



参考官网-Handling Application Parameters
一、idea 本地运行
使用Flink官方的ParameterTool或者其他工具都可以。
二、集群运行flink run/run-application
flink run-application -t yarn-application -h
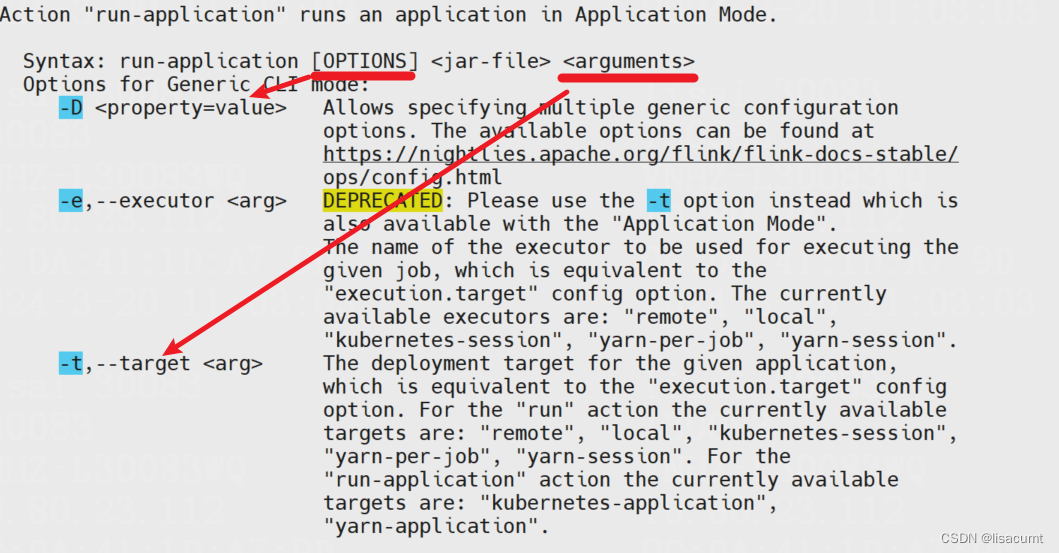
flink参数有两种:(1)flink内部参数,此参数会保存到flink stream env中,以下简称opts参数。(2)程序自定义参数,通过入口类main方法传入,程序自行处理,以下简称args参数。(3)设置系统环境变量,从flink Parameter工具中获取,以下简称env参数。
参考文章:
系统变量之System.getenv和System.getProperty()
linux环境变量和linux命令export
三、获取flink内部参数的办法-StreamEnv获取参数
举个例子使用以下方式启动flink job。
flink run application -Dstate.savepoints.dir=hdfs://mycluster/flink/flink-checkpoints/my-job ...
可通过以下代码获取:state.savepoints.dir 参数
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// flink run/run-application添加参数-s 和 --fromSavepoint
String savepointRestorePath = env.getConfiguration().get(SavepointConfigOptions.SAVEPOINT_PATH);
需要说明:使用StreamExecutionEnvironment 和 StreamTableEnvironment 都无法获取参数。
四、具体实战测试
具体测试过程如下:
代码:
public class ConfTest {
private final static Logger logger = LoggerFactory.getLogger(ConfTest.class);
public static void main(String[] args) throws Exception {
ParameterTool argsPt = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool sysPt=ParameterTool.fromSystemProperties();
logger.warn(String.format("get from args: %s", argsPt.get("udf.args.key"))); // false
logger.warn(String.format("get from opts: %s", ExecutionEnvironment.getExecutionEnvironment().getConfiguration().toMap().get("udf.opt.key"))); // false
logger.warn(String.format("get from env.java.opts.all: %s, java.api.system.properties:%s, java.api.system.env:%s",sysPt.get("job.all.key1") ,System.getProperty("job.all.key1"),System.getenv("job.all.key1"))); // success
logger.warn(String.format("get from env.java.opts.jobmanager: %s, java.api.system.properties:%s, java.api.system.env:%s",sysPt.get("job.jb.key1"),System.getProperty("job.jb.key1") ,System.getenv("job.jb.key1"))); // success
logger.warn(String.format("get from env.java.opts.taskmanager: %s, java.api.system.properties:%s, java.api.system.env:%s",sysPt.get("job.ts.key1") ,System.getProperty("job.ts.key1"),System.getenv("job.ts.key1"))); // success
logger.warn(String.format("get from env.hadoop.conf.dir: %s, java.api.system.properties:%s, java.api.system.env:%s",sysPt.get("HADOOP_CONF_DIR"),System.getProperty("HADOOP_CONF_DIR"),System.getenv("HADOOP_CONF_DIR") )); // success
logger.warn(String.format("get from java.api.system.properties: %s,pt.apt.system.properties:%s",System.getProperties().get("UDF_ENV_KEY"),sysPt.get("UDF_ENV_KEY") )); // success
