




 本文详细介绍了如何通过动态加载技术改进GPText的升级流程,以显著提高升级速度。作者分析了现有RollingUpgrade的缺点,并提出了两种替代方案,最终采用动态加载实现无需重启的升级,避免了耗时的节点重启和可能的活锁问题。文章还探讨了内存管理和类加载器的工作原理,解决了潜在的内存泄露问题,确保了升级过程的稳定性和效率。测试结果显示,升级速度得到了显著提升。
本文详细介绍了如何通过动态加载技术改进GPText的升级流程,以显著提高升级速度。作者分析了现有RollingUpgrade的缺点,并提出了两种替代方案,最终采用动态加载实现无需重启的升级,避免了耗时的节点重启和可能的活锁问题。文章还探讨了内存管理和类加载器的工作原理,解决了潜在的内存泄露问题,确保了升级过程的稳定性和效率。测试结果显示,升级速度得到了显著提升。
笔者在VMWare负责GPText的研发。前些日子突然灵感乍现,想到可以通过动态加载的方式,来大幅提高GPText的升级速度。经测试,改进后的升级速度可以提高10倍以上!
GPText简介
进入正文前,先简单介绍下GPText。GPText是GPDB(Greenplum-DB)的一个扩展,是GPDB生态系统的重要组成部分,它无缝集成了Greenplum数据库海量数据并行处理以及Apache Solr企业级文本检索的能力,为用户提供了一套易于使用、功能完备的文本检索、分析方案。这么说可能有点抽象,别担心,看完下面的例子大家就会明白。
假设我们要从GPDB数据库中找到这样一篇新闻:同时包含有艾伦(Alan)和克林顿(Clinton)两个人,并且两个人的间距不能超过10个单词。这样的搜索条件用普通的SQL语句是极难高效实现的。但如果使用GPText,我们就可以用"Clinton Alan"~10这样的简单查询来实现。

GPText架构
为了更好地描述接下来要讲的内容,这里需要简单向介绍一下GPText的架构。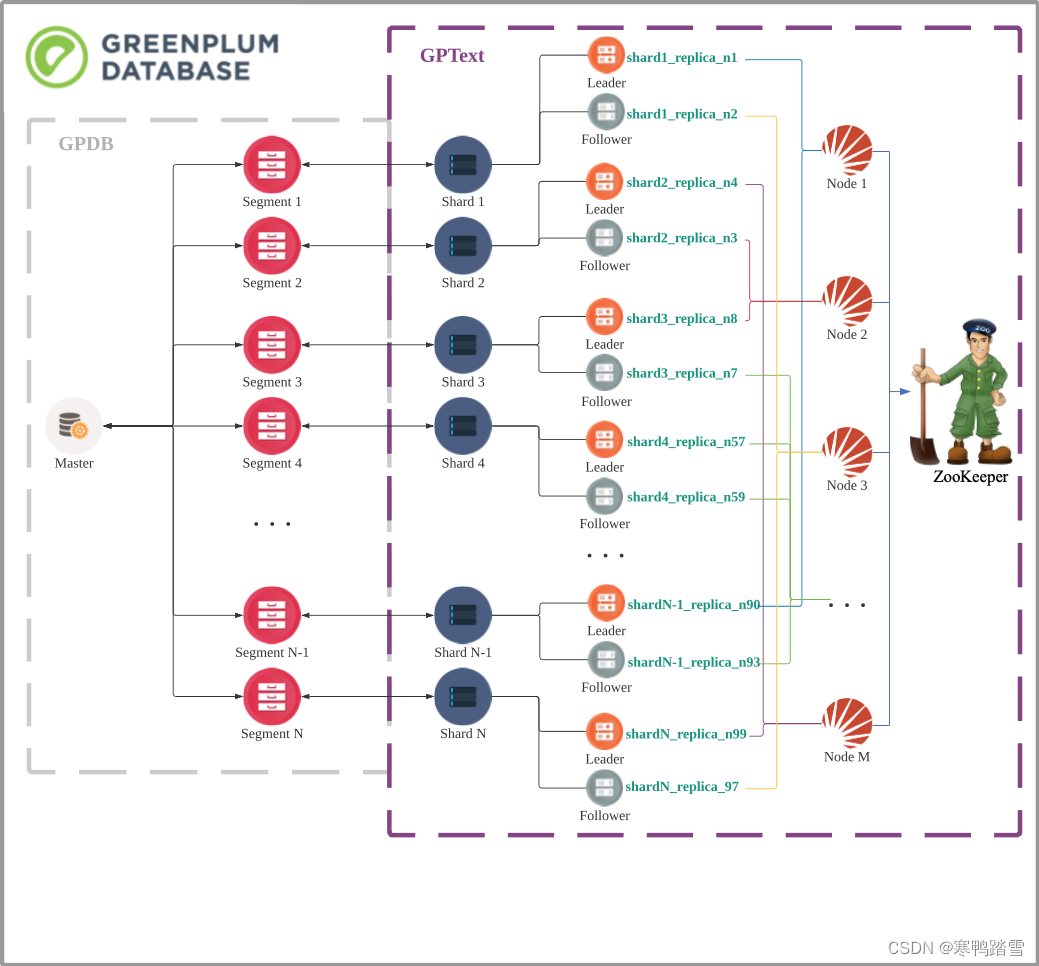
