




 本文详细介绍了MongoDB的下载、安装过程,以及如何连接MongoShell。接着,讨论了MongoDB的基本操作,包括数据的添加、查询、更新和删除。此外,还讲解了聚合操作、不同类型的索引(如单键、复合、多键、地理空间和全文索引)及其管理与分析,帮助读者深入理解MongoDB的使用。
本文详细介绍了MongoDB的下载、安装过程,以及如何连接MongoShell。接着,讨论了MongoDB的基本操作,包括数据的添加、查询、更新和删除。此外,还讲解了聚合操作、不同类型的索引(如单键、复合、多键、地理空间和全文索引)及其管理与分析,帮助读者深入理解MongoDB的使用。
第一步,下载步骤
1,网址:https://www.mongodb.com/zh-cn



第二步,安装MongoDB

启动MongoDB

启动异常缺少/data/db

创建一个目录再重新启动(1) mkdir -p /data/db (2)./mongod

另一种启动方式,配置文件启动(常用进程可后台运行)
(1)指定配置⽂件⽅式的启动
./bin/mongod -f mongo.conf
(2)配置⽂件样例:
dbpath=/data/mongo/ //默认地址
port=27017 //启动默认端口号
bind_ip=0.0.0.0 //是不是允许远程访问,四个0不做限制
fork=true //***进程采用后台运行***
logpath = /data/mongo/MongoDB.log //日志路径
logappend = true //是不是追加方式添加日志
auth=false //是否需要安全认证

如果启动有问题,很大可能是dbpath和logpath路径有问题,务必要好好检查
第三步,连接MongoShell(如果连接的不是本机是远程的加个- -host ip》)

Mongodb GUI⼯具(图形化工具)
(1) MongoDB Compass Community
MongoDB Compass Community由MongoDB开发⼈员开发,这意味着更⾼的可靠性和兼容性。它为MongoDB提供GUI mongodb⼯具,以探索数据库交互,具有完整的CRUD功能并提供可视⽅式。借助内置模式可视化,⽤户可以分析⽂档并显示丰富的结构。为了监控服务器的负载,它提供了数据库操作的实时统计信息。就像MongoDB⼀样,Compass也有两个版本,⼀个是Enterprise(付费),社区可以免费使⽤。适⽤于Linux,Mac或Windows。
(2) NoSQLBooster(mongobooster)
NoSQLBooster是MongoDB CLI界⾯中⾮常流⾏的GUI⼯具。它正式名称为MongoBooster。NoSQLBooster是⼀个跨平台,它带有⼀堆mongodb⼯具来管理数据库和监控服务器。这个Mongodb⼯具包括服务器监控⼯具,Visual Explain Plan,查询构建器,SQL查询,ES2017语法⽀持等等…它有免费,个⼈和商业版本,当然,免费版本有⼀些功能限制。NoSQLBooster也可⽤于Windows,MacOS和Linux。
选择自己喜欢的即可:下边以安装NoSQLBooster为例