readConfigFromHdfs();
SourceFunction<String> src = new SourceFunction<String>() {
long counter = 0;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (true) {
ctx.collect(String.format("ele-%d", counter++));
Thread.sleep(5000L);
}
}
@Override
public void cancel() {
}
};
SingleOutputStreamOperator<String> srcDs = env.addSource(src).name("fake_source");
// srcDs.print();
SinkFunction<String> logSink = new SinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
logger.warn(String.format("receive val: %s", value));
}
};
srcDs.addSink(logSink).name("log_sink");
env.execute();
}
public static void readConfigFromHdfs() throws IOException {
// String hadoopConf = ParameterTool.fromSystemProperties().get("HADOOP_CONF_DIR");
Configuration hc = new Configuration();
FileSystem fs = FileSystem.get(hc);
FSDataInputStream is = fs.open(new Path("/user/xxx/flink-conf/hdfs-props.properties"));
ParameterTool hdfsPt = ParameterTool.fromPropertiesFile(is);
logger.warn(String.format("get from hdfs props:%s", hdfsPt.toMap().toString())); // success
}
}
linux环境启动任务:
export UDF_ENV_KEY=ENV_VAL
flink run-application -t yarn-application -d -c com.h3c.test.ConfTest \
-Dyarn.application.name="ConfTest" \
-Dudf.opt.key=opt_val \
-Denv.hadoop.conf.dir=/usr/hadoop/conf \
-Denv.java.opts="-Djob.all.key1=all_val1 -Djob.all.key2=all_val2" \
-Denv.java.opts.jobmanager="-Djob.jb.key1=val1 -Djob.jb.key1=val1" \
-Denv.java.opts.taskmanager="-Djob.ts.key1=val1 -Djob.ts.key2=val2" \
hdfs://mycluster/user/dcetl/lisai/flink-conf/flink-config-1.0.jar \
--udf.args.key args_val
yarn app打印日志:
get from args: args_val
get from opts: opt_val
get from env.java.opts: all_val1, java.api.system.properties:all_val1, java.api.system.env:null
get from env.java.opts.jobmanager: val1, java.api.system.properties:val1, java.api.system.env:null
get from env.java.opts.taskmanager: null, java.api.system.properties:null, java.api.system.env:null
get from env.hadoop.conf.dir: null, java.api.system.properties:null, java.api.system.env:/xxx/hadoop/conf
get from java.api.system.properties: null,pt.apt.system.properties:null
get from hdfs props:{hdfs.key2=val2, hdfs.key1=val1}
五、结论:
(1)推荐从ParameterTool直接读取文件(本地文件或者hdfs文件均可),或从main方法的args解析参数。
(2)如需设置jvm参数推荐使用env.java.opts,注此参数不同flink版本可能不同新版为env.java.opts.all。
(3)提交任务机器本地设置的export环境变量,在flink on yarn可能完全获取不到。
(4)-Denv.hadoop.conf.dir设置的HADOOP_CONF_DIR可能不生效,具体设置方法不详。

















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









