




一、内存
free -h
top #进去后按m (按M表示以内存利用率进行排序)
buff/cache 是什么?
缓冲区(Buffer)和 缓存(cache)都是用于暂时保存从磁盘读取的数据,以便稍后快速访问。缓冲机制的存在可以减少对磁盘的频繁访问,提高读取文件的速度。
综上所述,缓冲区和缓存都是用于提高系统性能的内存机制,但它们的作用和使用方式略有不同,缓冲区用于存储较小的数据块,而缓存用于存储较大的数据块和文件系统元数据
二、cpu
什么是cpu 利用率 ,平均负载?
- CPU Utilization : 非空闲进程(线程)占用时间的比例
- Load Average:单位时间内平均活跃进程数(可运行状态R + 不可中断状态D 的平均进程数)
cpu负载知识点扩展:
如果load average大于cpu逻辑核数的70%,证明负载过高,因为此时进程响应会变慢。这个一段时间一般取1分钟、5分钟、15分钟。当逻辑核数为2时,负载为2,说明所有的核数被完全占用。
load average(一分钟)=(cpu正在处理的线程数+等待处理的线程数)/cpu单核每分钟最多能处理的线程
1、 cpu 利用率
导致cpu 利用率过高:cpu密集型
案例:cpu利用率过高,排查是哪个进程的哪个函数导致的
//开启2个CPU进程执行sqrt计算,600秒后结束。 -c,--cpu:代表进程个数(每个进程会占用一个cpu,当超出cpu个数时,进程间会互相争用cpu)
stress --cpu 2 --timeout 600
//查看利用率 top命令进去后按P 会以cpu利用率排序,按c显示详细命名
//如果某进程cpu使用率过高,可以用perf 命令排查是哪个函数导致的
//top实时显示占用 CPU 时钟最多的函数或者指令 -g开启调用关系分析,-p指定的进程号
//Shared,是该函数或指令所在的动态共享对象,如内核、进程名、动态链接库名、内核模块名等;Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示,[.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间
perf top -g -p [pid]
Samples: 169K of event 'cpu-clock', 4000 Hz, Event count (approx.): 6511972816 lost: 0/0 drop: 0/0
Children Self Shared Object Symbol
+ 37.55% 37.51% libc-2.17.so [.] __random_r
+ 29.65% 29.63% libc-2.17.so [.] __random
+ 10.76% 10.76% stress [.] 0x0000000000002dc1
+ 9.62% 9.61% libc-2.17.so [.] rand
+ 4.85% 4.84% stress [.] rand@plt
案例二:cpu利用率过高,但是无法发现cpu使用率过高的进程。
#通过pstree来查找父进程,找出调用关系
pstree |grep 进程名
2、cpu负载
导致cpu负载过高:cpu密集型(可能会)、I/O 密集型、上下文切换
2.1 I/O 密集型:
案例:
//-i 开启2个IO进程,执行sync系统调用,刷新内存缓冲区到磁盘;-hdd 临时读写文件个数
stress-ng -i 4 --hdd 1 --timeout 600
//查看iowait
iostat 5 1
//查看所有进程的io情况
pidstat -d 5 1
2.2 上下文频繁切换
上下文:上下文又叫CPU上下文,是CPU运行任何任务前,必须依赖的环境
cpu执行任务所需要的环境:每个任务运行前, CPU 都需要知道任务从哪里加载,又从哪里开始运行。也就是说,需要系统事先给他设置好 CPU 寄存器和程序计数器
通过上面两个概念,可知上下文切换其实就是 :cpu执行所需要环境的切换
//使用 sysbench 来模拟系统多线程调度切换的情况
//以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题
sysbench --threads=10 --max-time=300 threads run
vmstat 1 //判断cs情况
cs (context switch) 每秒上下文切换次数
in (interrupt) 每秒中断次数
r (runnning or runnable)就绪队列的长度,正在运行和等待CPU的进程数
b (Blocked) 处于不可中断睡眠状态的进程数
pidstat -w //查看哪个进程的cs过高
cswch 每秒自愿上下文切换次数 (进程无法获取所需资源导致的上下文切换)
nvcswch 每秒非自愿上下文切换次数 (时间片轮流等系统强制调度)
三、磁盘
四、网络
3.1 丢包率
ping
3.2 网络延迟
tracepath
mtr
3.3 流量进出情况
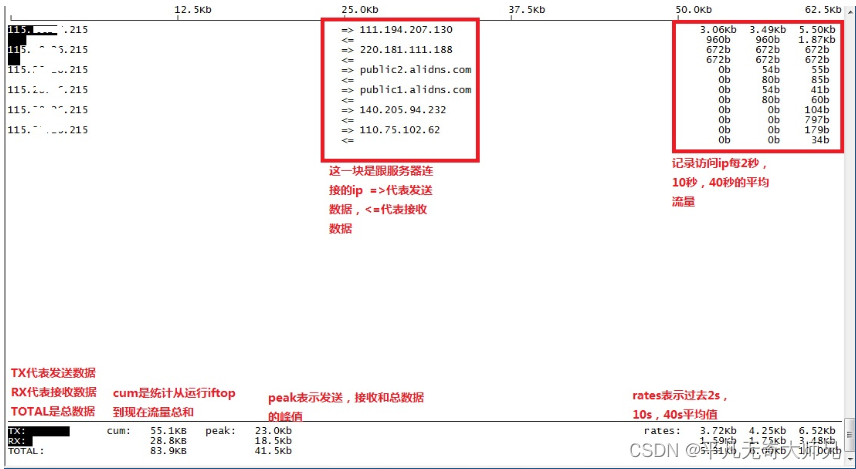
iftop
iftop -i eth0 -P
3.2 sar
命令用法
sar -n DEV #查看当天从零点到当前时间的网卡流量信息
sar -n DEV 1 10 #每秒显示一次,共显示10次
sar -n DEV -f /var/log/sa/saxx #查看xx日的网卡流量历史
sar -q #查看历史负载
sar -b #查看磁盘读写
DEV显示网络接口信息
指标含义
IFACE 表示设备名称(LAN接口)
rxpck/s 每秒接收数据包的数量
txpck/s 每秒发出数据包的数量
rxKB/s 每秒接收的数据量(字节数),单位KByte 1KB=1000byte=8000bit
txKB/s 每秒发出的数据量(字节数),单位KByte
rxcmp/s:每秒钟接收的压缩数据包
txcmp/s:每秒钟发送的压缩数据包
rxmcst/s:每秒钟接收的多播数据包
rxerr/s:每秒钟接收的坏数据包
txerr/s:每秒钟发送的坏数据包
coll/s:每秒冲突数
rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
txcarr/s:发送数据包时,每秒载波错误数
rxfram/s:每秒接收数据包的帧对齐错误数
rxfifo/s:接收的数据包每秒FIFO过速的错误数
txfifo/s:发送的数据包每秒FIFO过速的错误数

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