第四步,MongoDB的基本操作
查看数据库
show dbs;
切换数据库 如果没有对应的数据库则创建
use 数据库名;
创建集合
db.createCollection("集合名")
查看集合
show tables;
show collections;
删除集合
db.集合名.drop();
删除当前数据库
db.dropDatabase();
MongoDB集合数据操作(CURD)
1,数据添加
1. 插⼊单条数据 db.集合名.insert(⽂档)
⽂档的数据结构和JSON基本⼀样。
所有存储在集合中的数据都是BSON格式。
BSON是⼀种类json的⼀种⼆进制形式的存储格式,简称Binary JSON。
2. 例如:
db.lg_resume_preview.insert({name:"张晓峰",birthday:new ISODate("2000-07-
01"),expectSalary:15000,gender:0,city:"bj"})
没有指定 _id 这个字段 系统会⾃动⽣成 当然我们也可以指定 _id
( _id 类型是ObjectId 类型是⼀个12字节 BSON 类型数据,有以下格式:
前4个字节表示时间戳 ObjectId("对象Id字符串").getTimestamp() 来获取
接下来的3个字节是机器标识码
紧接的两个字节由进程id组成(PID)
最后三个字节是随机数。)
3. 插⼊多条数据
db.集合名.insert([⽂档,⽂档])
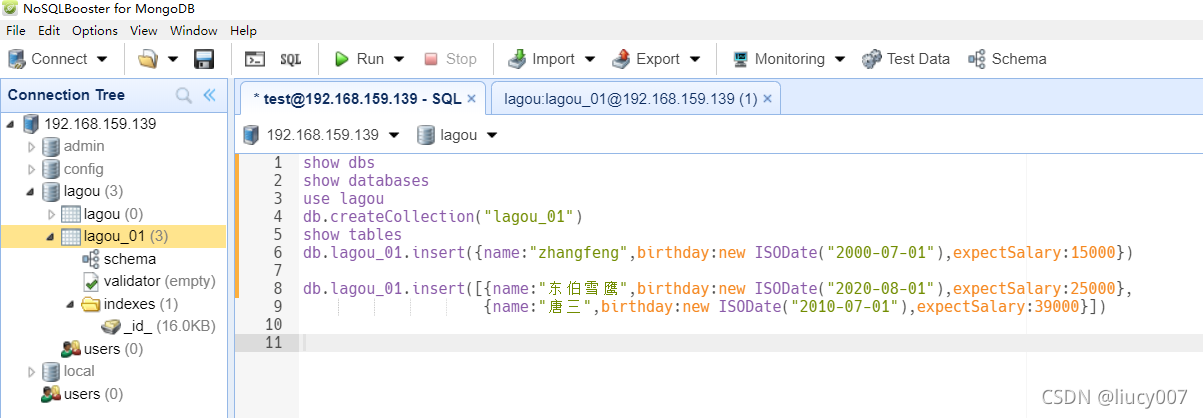
2,数据查询
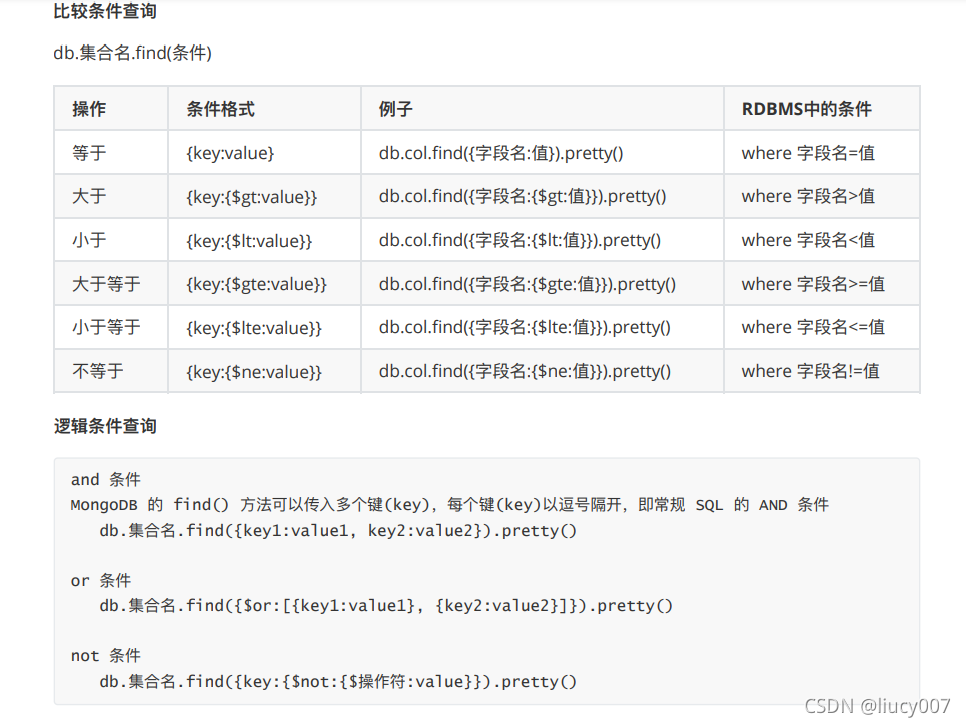
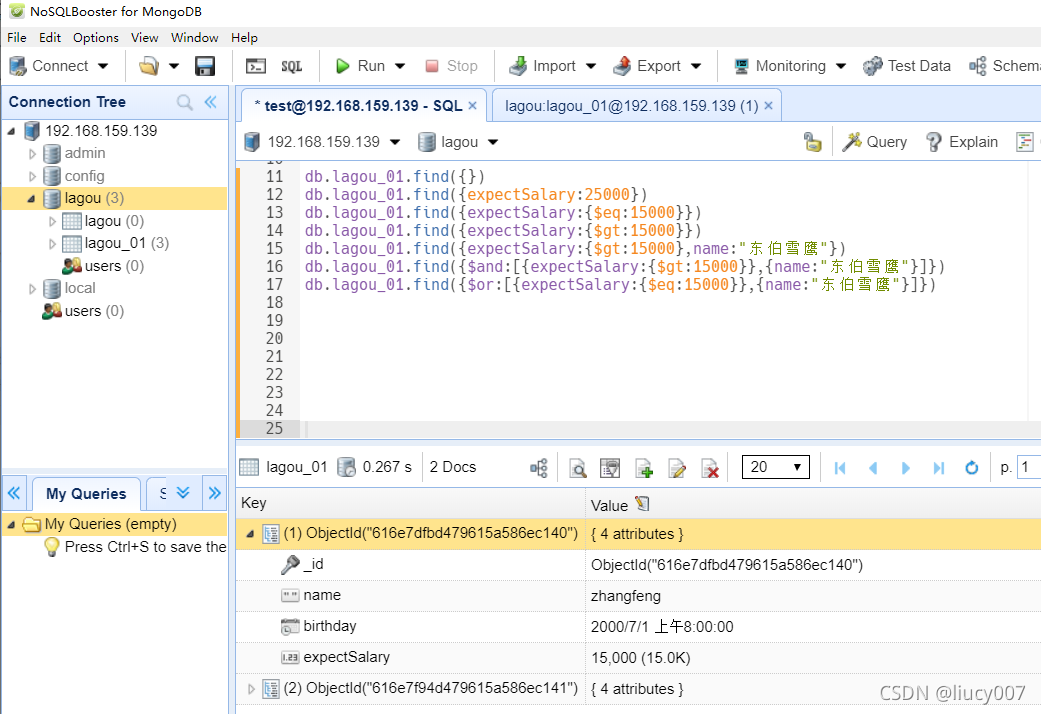
分⻚查询
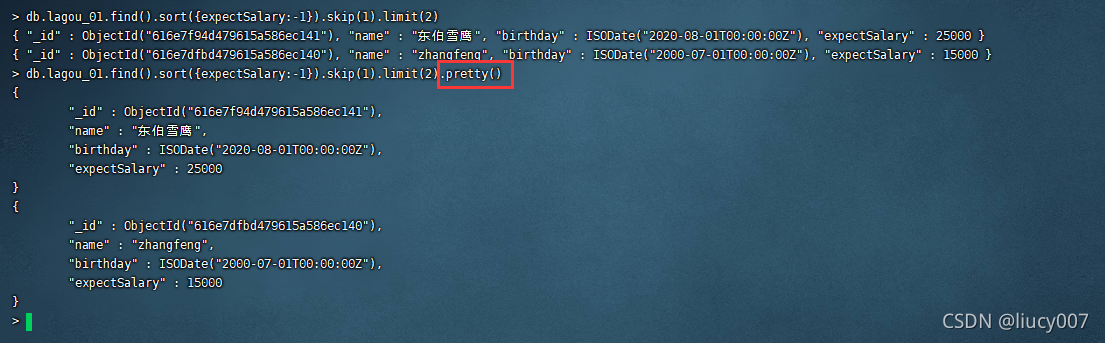
db.集合名.find({条件}).sort({排序字段:排序⽅式})).skip(跳过的⾏数).limit(⼀⻚显示多少数据)
1表示升序,-1表示降序,.pretty()可以改变显示方式
db.lagou_01.find().sort({expectSalary:-1}).skip(1).limit(2)
3,数据更新 调⽤update


