 策略梯度:深度强化学习的替代方法
策略梯度:深度强化学习的替代方法





疑问
为什么没有第十章:使用强化学习进行股票交易,因为我看了第十章的内容,我觉得首先使用分钟的曲线去学习策略的行为并不是一个很好的行为,其次,我觉得原文中对于bar的使用的state的表示并不够信息量,再次,对于这个股票的数据可能并不适合于我们A 股的分钟策略,我更想做一个日的交易强化的学习的系统,我自己最近在写一些回测的系统,所以可能后续会通过一些新的方案来实现我们的这个强化学习的内容的实现。
策略梯度
原文中讲解了很多策略(选择动作)和价值(Q,V的计算),我们之前学习的走迷宫的例子当时就说到了,策略的收敛是很快的,但是V值的收敛就会慢很多,我们最终想要的是策略,而不是具体的价值函数,因为价值函数算出来还不一定是一个真正的正确的值。
策略分布更适合于随机性的情况,输出的形式很简单,使用动作的概率来表示,输出概率而不是动作的值,可以更加平滑的接受参数的变化时的情况,而且可以选择更多的动作的采样的方法
策略梯度
∇J=E[Q(s,a)∇logπ(a∣s)\nabla J = E[Q(s,a) \nabla log \pi(a|s)∇J=E[Q(s,a)∇logπ(a∣s),这是我们要优化的目标,但是我们既然是策略网络,我们能决定的部分就是后面的π\piπ,换句话说,我们要学习的就是如何通过配置动作的不同的概率值,来让我们的J也就是我们的整体的奖励最高,注意这一章原文中,作者使用的是蒙特卡洛的方法(完整的epsiode),如果大家还有印象,这显然不是唯一的选择
蒙特卡洛的方法的好处是,使用的是真实的奖励函数,我们只需要正确的去执行学习函数就好了,所以我们的目标就是最大化我们的J的值(这个和损失函数有关)
但是因为片段之间的相关性很强,所以可能会有一些其他的问题
reinforcement方法
我们本身就从强化学习过来,这里我就不过多的解释,有时候真的还是觉得自己当时写的前面的Blog很有必要,帮助自己巩固了很多基础的东西
注意PGN使用的的参数其实和之前的一样,但是我们的Q值之前来自于我们的r和目标网络,现在直接使用真实的奖励函数,通过gamma调整后的每一步的值来计算
class PGN(nn.Module):
def __init__(self, input_size, n_actions):
super(PGN, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_size, 128),
nn.ReLU(),
nn.Linear(128, n_actions)
)
def forward(self, x):
return self.net(x)
def calc_qvals(rewards):
res = []
sum_r = 0.0
#从最后一步开始,往前计算每一步的奖励函数 分别等于当前的r和后一步的r*gamma,这是一个迭代的过程。
for r in reversed(rewards):
sum_r *= GAMMA
sum_r += r
res.append(sum_r)
return list(reversed(res))
奖励函数对于强化学习很理解的人可能很明白,深度强化学习的同学我举个例子
假设我们有一个机器人,它要从起点走到终点,途中会获得一些奖励或惩罚。我们用一个列表来表示这个过程中每一步获得的奖励值,比如 rewards = [1, -2, 3, 4]。这意味着:
第一步,机器人获得奖励 1
第二步,机器人受到惩罚 -2
第三步,机器人获得奖励 3
第四步,机器人获得奖励 4
现在,我们需要计算每一步的 Q 值 (Q-value),也就是期望的累积奖励。这个值考虑了当前奖励以及未来可能获得的奖励。
这里我们使用一个折扣因子 GAMMA (通常取值在 0 到 1 之间),它体现了对未来奖励的权重。如果 GAMMA 越接近 1,意味着未来奖励的权重越高;如果 GAMMA 越接近 0,意味着只关注当前奖励。
现在,让我们计算每一步的 Q 值:
第四步的 Q 值为 4 (只有当前奖励)
第三步的 Q 值为 3 + 4 * GAMMA (当前奖励加上折扣后的未来奖励)
第二步的 Q 值为 -2 + (3 + 4 * GAMMA) * GAMMA
第一步的 Q 值为 1 + (-2 + (3 + 4 * GAMMA) * GAMMA) * GAMMA
所以,如果我们设置 GAMMA=0.9,那么根据这个代码计算出的 Q 值列表将是 [1.61, 0.9, 3.87, 4]。
探索
即熵奖励:一种鼓励探索的方法,通过增加动作概率的熵值来提升奖励的额度,换句话说,动作概率越平均,那么这个单独的奖励越高,我们使用的公式为
计算所有的动作的logits,然后通过softmax变成prob,然后prob的log值,因为prob小于1,所以这个奖励永远是正的,
prob_v = F.softmax(logits_v, dim=1)
entropy_v = -(prob_v * log_prob_v).sum(dim=1).mean()
entropy_loss_v = -ENTROPY_BETA * entropy_v
样本相关性
尽量使用多个env来避免一个env导致的样本过于相关的问题,注意到这里使用的蒙特卡洛的方法,需要等到完整的判断以后才能作为一个合适的片段一起学习
源代码
介绍源代码之前,我要帮助大家梳理一下代码的流程,这样可以更好的理解代码
首先创建env,agent,experience,optimizer,这些都是常规操作,然后每次获取firstLast的片段,加入到我们的batch里面,每次尝试pop_reward(判断是否到episode结尾),如果是,那么就会拿到所有的steps和reward的列表,如果batch次数(4),进行一次学习,通过cal计算我们的目标的价值,计算我们的loss函数(最大化我们的奖励),计算我们的熵奖励,进行loss计算和backforward。
最后,学习完毕的net,进行一次prob预测,和我们之前得到的概率进行比较,得到我们的KL散度(类似于查看一下学习的稳定性)
