






 在程序中遇到URL错误,发现是由于URL尾部的不间断空格(non-breaking space, nbsp)引起。普通空格ASCII值为32,而不间断空格的ASCII值为160,常由HTML的 产生。这种空格在页面换行时不会被断开。为去除它,可以使用Unicode编码进行替换。解决方案是通过replace方法用Unicode编码' '替换该空格,从而正确清理URL。
在程序中遇到URL错误,发现是由于URL尾部的不间断空格(non-breaking space, nbsp)引起。普通空格ASCII值为32,而不间断空格的ASCII值为160,常由HTML的 产生。这种空格在页面换行时不会被断开。为去除它,可以使用Unicode编码进行替换。解决方案是通过replace方法用Unicode编码' '替换该空格,从而正确清理URL。
背景:
在开发过程中,偶尔会出现程序错误的情况,然后发现是因为在对url进行校验的时候url错误。查看url发现是因为url最后包含了一个空格,但是在最开始的时候已经对url进行前后空格的去除了,为什么还会出现这样的情况呢。
不同的空格是什么?
trim()还有replace()都不能替换掉的空格,这应该就不是一个空格吧,所以先把正常空格和这个“空格”的ascii码打印出来先看一下。
打印出来是这样:
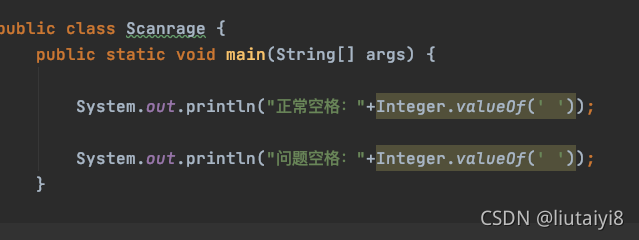
结果:
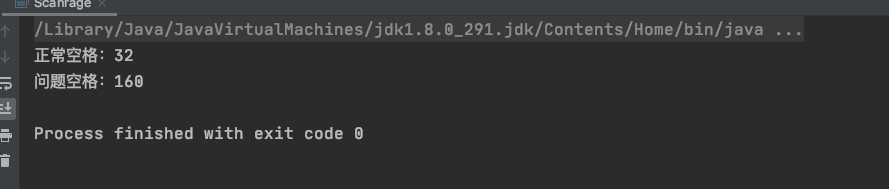
普通空格ascii就是32 那这个160是什么?
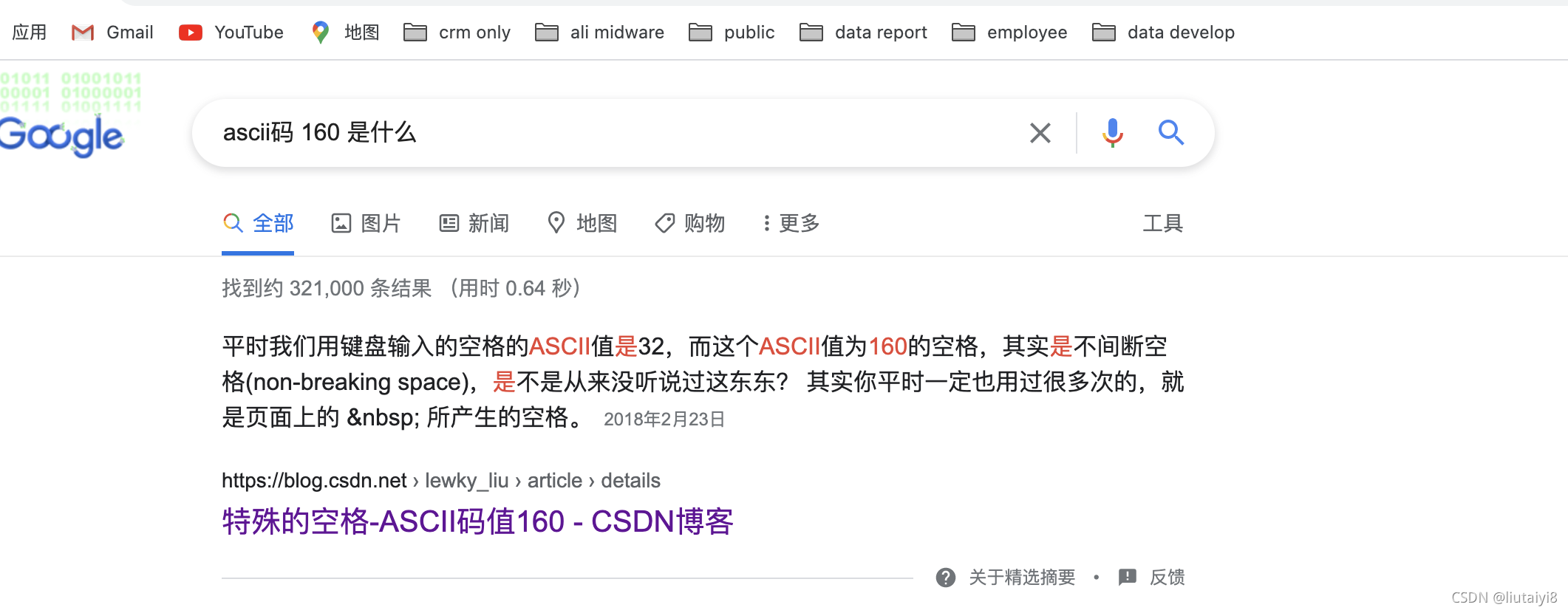
借鉴博客:https://blog.youkuaiyun.com/lewky_liu/article/details/79353151
平时我们用键盘输入的空格的ASCII值是32,而这个ASCII值为160的空格,其实是不间断空格(non-breaking space),是不是从来没听说过这东东?其实你平时一定也用过很多次的,就是页面上的 所产生的空格。
不间断空格non-breaking space的缩写正是nbsp。这中空格的作用就是在页面换行时不被打断,
怎么解决?
不间断空格的unicode编码是:

我们使用unicode编码来进行replace
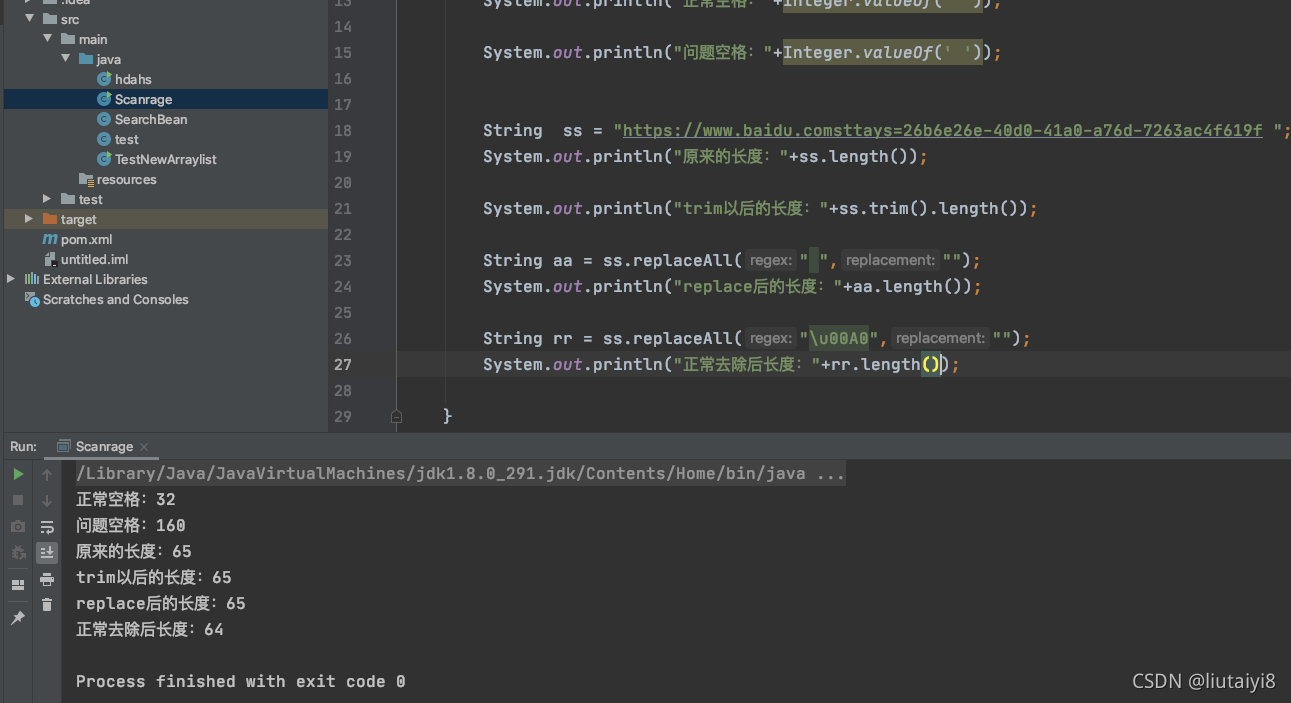
这样就可以正确的把空格去掉了。

















 5539
5539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