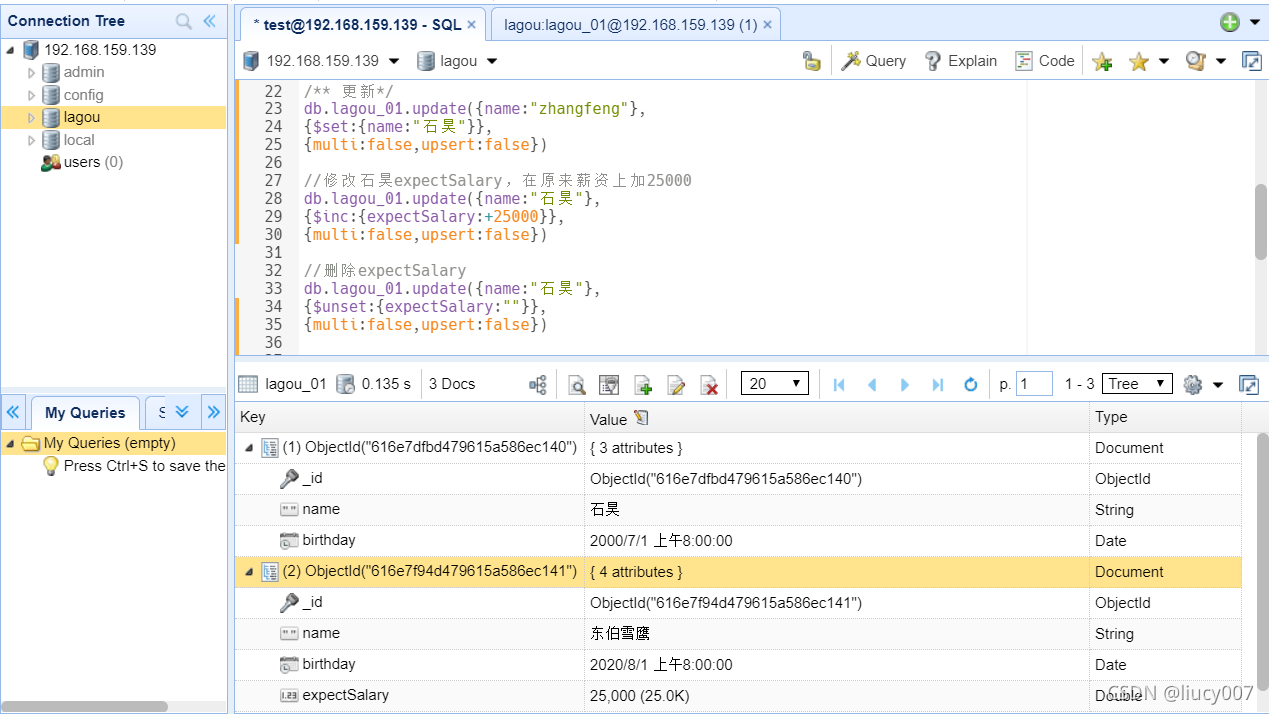
4,数据删除
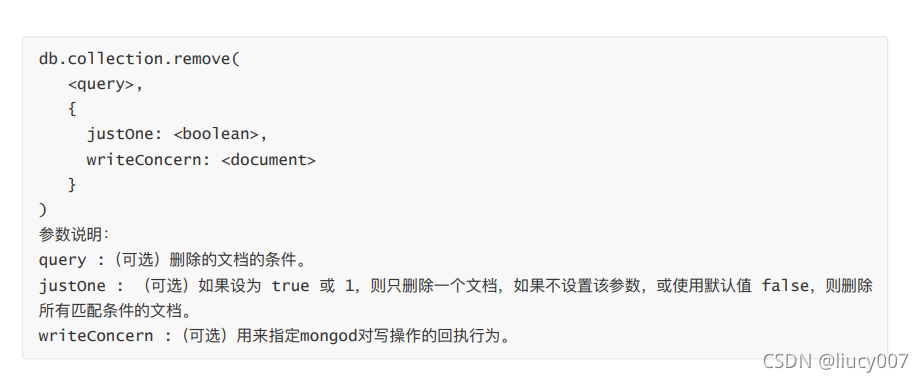
db.lagou_01.remove({expectSalary:{$eq:39000}})
如果命令忘了可以去官网查询
第五步,MongoDB聚合操作
聚合操作简介

