






 本文深入探讨B+树作为数据库索引结构的原因,分析其相较于二叉查找树的优势,以及在MySQL中如何通过B+树实现高效的数据检索。文章详细解释了B+树的特性,如关键字搜索采用闭合区间、非叶节点不保存数据信息、关键字数据保存在叶子节点及叶子节点间的顺序排列。此外,还介绍了MySQL中MyISAM和InnoDB存储引擎的索引实现方式,以及如何根据数据的离散性和查询需求合理创建索引。
本文深入探讨B+树作为数据库索引结构的原因,分析其相较于二叉查找树的优势,以及在MySQL中如何通过B+树实现高效的数据检索。文章详细解释了B+树的特性,如关键字搜索采用闭合区间、非叶节点不保存数据信息、关键字数据保存在叶子节点及叶子节点间的顺序排列。此外,还介绍了MySQL中MyISAM和InnoDB存储引擎的索引实现方式,以及如何根据数据的离散性和查询需求合理创建索引。
文章目录
只做学习笔记用,不用任何版权
索引
正确 的创建 合适 的索引, 是提升数据库查询性能的
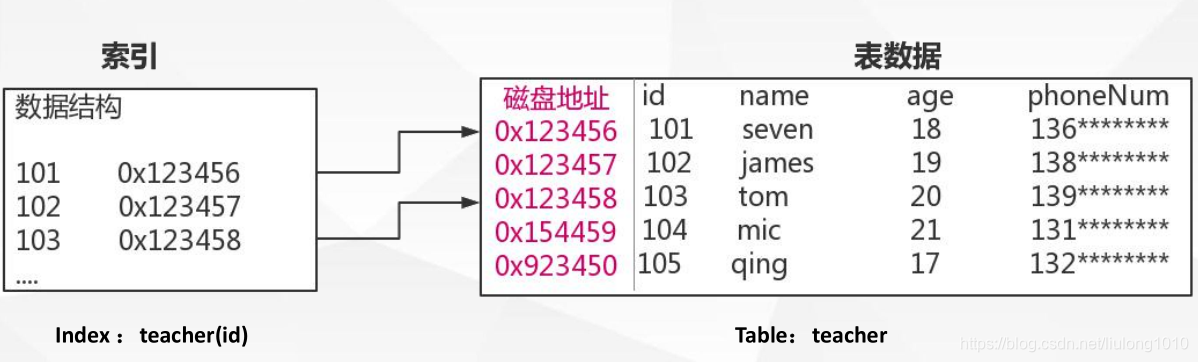
索引是什么?
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
为什么要用索引
- 索引能极大的减少存储引擎需要扫描的数据量
- 索引可以把随机IO变成顺序IO
- 索引可以帮助我们在进行 分组、排序等操作时,避免 使用临时表
为什么是B+Tree?
