




 本文深入探讨了浏览器的工作机制,从输入URL开始,详细阐述了DNS解析、TCP连接、HTTP请求的过程,以及HTML解析、CSSOM构建、渲染树生成、布局与绘制的渲染流程。还提到了JavaScript执行对渲染的影响以及浏览器的基本组成。通过理解这些步骤,有助于开发者优化网页性能。
本文深入探讨了浏览器的工作机制,从输入URL开始,详细阐述了DNS解析、TCP连接、HTTP请求的过程,以及HTML解析、CSSOM构建、渲染树生成、布局与绘制的渲染流程。还提到了JavaScript执行对渲染的影响以及浏览器的基本组成。通过理解这些步骤,有助于开发者优化网页性能。
晓看天色暮看云,行也思君,坐也思君。
-------来自女朋友的糖
前言
其实想要深入了解浏览器的运行机制,必须知其原理,否则只是死记硬背。有的小伙伴要说了,原理难道不是背的?可以说有一部分是的,无论是多高深的东西,都是由简单的东西一点一点堆砌起来的,我们要死记硬背的是那些简单的定义,由浅入深了解其原理。而要想理解而不是死记硬背其原理,我们还需要从早期的浏览器研究,因为越早期的就越不完善,看浏览器是怎么一步步优化,理解其优化的原因及其目的,我们也就理解了现在的浏览器机制。
我们先学习一些知识点,为接下来理解浏览器机制做好铺垫。
本来是都要写在本章节里的,但是发现,要陈列的知识点有点多。分章节吧,然后给链接。
流程
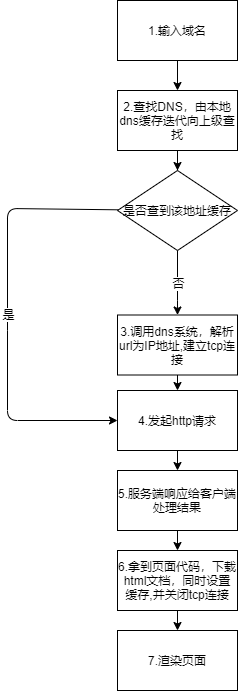
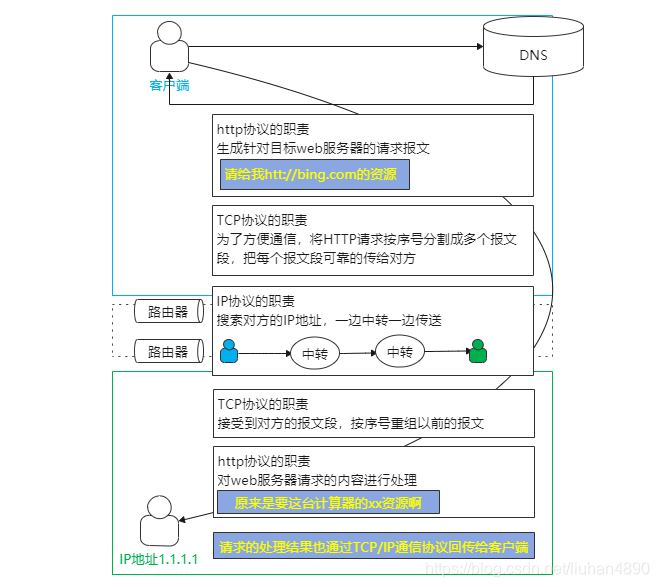
我们根据图再详细的叙述下吧。(中间tcp都做了什么,简单参考职责图)
- 当我们在浏览器中输入一个url,告诉浏览器我们要访问某个域名,比如:http://www.baidu.com。
由于确定具体服务器是需要靠ip地址,因此浏览器会将域名转化为IP地址。具体怎么转化呢?
- 迭代查找每一级dns缓存,如果存在,直接建立tcp连接,发起http请求。详细步骤:
1.查找本地dns缓存,不存在则将域名发送给根域名服务器(查资料说是13台,这个不重要。只需要知道它是最最上层的,相当于户口本的户主)
2.根域名服务器将其匹配的顶级服务器地址(例如com对应的)发送给本地服务器(你的电脑),本地服务器将域名发送给该地址,查找缓存。
3.若没找到,则重复1.2步骤查找二级三级四级域名(域名等级,瞎写个:www.aaa.bbb.com,则www是四级,aaa三级,bbb二级,com顶级。如果是www.aaa.com,则www是三级,aaa是二级,com是顶级)
- 与获得的IP地址建立TCP连接,进行三次握手
- 向该IP地址发起http请求
- 该服务器收到请求后,将处理结果返回给请求方(请求结果404啊,200啊等)
- 获得该服务器的代码,下载HTML文档,同时设置缓存,断开TCP连接,四次挥手。
- 渲染页面
到这里整体流程叙述完了?不,还没有。下载HTML文档,渲染页面的具体还没说呢。先上一段简单的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>渲染流程</title>