聚合操作分类

1,单目的聚合操作

,2,聚合管道(Aggregation Pipeline)
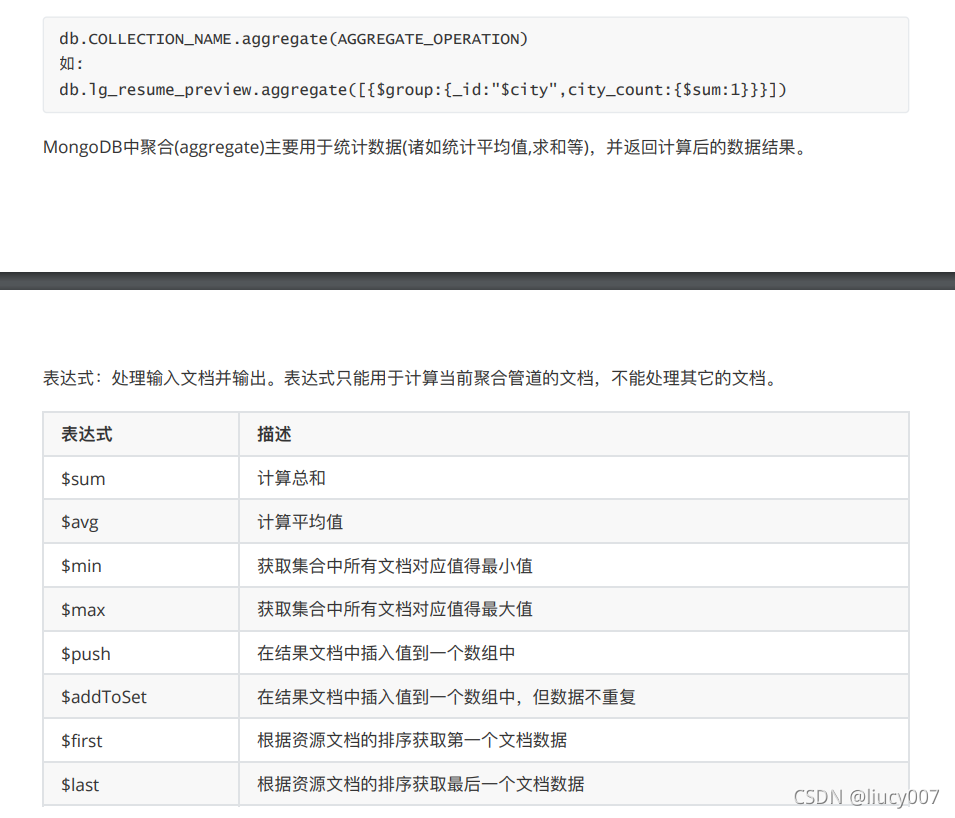
实际操作命令举例
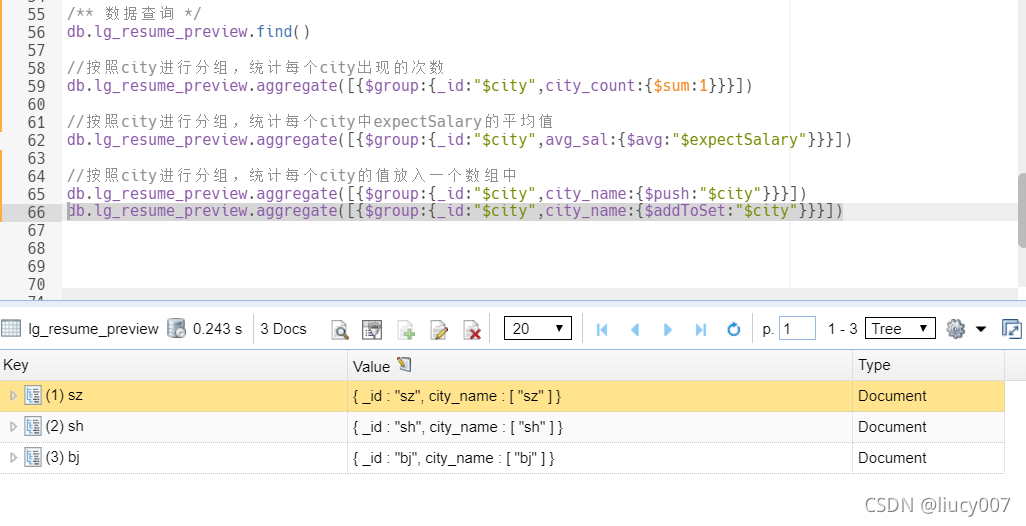