OK,流程梳理完毕,代码如下,大家有不理解的地方可以对着代码慢慢看
net = PGN(env.observation_space.shape[0], env.action_space.n)
print(net)
agent = ptan.agent.PolicyAgent(net, preprocessor=ptan.agent.float32_preprocessor,
apply_softmax=True)
exp_source = ptan.experience.ExperienceSourceFirstLast(
env, agent, gamma=GAMMA, steps_count=REWARD_STEPS)
optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE)
total_rewards = []
step_rewards = []
step_idx = 0
done_episodes = 0
reward_sum = 0.0
bs_smoothed = entropy = l_entropy = l_policy = l_total = None
batch_states, batch_actions, batch_scales = [], [], []
for step_idx, exp in enumerate(exp_source):
reward_sum += exp.reward
baseline = reward_sum / (step_idx + 1)
writer.add_scalar("baseline", baseline, step_idx)
batch_states.append(exp.state)
batch_actions.append(int(exp.action))
batch_scales.append(exp.reward - baseline)
# handle new rewards
new_rewards = exp_source.pop_total_rewards()
if new_rewards:
done_episodes += 1
reward = new_rewards[0]
total_rewards.append(reward)
mean_rewards = float(np.mean(total_rewards[-100:]))
print("%d: reward: %6.2f, mean_100: %6.2f, episodes: %d" % (
step_idx, reward, mean_rewards, done_episodes))
writer.add_scalar("reward", reward, step_idx)
writer.add_scalar("reward_100", mean_rewards, step_idx)
writer.add_scalar("episodes", done_episodes, step_idx)
if mean_rewards > 195:
print("Solved in %d steps and %d episodes!" % (step_idx, done_episodes))
break
if len(batch_states) < BATCH_SIZE:
continue
states_v = torch.FloatTensor(batch_states)
batch_actions_t = torch.LongTensor(batch_actions)
batch_scale_v = torch.FloatTensor(batch_scales)
optimizer.zero_grad()
logits_v = net(states_v)
log_prob_v = F.log_softmax(logits_v, dim=1)
log_prob_actions_v = batch_scale_v * log_prob_v[range(BATCH_SIZE), batch_actions_t]
loss_policy_v = -log_prob_actions_v.mean()
prob_v = F.softmax(logits_v, dim=1)
entropy_v = -(prob_v * log_prob_v).sum(dim=1).mean()
entropy_loss_v = -ENTROPY_BETA * entropy_v
loss_v = loss_policy_v + entropy_loss_v
loss_v.backward()
optimizer.step()
# calc KL-div
new_logits_v = net(states_v)
new_prob_v = F.softmax(new_logits_v, dim=1)
kl_div_v = -((new_prob_v / prob_v).log() * prob_v).sum(dim=1).mean()
writer.add_scalar("kl", kl_div_v.item(), step_idx)
结果
我这边大概是75k的程度学习完毕
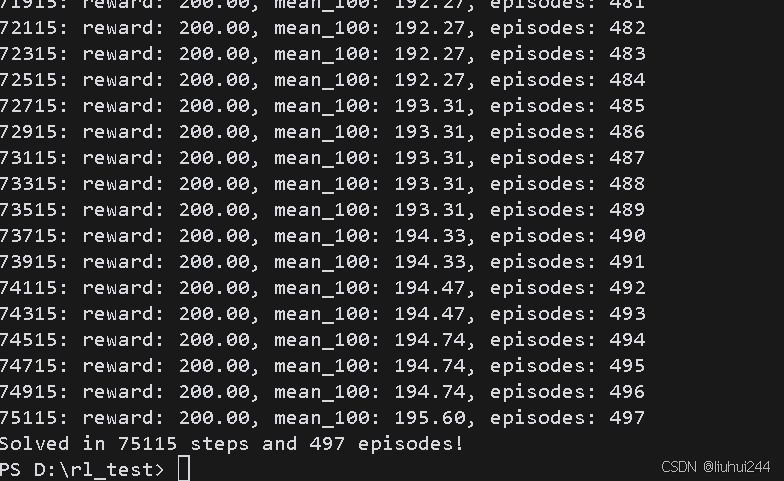
在线策略
这里顺便提一下,为什么是在线策略,因我们的优化的奖励函数和概率是之前的策略的东西,如果你直接学习,那其实是在优化之前的概率的数据,这个显然是不对的,所以我们目前的策略是一个在线的策略,但是如果你有经验的小伙伴就知道我们显然有很多方法把在线的策略变成一个离线的策略。
Pong的策略梯度
这个原来的方法一直在失败,我就不列出来了,更重要的原因是,因为后续会使用A2C的方法来解决这个方法。
但是他的失败的经验很重要,我会把原文的内容坑列出来
- KL曲线出现了大的跳转,表示有很大的概率跳跃
- 超参可能直接是错的
- 初始化敏感,学习不稳定


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









