




 NCCL是一个针对多GPU集群通信的轻量级库,能够利用拓扑结构提高通信效率。它支持多种集体通信模式,如all-reduce、all-gather、broadcast等,并提供了接近最优的带宽性能。
NCCL是一个针对多GPU集群通信的轻量级库,能够利用拓扑结构提高通信效率。它支持多种集体通信模式,如all-reduce、all-gather、broadcast等,并提供了接近最优的带宽性能。
本文是对NCCL官方英文博客的翻译,方便大家学习交流。因水平有限,如有问题欢迎更正。
PS:我只翻译了介绍,且翻译的不严谨。nv官方博客给的介绍比较简单,大家有个简单认知就可以了。博客里对NCCL的使用介绍的也非常简单,随后我会翻译并丰富NCCL的使用,单独成一篇博客。
目前许多服务器包含8个或更多的GPU。 理论上,将应用程序从一个GPU扩展到多个GPU应该提供巨大的性能提升。然而在实践中,性能提升往往很难达到理论值。
这个问题往往是由两个原因导致。 第一是分配任务时没有充分利用的并行性,从而导致处理器不饱和。 第二个原因是任务分配不合理,导致GPU间需要交换大量数据,花费更多的时间进行通信而不是计算。 解决通信瓶颈的最重要的方式是充分利用可用的GPU间带宽,这是NCCL所关心的。
NCCL(发音为“Nickel”)是一个多GPU集群通信原语库,它具有拓扑感知能力,可以轻松集成到您的应用程序中。 NCCL最初作为一个开源研究项目开发,因此NCCL的特点为轻量级,仅依赖于通常的C ++和CUDA库。 NCCL可以部署在单进程或多进程应用程序中,透明地处理进程间通信。 最后,NCCL的API格式与MPI collective的API格式基本相同,如果你有MPI collective经验,那可以很快上手NCCL。
Collective Communication
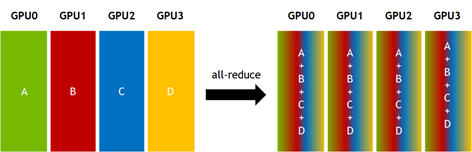
Collective communication routines是许多处理器之间的数据传输的常见模式。 如果你有MPI的经验,那么你应该已经很熟悉常见的集体操作。例如,图1是一个all-reduce的例子。共四个GPU(0,1,2,3),每个GPU上有一个大小为N的vector(A,B,C,D),计算为求vectorAdd,S[k]=A[k]+B[K]+C[k]+D[k](
0<=k<N
).
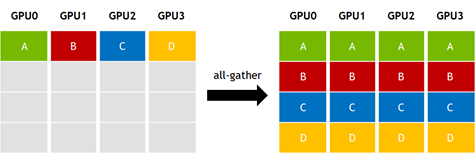
另一个常见的collective操作是all-gather,其中K个GPU中有一个N大小的数组,每个GPU将自己的数组传播到其他所有GPU中,最后所有GPU都会得到N * K大小的结果数据,如图2所示。
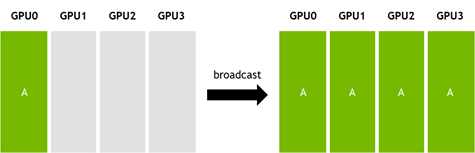
broadcast是第三例子。broadcast即将一个GPU内的N大小数据传输到其他所有GPU中。如图3所示。
以上所有提到的collectives实现都有“out-of-place”和“in-place”版本。“out-of-place”的意思是输入数据和输出数据是互相独立的数据空间。“in-place”的意思是输出数据覆盖输入数据。
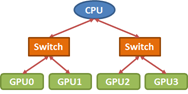
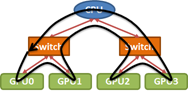
有许多方法可以有效地实现collectives。然而,与众不同的是,我们的实现考虑了处理器之间的互连拓扑。例如,在如图4所示的PCIe树拓扑中,考虑将数据从GPU0广播所有其它GPU。
在这种情况下,two-step树算法是常见的选择。第一步,数据先从GPU0传输到一个GPU中。第二步,数据从这两个GPU中同时传输到剩余的其他GPU。
在本例子中,two-step树算法有两种选择。(1)第一步中将数据从GPU0传输到GPU1,然后第二步GPU0 to GPU2,GPU1 to GPU3。(2)第一步中将数据从GPU0传输到GPU2,然后第二步GPU0 to GPU1,GPU2 to GPU3。根据拓扑结果,很明显能够看出第二选项是较优的,因为从GPU0到GPU2和GPU1到GPU3同时发送数据将导致在PCIe链路上的争用,从而导致在该步骤中,有效带宽减半。一般来说,为了实现良好的collectives性能,需要仔细注意互连拓扑。
一个环形(ring)拓扑结构是一个很好的方法来优化broadcast的带宽。
然后通过将环周围的输入的小块从GPU0中继到GPU3来执行广播。 有趣的是,即使当应用于“树形”PCIe拓扑时,环算法也为几乎所有的标准集合操作提供接近最优的带宽。 但请注意,选择正确的振铃顺序仍然很重要。
GPU Collectives with NCCL
NCCL内collectives的实现方式为ring-style,以提供最大带宽。NCCL能够自动对GPU进行编号并实现最佳ring顺序。因此程序员不需要对硬件进行配置即可时应用程序在获得很好的性能。
许多collectives实现时需要一个缓冲区来存储中间结果。 为了最小化每个GPU上的几MB的内存开销,NCCL将大型集合分成许多小块。 对于集合算法的每个步骤和块。
启动单独的内核和cudaMemcpy调用是非常低效的。对于一个collectives算法,将每一个步骤实现为一个kernel,每一个chunk数据都执行cudaMemcpy,这种做法是非常低效的。因此,NCCL内的每一个collective操作都由一个大kernel实现。
NCCL广泛使用GPUDirect peer to peer直接访问方式在处理器之间传输数据。
在两个GPU P2P 访问不可用的情况下(比如两个GPU分别挂载在两个CPU下的PCI-E switch下,此时这两个GPU是不能P2P的),数据要先传输到pinned memory暂存,再传输到目标GPU。类似地,通过轮询device memory 或 pinned memory中volatile变量来实现同步。
在NCCL中,NCCL使用三个primitives来实现每个collectives:Copy, Reduce, and ReduceAndCopy。每一个步骤都被优化,目的是能够有效地在GPU间传输细颗粒度的数据片段(4-16KB)。NVCCL中的kernels经过优化后,实现了在低占用率下实现最大带宽。因此,NCCL可以达到使用单个CUDA block就可以使PCIe 3.0*16互联带宽饱和。这使得小部分线程通信、大部分线程计算同时进行。
NCCL目前支持all-gather,all-reduce,broadcast,reduce和reduce-scatter collectives操作。NCCL只适用于单节点环境,节点内可以由任意数量的GPU。



















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