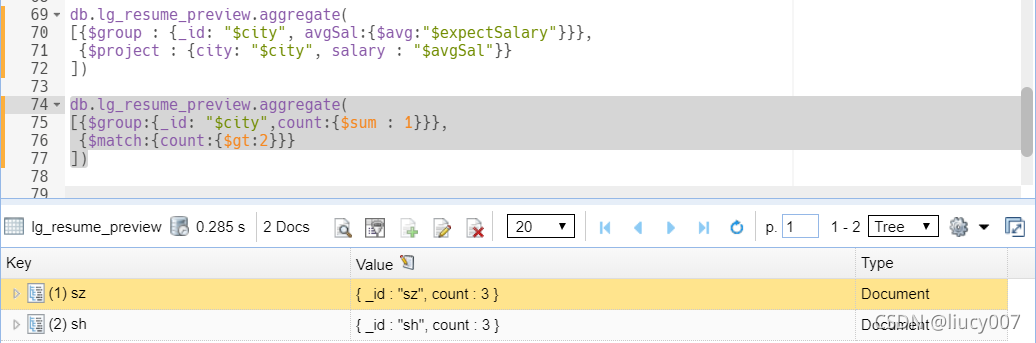
管道把上一步的处理结果交给下一步处理
3, MapReduce 编程模型
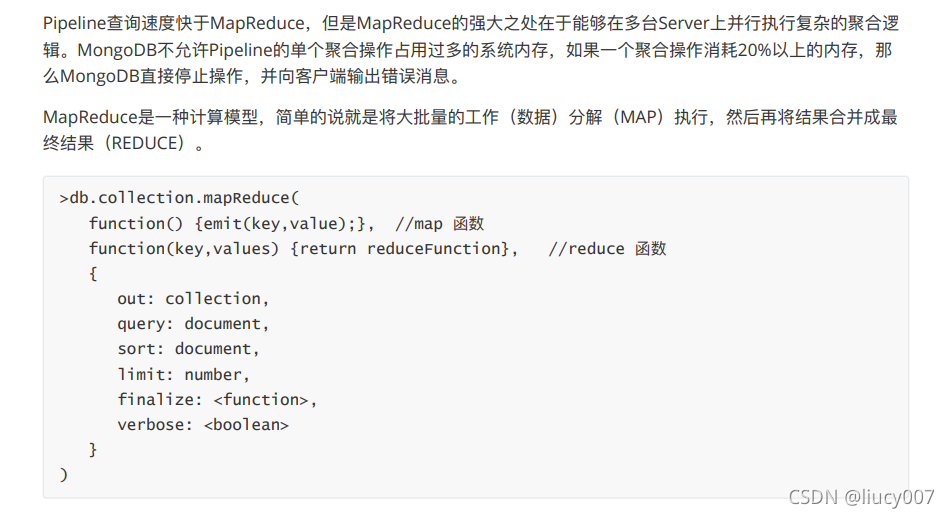

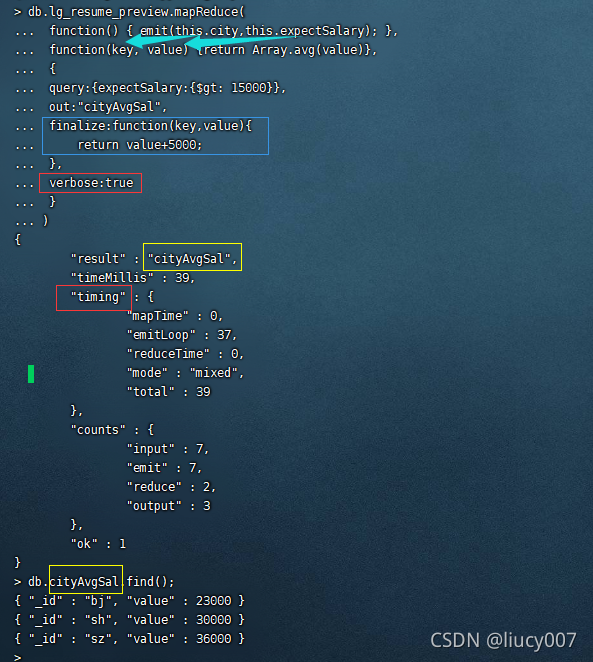
db.lg_resume_preview.mapReduce(
function() { emit(this.city,this.expectSalary); },
function(key, value) {return Array.avg(value)},
{
query:{expectSalary:{$gt: 15000}},
out:"cityAvgSal"
}
)
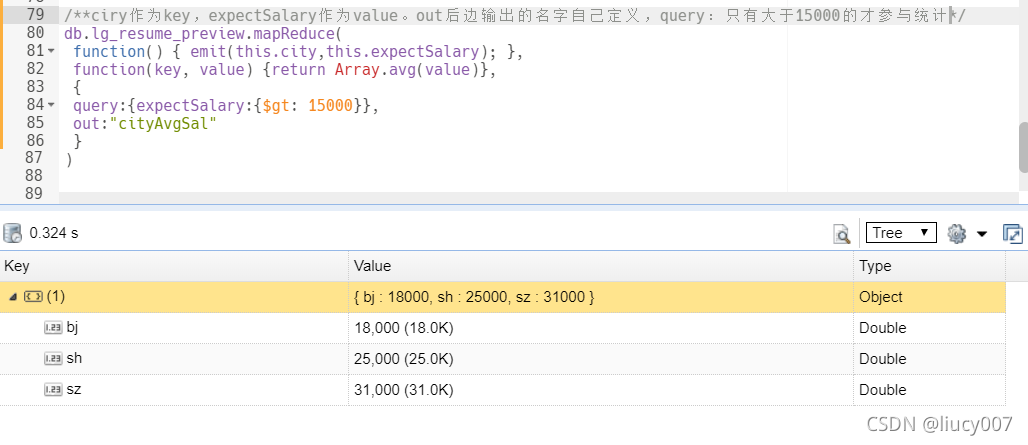
命令行执行
第六,MongoDB索引Index
索引是⼀种单独的、物理的对数据库表中⼀列或多列的值进⾏排序的⼀种存储结构,它是某个表中⼀列或若⼲列值的集合和相应的指向表中物理标识这些值的数据⻚的逻辑指针清单。索引的作⽤相当于图书的⽬录,可以根据⽬录中的⻚码快速找到所需的内容。索引⽬标是提⾼数据库的查询效率,没有索引的话,查询会进⾏全表扫描(scan every document in a collection),数据量⼤时严重降低了查询效率。默认情况下Mongo在⼀个集合(collection)创建时,⾃动地对集合的_id创建了唯⼀索引。
索引类型
1,单键索引 (Single Field)