<style>
body{
font-size: 12px;
}
p{
font-size: 16px;
}
</style>
</head>
<body>
<div>
<p>渲染p标签</p>
<span>渲染span标签</span>
</div>
</body>
</html>-
第一步,下载HTML文档,生成HTML的DOM Tree
- (具体如何生成DOM Tree,以后会补个连接)。比如代码中的:
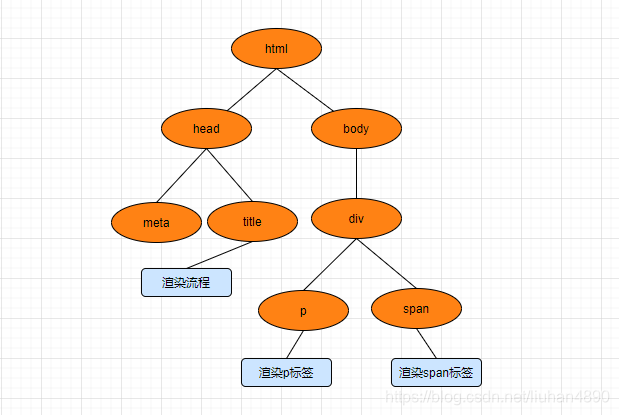
-
第二步,解析CSS,构建CSSOM(CSS Object Model)
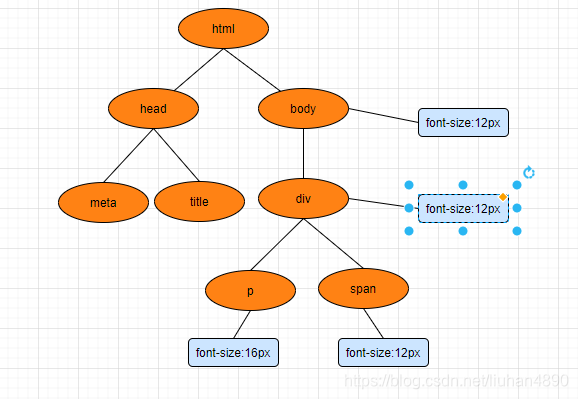
可以看到图中,body字体设置为12px,其子元素会自动级联设置为同样字体大小。这里涉及到了一个通用规则,当你为一个元素计算其最后一个样式时,则该元素的子项应用其全部样式。因此在设置完body的样式后,div、p、span的字体大小都是12px,只有当计算到p元素样式的时候,才会覆盖为16px。应用此方法迭代向下级联,知道计算完最后一个元素为止。
对了,一般的浏览器都有其默认样式,我们写的元素都会覆盖其样式,有的时候没写,而不同浏览器显示的不一样,不仅是对他们的支持不一样,还有可能时默认样式不一样
-
第三步,合并DOM Tree和CSSOM生成Render Tree(渲染树),渲染树只包含页面的所需节点。
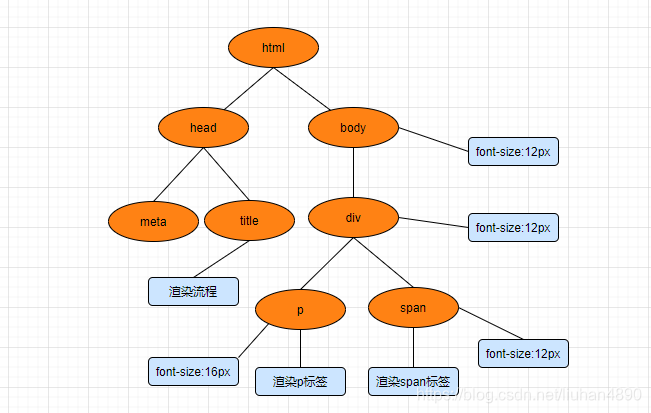
-
第四步,Layout(布局)。根据Render Tree中的信息,计算出每一个元素的大小和位置,将其放在页面中
-
第五步,Paint(绘制),就绘制到屏幕上
渲染的这五步并不是一次性顺序执行完就完了,当DOM和CSS被更改时,会重新执行渲染。那具体阻塞的规则是什么?
- 执行JavaScript脚本会暂停解析DOM,但会预下载相关资源
- 执行CSS会阻塞DOM渲染
- 浏览器遇到script标签,会执行页面渲染(无defer和async),若css资源未加载完成,则等待其完成
我的理解哈,这里的阻塞解析,就是阻塞其继续读取文档;阻塞渲染就是阻塞其构建DOM Tree、CSSOM、Render Tree。
最后上一个浏览器的基本组成,应该也不用多说了,浏览器是并行执行的,并行加载资源。
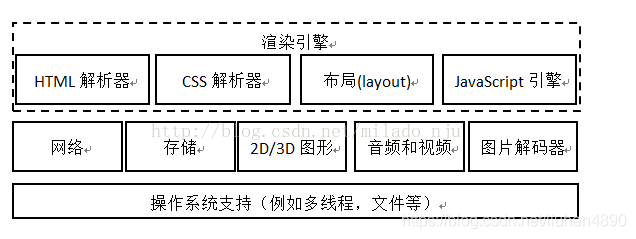
好了,剩余的详细补充(具体的tcp、http,如何构建的DOM Tree、CSSOM,如何合并,如何布局?如何重绘,每一个我们看似简单的步骤,可能都有很多的人或团队付出大量心血)
我们下次再见 ,欢迎指正。求教育啊,各位小伙伴!!!!

















 9653
9653




 到【灌水乐园】发言
到【灌水乐园】发言