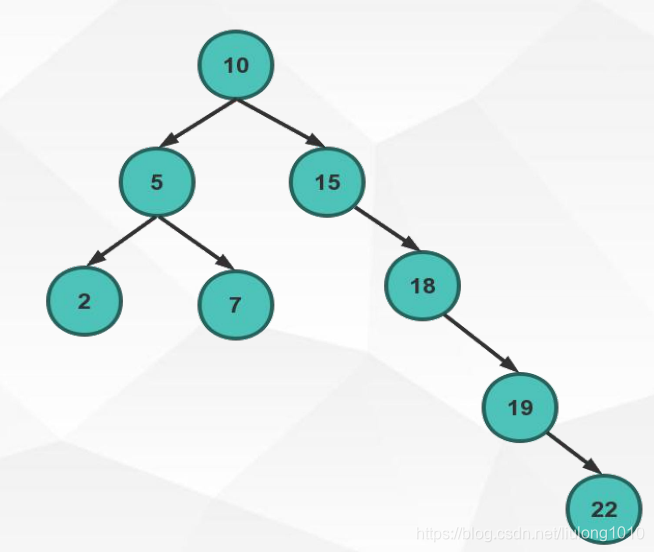
二叉查找树Binary Search Tree
平衡二叉查找树,Balanced binary search tree
问题
- 它太深了
数据处的(高)深度决定着他的IO 操作次数,IO 操作耗时大 - 它太小了
每一个磁盘块 (节点/ 页) 保存的数据量太小 了
没有很好的利用操作磁盘IO的数据交换特性,
也没有利用好磁盘IO 的预读能力(空间局部性原理 ),从而带来频繁的IO
操作系统会一次读取数据一页(16k),同时会缓存相邻的另一页数据
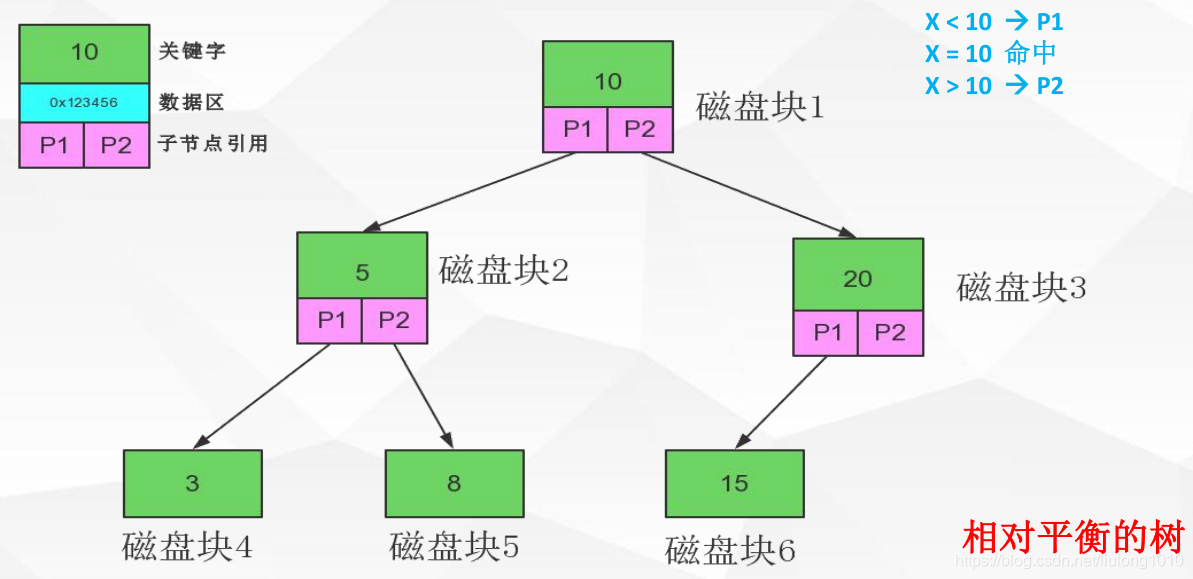
多路平衡查找数,B-Tree
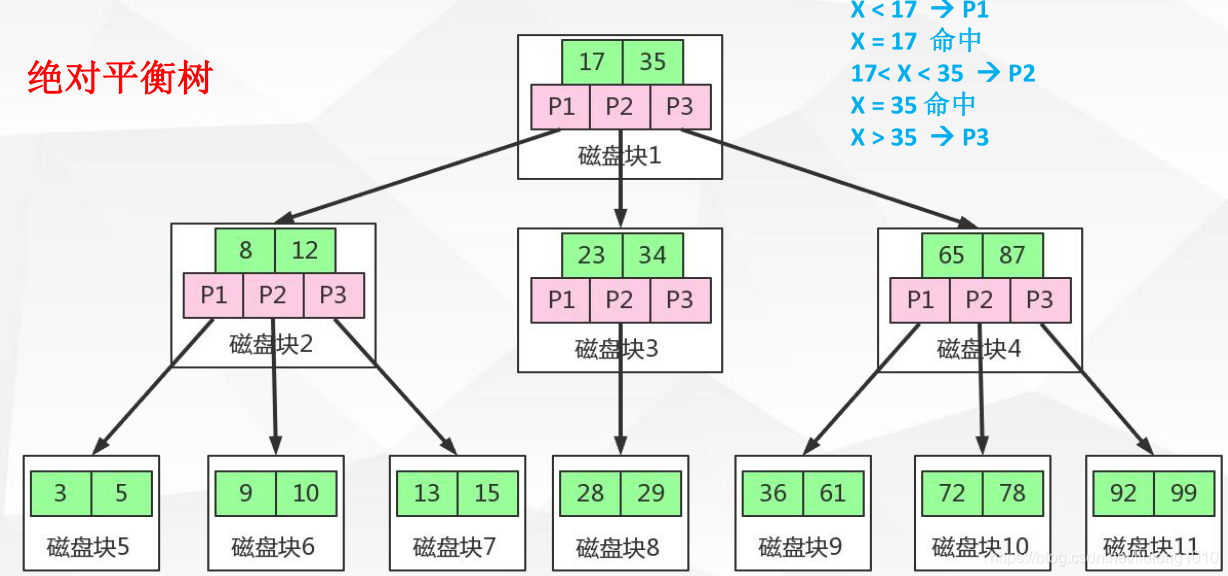
加强版多路平衡查找树B+tree
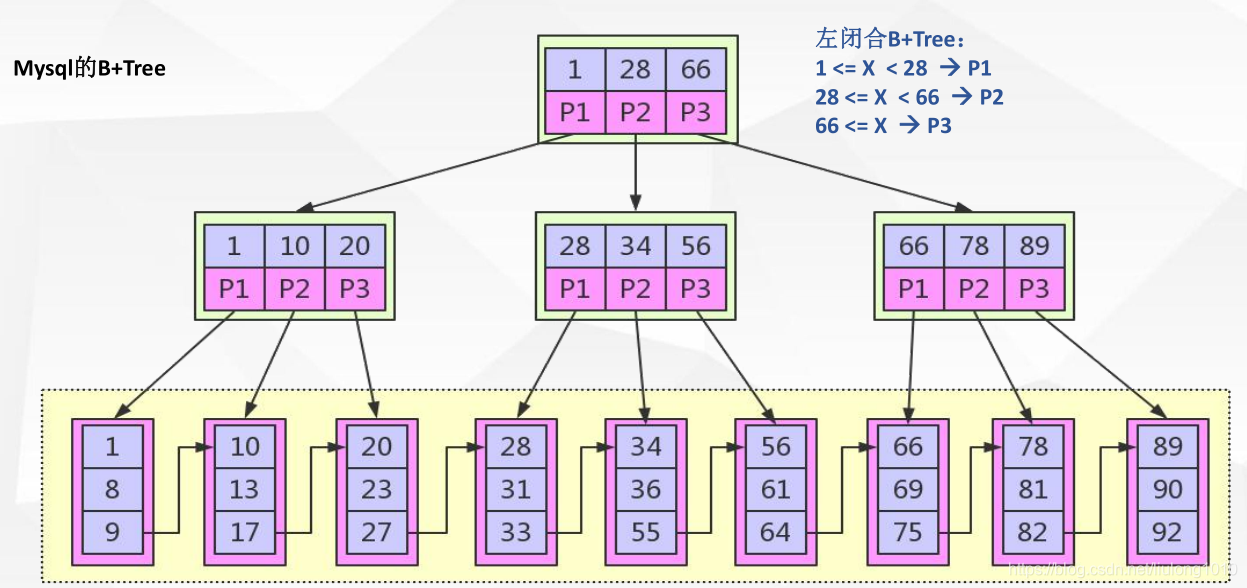
B+Tree与B-Tree的区别
- 1 ,B+ 节点关键字搜索采用闭合区间
- 2 ,B+ 非叶节点不保存数据相关信息,只保存关键字和子节点的引用
- 3 ,B+ 关键字对应的数据保存在叶子节点中
- 4 ,B+ 叶子节点是顺序排列的,并且相邻节点具有顺序引用的关系
B+Tree优点
- B+ 树是B- 树的变种(PLUS 版)多路绝对平衡查找树,他拥有B- 树的优势
- B+ 树扫库、表能力更强