db.lg_resume_preview.createIndex({name:1}) //给name字段创建索引
db.lg_resume_preview.getIndexes //查看所有索引
,2,复合索引(Compound Index)
通常我们需要在多个字段的基础上搜索表/集合,这是⾮常频繁的。 如果是这种情况,我们可能会考虑在MongoDB中制作复合索引。 复合索引⽀持基于多个字段的索引,这扩展了索引的概念并将它们扩展到索引中的更⼤域。 制作复合索引时要注意的重要事项包括:字段顺序与索引⽅向。
db.集合名.createIndex( { "字段名1" : 排序⽅式, "字段名2" : 排序⽅式 } )
3,多键索引(Multikey indexes)
针对属性包含数组数据的情况,MongoDB⽀持针对数组中每⼀个element创建索引,Multikey indexes⽀持strings,numbers和nested documents
4,地理空间索引(Geospatial Index)
针对地理空间坐标数据创建索引。
2dsphere索引,⽤于存储和查找球⾯上的点
2d索引,⽤于存储和查找平⾯上的点
举例:
db.company.insert(
{
loc : { type: "Point", coordinates: [ 116.482451, 39.914176 ] },
name: "大望路地铁",
category : "Parks"
}
)
db.company.insert(
{
loc : { type: "Point", coordinates: [ 116.492451, 39.934176 ] },
name: "test1",
category : "Parks"
}
)
db.company.insert(
{
loc : { type: "Point", coordinates: [ 116.462451, 39.954176 ] },
name: "test2",
category : "Parks"
}
)
db.company.insert(
{
loc : { type: "Point", coordinates: [ 116.562451, 38.954176 ] },
name: "test3",
category : "Parks"
}
)
db.company.insert(
{
loc : { type: "Point", coordinates: [ 117.562451, 37.954176 ] },
name: "test4",
category : "Parks"
}
)
/**2d是平面点,纯二维的点,所以用2dsphere球面上的点*/
db.company.ensureIndex( { loc : "2dsphere" } )
db.company.getIndexes()
db.company.dropIndexes()
/**给个中心点给个半径*/
db.company.find({
"loc" : {
"$geoWithin" : {
"$center":[[116.482451,39.914176],0.05]
}
}
})
/** 计算中心点最近的三个点 */
db.company.aggregate([
