



1.kafka本身是个分布式集群,可以采用分区技术,并行度高。
2.读数据采用稀疏索引,可以快速定位要消费的数据
3.使用顺序磁盘IO
4.使用页缓存+0拷贝(这个是重点)
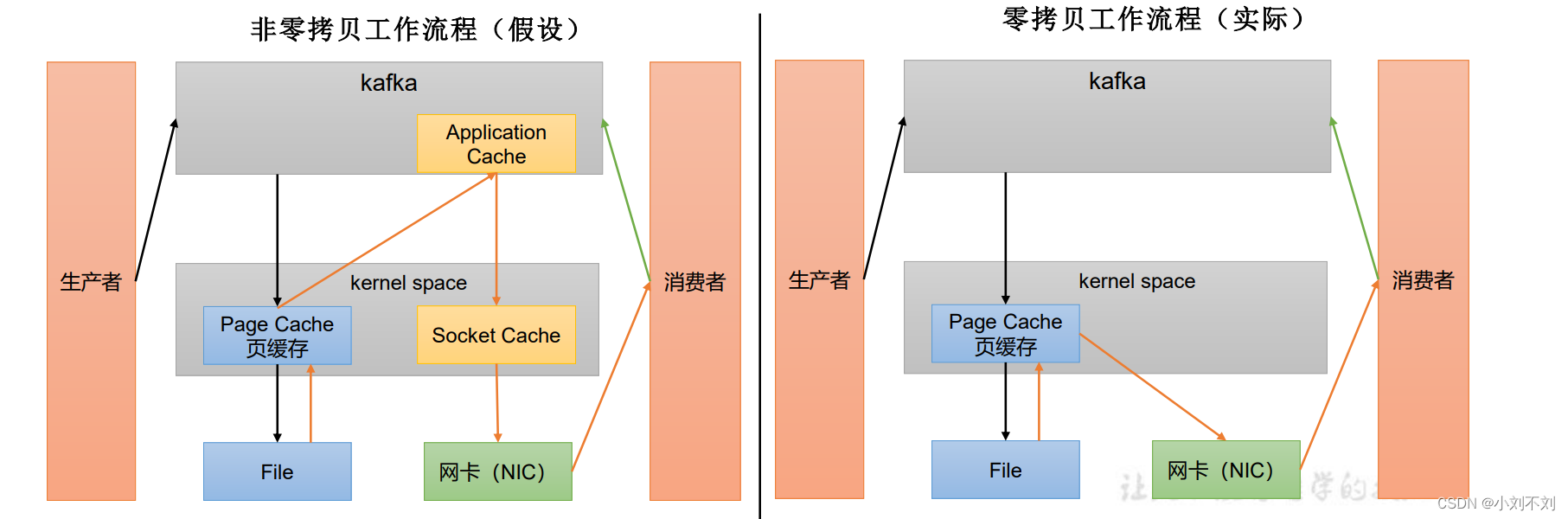
0拷贝:kafka应用层不关心存储的数据,由生产者对数据操作,由消费者对数据进行消费处理。
页缓存:
当生产者发送消息的时候,往里面进行写数据的时候,直接写如缓存中,当读数据的时候,先看页缓存中有没有,如果有直接返回,如果没有,从磁盘中读入数据,然后通过网卡直接返回给消费者。
 本文介绍了Kafka的分布式特性,包括其分区机制、利用稀疏索引提高读取速度,以及0拷贝策略和页缓存的使用,强调了生产者和消费者在数据处理中的角色。
本文介绍了Kafka的分布式特性,包括其分区机制、利用稀疏索引提高读取速度,以及0拷贝策略和页缓存的使用,强调了生产者和消费者在数据处理中的角色。
1.kafka本身是个分布式集群,可以采用分区技术,并行度高。
2.读数据采用稀疏索引,可以快速定位要消费的数据
3.使用顺序磁盘IO
4.使用页缓存+0拷贝(这个是重点)
0拷贝:kafka应用层不关心存储的数据,由生产者对数据操作,由消费者对数据进行消费处理。
页缓存:
当生产者发送消息的时候,往里面进行写数据的时候,直接写如缓存中,当读数据的时候,先看页缓存中有没有,如果有直接返回,如果没有,从磁盘中读入数据,然后通过网卡直接返回给消费者。
 2257
1241
2257
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