- B+ 树的磁盘读写能力更 强
- B+树 树 的排序能力更强
- B+ 树的查询效率更加 稳定(仁者见仁、智者见智)
Mysql B+Tree 索引体现
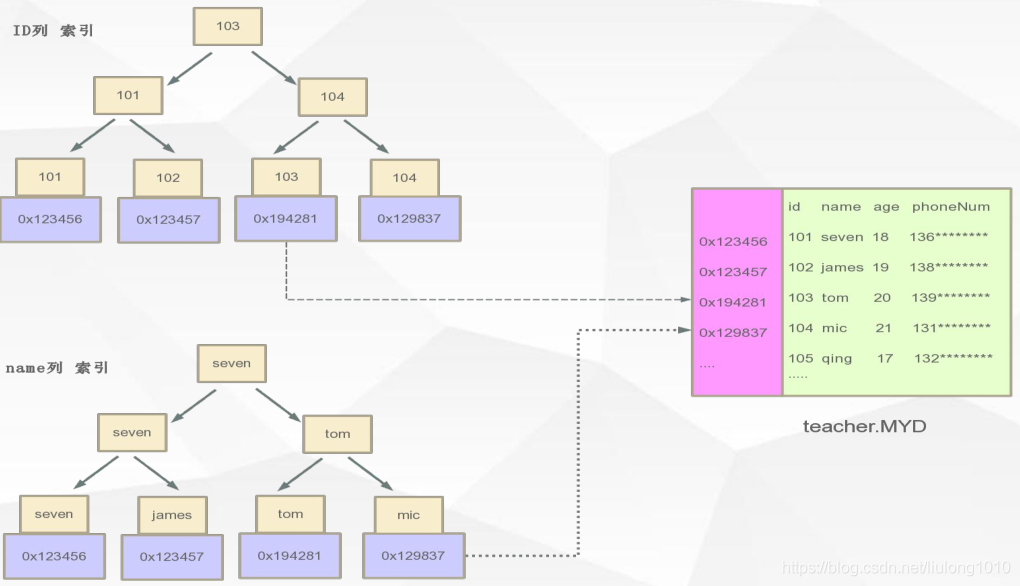
Myisam
索引会单独建立,有两个文件MYI(索引)、MYD(数据文件)
Innodb
以主键为索引来组织数据的存储,辅助索引建立在主键索引上面,一个IBD文件
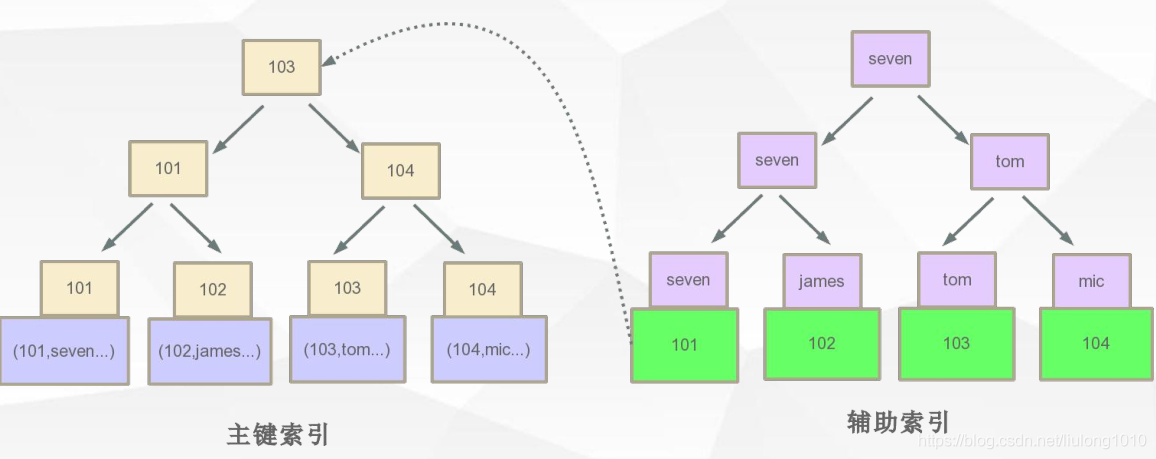
聚集索引
数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同
索引知识点
列的离散型 count(distinct col):count(col)
-
越大离散型越好,离散性越高,选择性就越好
不要用性别做索引,离散性太小会导致全表扫描
最左匹配原则
对索引中关键字进行计算(对比),一定是从左往右依次进行,
且不可跳过
联合索引
单列索引
节点中关键字[name]
联合索引
节点中关键字[name,phoneNum]
单列索引是特殊的联合索引
联合索引列选择原则
- 1 ,经常用的列优先 【 【 最左匹配原则 】
- 2 ,选择性(离散度)高的列 优先 【 离散度高原则 】
- 3 ,宽度小的列 优先 【 最少空间原则 】
案例
经排查发现最常用的sql语句:
Select * from users where name = ? ;
Select * from users where name = ? and phoneNum = ?;
-- 错误解决方案
create index idx_name on users(name);
create index idx_name_phoneNum on users(name,phoneNum);
-- 根据最左匹配原则 name上面建立的索引没有效果
覆盖索引
如果查询列可通过索引节点中的关键字直接返回,则该索引称之为
覆盖索引。
覆盖索引可减少数据库IO,将随机IO变为顺序IO,可提高查询性能
建立索引规则
- 索引列的数据长度能少则少。
- 索引一定不是越多越好,越全越好,一定是建合适的。
- 匹配列前缀可用到索引 like 9999%,like %9999%、like %9999用不到索引;
- Where 条件中 not in 和 <>操作无法使用索引;
- 匹配范围值,order by 也可用到索引;
- 多用指定列查询,只返回自己想到的数据列,少用select *;
- 联合索引中如果不是按照索引最左列开始查找,无法使用索引;
- 联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引;
- 联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









