




 本文介绍了如何使用Python的Scrapy框架抓取豆瓣电影Top250的数据。首先创建名为'douban'的Scrapy项目,然后定义爬虫目标并制作爬虫,接着设置User-Agent并编写爬虫逻辑。最后通过命令行或启动文件运行爬虫,抓取并存储所需数据。
本文介绍了如何使用Python的Scrapy框架抓取豆瓣电影Top250的数据。首先创建名为'douban'的Scrapy项目,然后定义爬虫目标并制作爬虫,接着设置User-Agent并编写爬虫逻辑。最后通过命令行或启动文件运行爬虫,抓取并存储所需数据。
Python爬虫-利用Scrapy抓取豆瓣电影top250数据
简介
一段自动抓取互联网信息的程序
Python爬虫架构:
- 调度端:用来启动、停止、和监视爬虫
- URL管理:对等待爬取和已经爬取的URL进行管理,简单来说就是为后续模块提供可供爬取的URL
- 网页下载器:将供爬取的URL的网页下载下来,组成供解析的字符串
- 网页解析器:将字符串解析
scrapy抓取步骤:
- 新建项目 (Project) :新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
新建项目(抓取豆瓣电影top250数据)
打开DOM命令窗口,进入D盘(我是把新建项目文件放置在D盘),输入scrapy startproject douban,新建名称为 “douban” 的爬虫项目

开启PyCharm查看新建的爬虫项目

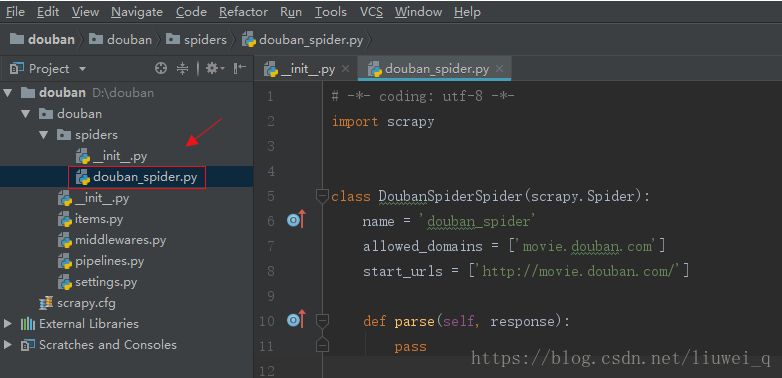
新建spider 爬虫主文件
- 输入命令:cd douban\douban\spiders,进入spiders文件目录下
输入命令:scrapy genspider douban_spider movie.douban.com, 新建名称为“douban_spider”的文件,其中“movie.douban.com”为域名(
douban_spider文件名称可以另取,该文件用于编写XPath和正则表达式)

PyCharm上自动刷新显示新建的爬虫文件
明确目标(明确需要抓取的网页信息)
打开items.py文件,在类 DoubanItem下定义抓
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