{
$geoNear: {
near: { type: "Point", coordinates: [116.482451,39.914176 ] },
key: "loc",
distanceField: "dist.calculated"
}
},
{ $limit: 3 }
])
5,全⽂索引
MongoDB提供了针对string内容的⽂本查询,Text Index⽀持任意属性值为string或string数组元素的索引查询。注意:⼀个集合仅⽀持最多⼀个Text Index,中⽂分词不理想 推荐ES。
db.集合.createIndex({"字段": "text"})
db.集合.find({"$text": {"$search": "coffee"}})
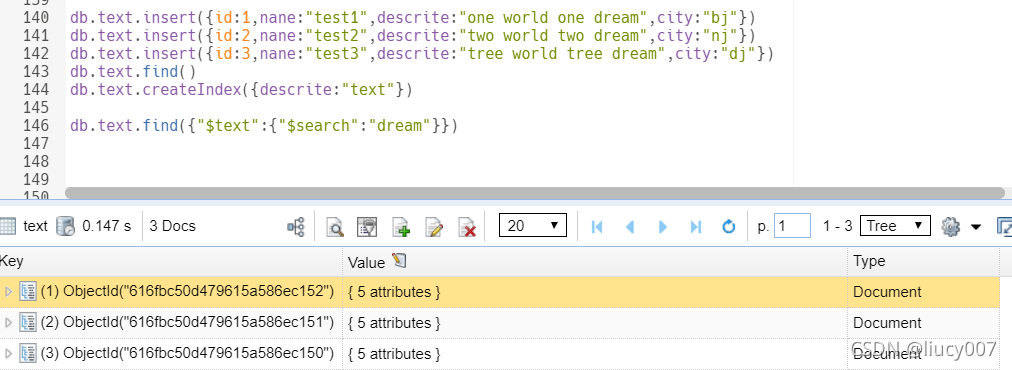
6,哈希索引 Hashed Index
针对属性的哈希值进⾏索引查询,当要使⽤Hashed index时,MongoDB能够⾃动的计算hash值,⽆需程序计算hash值。注:hash index仅⽀持等于查询,不⽀持范围查询。
db.集合.createIndex({"字段": "hashed"})
索引和explain 分析
1 索引管理
创建索引并在后台运⾏
db.COLLECTION_NAME.createIndex({"字段":排序⽅式}, {background: true});
获取针对某个集合的索引
db.COLLECTION_NAME.getIndexes()
索引的⼤⼩
db.COLLECTION_NAME.totalIndexSize()
索引的重建
db.COLLECTION_NAME.reIndex()
索引的删除
db.COLLECTION_NAME.dropIndex("INDEX-NAME")
db.COLLECTION_NAME.dropIndexes()
注意: _id 对应的索引是删除不了的
2,explain 分析
使⽤js循环 插⼊100万条数据 不使⽤索引字段 查询查看执⾏计划 ,然后给某个字段建⽴索引,使⽤索引字段作为查询条件 再查看执⾏计划进⾏分析,explain()也接收不同的参数,通过设置不同参数我们可以查看更详细的查询计划。
queryPlanner:queryPlanner是默认参数,具体执⾏计划信息参考下⾯的表格。
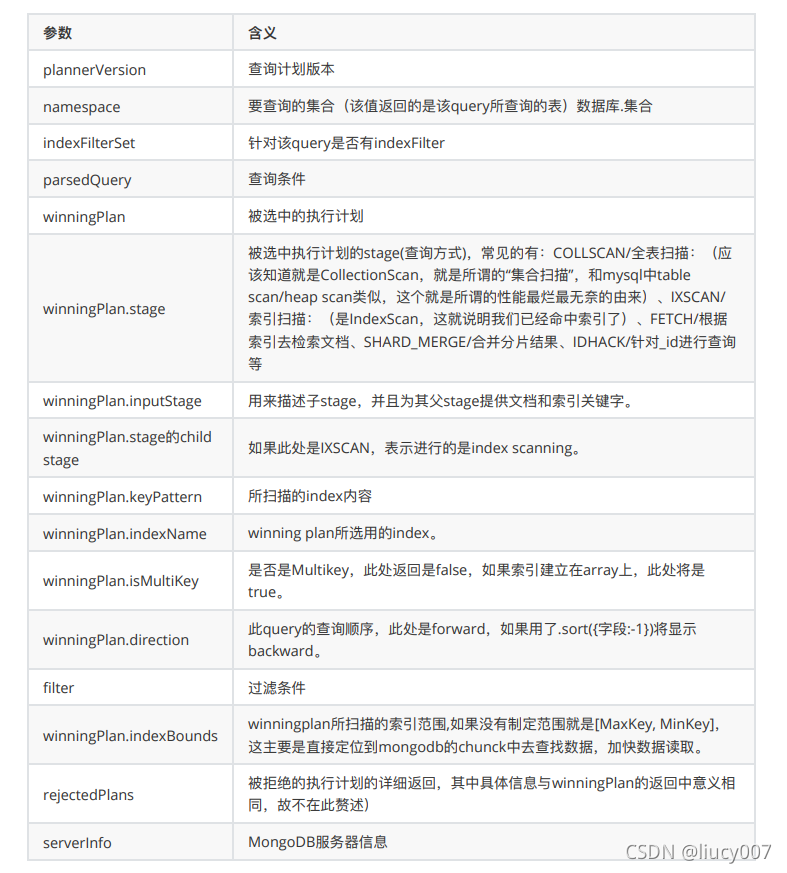
executionStats:executionStats会返回执⾏计划的⼀些统计信息(有些版本中和allPlansExecution等同)。
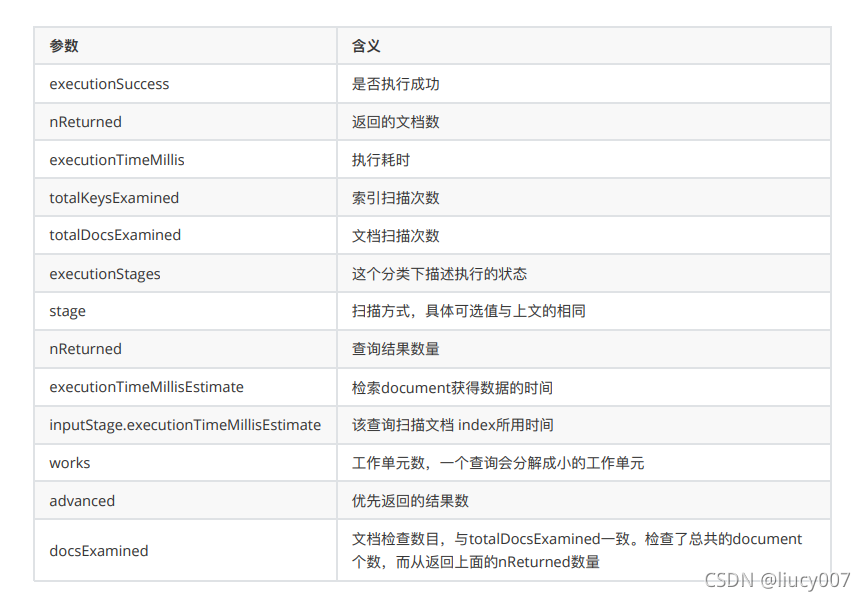
第⼀层,executionTimeMillis最为直观explain返回值是executionTimeMillis值,指的是这条语句的执⾏时间,这个值当然是希望越少越好。
其中有3个executionTimeMillis,分别是:
executionStats.executionTimeMillis 该query的整体查询时间。
executionStats.executionStages.executionTimeMillisEstimate 该查询检索document获得数据的时间。
