






1.B-Tree:
B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同。下图展示了索引的表示方式:
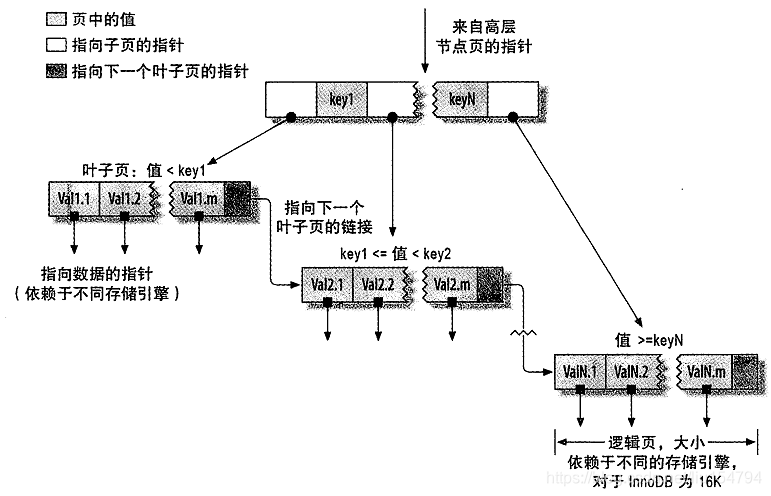
B-Tree 索引能过加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据,取而代之的是从索引的根节点开始搜索。根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和要查找的值可找到合适的指针进入下层子节点,大的往右,小的就往左。叶子节点的指针指向的是被索引的数据,而不是其他的节点页。
2.Hash:
哈希索引是基于哈希表实现的,只有精确匹配索引所有的列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引是将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在MySQL中,只有Memory 引擎显示支持哈希索引。这也是Memory 引擎表的默认索引类型,Memory 引擎同时也支持B-Tree索引。
3.区别:
Hash索引的限制:
(1)Hash 索引仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询。
(2)Hash 索引无法进行数据的排序操作。
(3)Hash 索引的组合索引不能利用部分索引列查询。
(4)Hash 索引在任何时候都不能避免全表扫描。
参数值通过hash算法找到行指针,之后获取表中的数据和参数值比较,返回结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
反之就是b-tree索引的优点。
参考:
假设索引使用假象的哈希函数 f( ),它返回下面的值(都是示例数据,非真实数据):
f('Arjen')=2323;
f('Liming')=7434;
f('Hanfeng')=6745;
f('Mars')=3245;
则哈希索引的数据结构如下:
槽(Slot) 值(Value)
2323 指向第 1 行的指针
3245 指向第 4 行的指针
6745 指向第 3 行的指针
7434 指向第 2 行的指针
注意每个槽的编号是顺序的,但是数据行不是。现在,来看如下查询:
mysql> SELECT lname FROM testhash WHERE fname= 'Liming';
MySQL 先计算 ‘Liming’的哈希值,并使用该值寻找对应的记录指针。因为f('Liming')=7434,所以MySQL 在索引中查找 7434 ,可以找到指向第 2 行的指针,最后一步是比较第三行的值是否是 'Liming',以确保就是要查找的行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









