
配置参数:
| 配置 | 缺省值 | 说明 |
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this) | |
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
druid整合spring:
-
//application.properties -
jdbc.driverClassName=com.mysql.jdbc.Driver -
jdbc.url=jdbc:mysql://127.0.0.1:3306/test -
jdbc.username=root -
jdbc.password=pword -
<!--分割线--> -
//spring-base.xml -
<?xml version="1.0" encoding="UTF-8"?> -
<beans xmlns=" http://www.springframework.org/schema/beans" -
xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xmlns:batch=" http://www.springframework.org/schema/batch" -
xsi:schemaLocation=" http://www.springframework.org/schema/beans -
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd"> -
<bean id="propertyConfigure" -
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> -
<property name="locations"> -
<list> -
<value>./conf/application.properties</value> -
</list> -
</property> -
</bean> -
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" -
init-method="init" destroy-method="close"> -
<property name="driverClassName" value="${jdbc.driverClassName}" /> -
<property name="url" value="${jdbc.url}" /> -
<property name="username" value="${jdbc.username}" /> -
<property name="password" value="${jdbc.password}" /> -
<!-- 配置初始化大小、最小、最大 --> -
<property name="initialSize" value="1" /> -
<property name="minIdle" value="1" /> -
<property name="maxActive" value="10" /> -
<!-- 配置获取连接等待超时的时间 --> -
<property name="maxWait" value="10000" /> -
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> -
<property name="timeBetweenEvictionRunsMillis" value="60000" /> -
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> -
<property name="minEvictableIdleTimeMillis" value="300000" /> -
<property name="testWhileIdle" value="true" /> -
<!-- 这里建议配置为TRUE,防止取到的连接不可用 --> -
<property name="testOnBorrow" value="true" /> -
<property name="testOnReturn" value="false" /> -
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> -
<property name="poolPreparedStatements" value="true" /> -
<property name="maxPoolPreparedStatementPerConnectionSize" -
value="20" /> -
<!-- 这里配置提交方式,默认就是TRUE,可以不用配置 --> -
<property name="defaultAutoCommit" value="true" /> -
<!-- 验证连接有效与否的SQL,不同的数据配置不同 --> -
<property name="validationQuery" value="select 1 " /> -
<property name="filters" value="stat" /> -
<property name="proxyFilters"> -
<list> -
<ref bean="logFilter" /> -
</list> -
</property> -
</bean> -
<bean id="logFilter" class="com.alibaba.druid.filter.logging.Slf4jLogFilter"> -
<property name="statementExecutableSqlLogEnable" value="false" /> -
</bean> -
</beans>
web监控配置:
-
<servlet> -
<servlet-name>DruidStatView</servlet-name> -
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class> -
</servlet> -
<servlet-mapping> -
<servlet-name>DruidStatView</servlet-name> -
<url-pattern>/druid/*</url-pattern> -
</servlet-mapping> -
<filter> -
<filter-name>druidWebStatFilter</filter-name> -
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> -
<init-param> -
<param-name>exclusions</param-name> -
<param-value>/public/*,*.js,*.css,/druid*,*.jsp,*.swf</param-value> -
</init-param> -
<init-param> -
<param-name>principalSessionName</param-name> -
<param-value>sessionInfo</param-value> -
</init-param> -
<init-param> -
<param-name>profileEnable</param-name> -
<param-value>true</param-value> -
</init-param> -
</filter> -
<filter-mapping> -
<filter-name>druidWebStatFilter</filter-name> -
<url-pattern>/*</url-pattern> -
</filter-mapping>
把上面servlet配置添加到项目web.xml即可。然后运行Tomcat,浏览器输入 http://ip:port/druid
就可以打开Druid的监控页面了.
日志监控配置:
提供了多种日志文件监控 commons-logging、log4j等,这里我们主要使用slf4j和logback来进行日志监控配置
-
//pom.xml -
<slf4j.version>1.7.7</slf4j.version> -
<logback.version>1.1.2</logback.version> -
<dependency> -
<groupId>org.slf4j</groupId> -
<artifactId>slf4j-api</artifactId> -
<version>${slf4j.version}</version> -
</dependency> -
<dependency> -
<groupId>ch.qos.logback</groupId> -
<artifactId>logback-access</artifactId> -
<version>${logback.version}</version> -
</dependency> -
<dependency> -
<groupId>ch.qos.logback</groupId> -
<artifactId>logback-core</artifactId> -
<version>${logback.version}</version> -
</dependency> -
<dependency> -
<groupId>ch.qos.logback</groupId> -
<artifactId>logback-classic</artifactId> -
<version>${logback.version}</version> -
</dependency>
-
//conf/logback.xml -
<configuration> -
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> -
<layout class="ch.qos.logback.classic.PatternLayout"> -
<Pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n -
</Pattern> -
</layout> -
</appender> -
<appender name="FILE" class="ch.qos.logback.core.FileAppender"> -
<file>./logs/druid_info.log</file> -
<layout class="ch.qos.logback.classic.PatternLayout"> -
<Pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</Pattern> -
</layout> -
<filter class="ch.qos.logback.classic.filter.ThresholdFilter"> -
<level>debug</level> -
</filter> -
</appender> -
<root level="DEBUG"> -
<appender-ref ref="FILE" /> -
</root> -
</configuration>
测试类:
-
public class TestMain { -
public static void loadLoggerContext() { -
System.getProperties().put("logback.configurationFile", "./conf/logback.xml"); -
LoggerContext lc = (LoggerContext) LoggerFactory.getILoggerFactory(); -
StatusPrinter.setPrintStream(System.err); -
StatusPrinter.print(lc); -
} -
public static void main(String[] args) { -
try { -
loadLoggerContext(); -
FileSystemXmlApplicationContext context = new FileSystemXmlApplicationContext("./conf/spring-base.xml"); -
} catch (Exception e) { -
System.out.println(e); -
} -
} -
}

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