executionStats.executionStages.inputStage.executionTimeMillisEstimate 该查询扫描⽂档 index所⽤时间。
第⼆层,index与document扫描数与查询返回条⽬数 这个主要讨论3个返回项 nReturned、
totalKeysExamined、totalDocsExamined,分别代表该条查询返回的条⽬、索引扫描条⽬、⽂档扫描条⽬。 这些都是直观地影响到executionTimeMillis,我们需要扫描的越少速度越快。 对于⼀个查询,我们最理想的状态是:
nReturned=totalKeysExamined=totalDocsExamined
第三层,stage状态分析 那么⼜是什么影响到了totalKeysExamined和totalDocsExamined?是stage的类型。
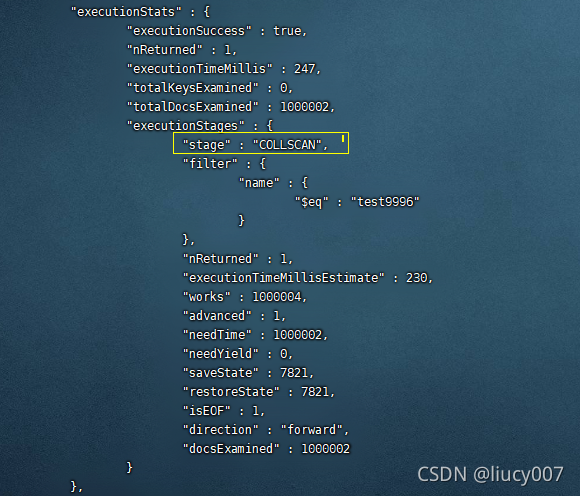
类型列举如下:
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据索引去检索指定document
SHARD_MERGE:将各个分⽚返回数据进⾏merge
SORT:表明在内存中进⾏了排序
LIMIT:使⽤limit限制返回数
SKIP:使⽤skip进⾏跳过
IDHACK:针对_id进⾏查询
SHARDING_FILTER:通过mongos对分⽚数据进⾏查询
COUNT:利⽤db.coll.explain().count()之类进⾏count运算
TEXT:使⽤全⽂索引进⾏查询时候的stage返回
PROJECTION:限定返回字段时候stage的返回
对于普通查询,我希望看到stage的组合(查询的时候尽可能⽤上索引):
Fetch+IDHACK
Fetch+IXSCAN
Limit+(Fetch+IXSCAN)
PROJECTION+IXSCAN
SHARDING_FITER+IXSCAN
不希望看到包含如下的stage:
COLLSCAN(全表扫描)
SORT(使⽤sort但是⽆index)
COUNT 不使⽤index进⾏count)
allPlansExecution: allPlansExecution⽤来获取所有执⾏计划,结果参数基本与上⽂相同。
queryPlanner 参数和executionStats的拼接
慢查询分析
1.开启内置的查询分析器,记录读写操作效率
db.setProfilingLevel(n,m),n的取值可选0,1,2 m表示超过多少时间记录
0表示不记录
1表示记录慢速操作,如果值为1,m必须赋值单位为ms,⽤于定义慢速查询时间的阈值
2表示记录所有的读写操作
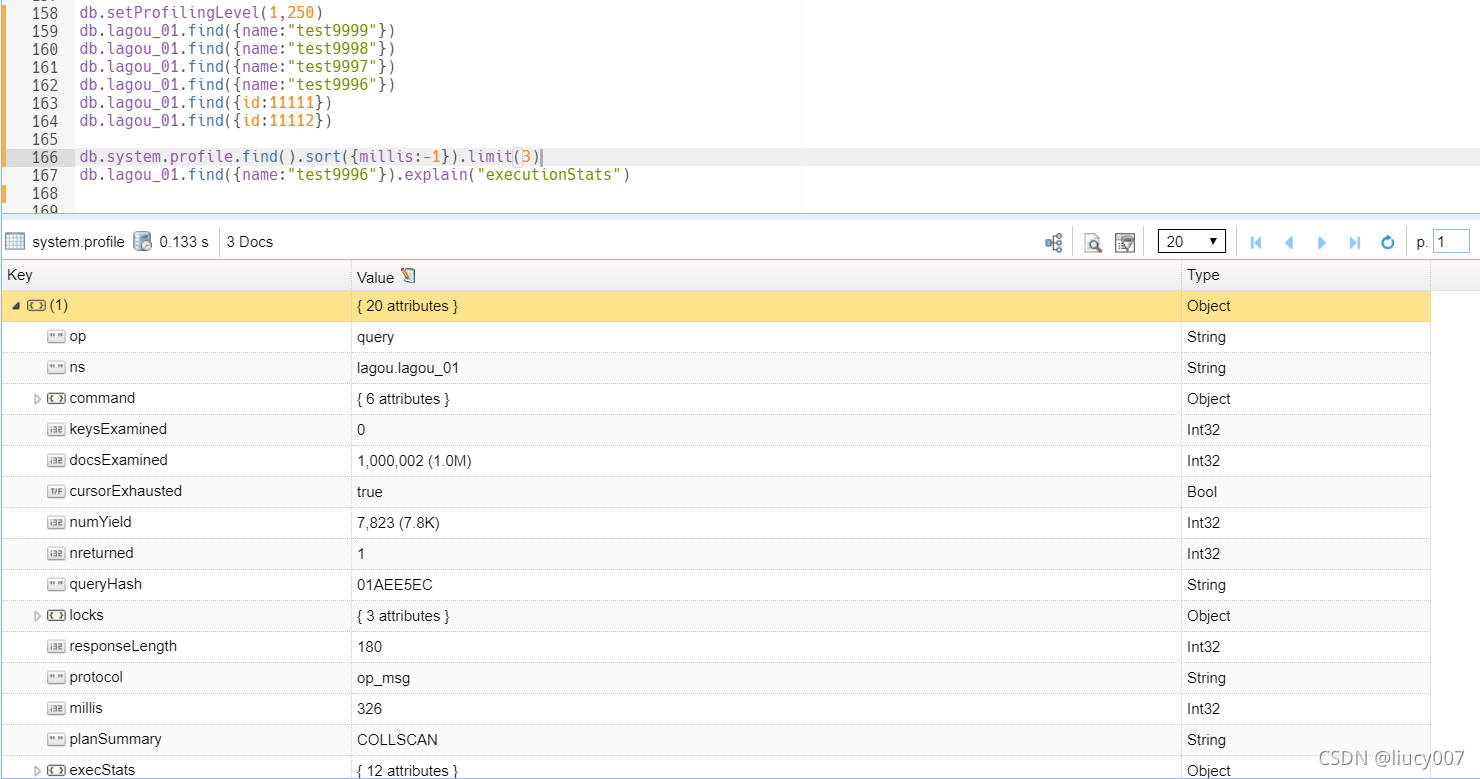
2.查询监控结果
db.system.profile.find().sort({millis:-1}).limit(3)
3.分析慢速查询
应⽤程序设计不合理、不正确的数据模型、硬件配置问题,缺少索引等
4.解读explain结果 确定是否缺少索引


















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