大家都知道GPDB集群分为master和segment两种角色,如上图。master主要负责调度和存放一些集群的metadata,真正的数据是分片存放在segment上的。为了达到高可用性,每个分片又有两个副本,分为primary和mirror。GPText(Solr)架构与GPDB类似,分为两种角色,Zookeeper和Solr。其中ZooKeeper集群负责存放一些配置文件和metadata,真正的数据则存放在Solr中。此外,GPText(Solr)也采用分片+副本的设计,每个分片叫做shard,有多个副本(replica)。replica又分为leader和follower,分别对应GPDB的primary和mirror。上图中的Node(以下成为节点)可以理解为一个Solr进程(Java进程)。replica是分布在不同的Solr进程中运行的。
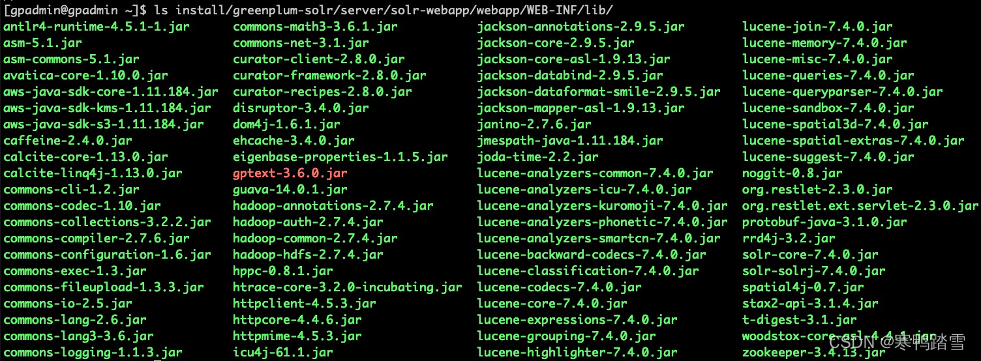
接下来介绍一下GPText的一个重要目录。如下图所示。熟悉JSP的读者看到WEB-INF/lib可能会感到熟悉。没错,这个是基于servlet的web服务器运行webapp时存放Java库文件的文件夹。Solr默认使用Jetty作为其web服务器,其库文件便存放在图示的文件夹中。其中,由于GPText定制了不少插件,所以也打了个jar包置于此文件夹中。
GPText升级
Rolling Upgrade
简化后,GPText的升级过程本质上是一个Rolling Upgrade的过程。以GPText 3.6.0升级为3.7.0为例,即将上图所示的gptext-3.6.0.jar文件替换成gptext-3.7.0.jar后,对Solr节点依次进行重启。每次重启时,需要等重启的Solr节点恢复正常工作后才能重启下一个。如下图。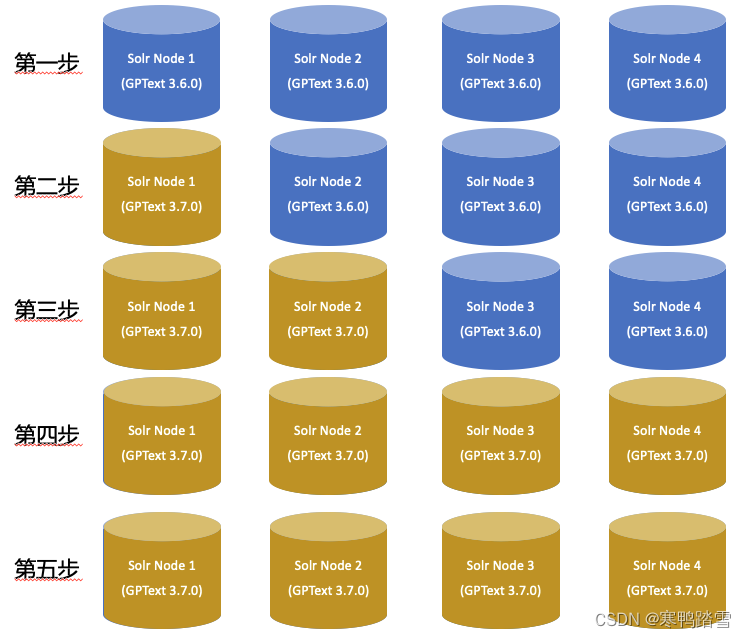
采用Rolling Upgrade有以下优点
- 理解容易
- 实现简单
- Solr官方推荐
然而,缺点也非常明显,就是十分耗时。在一个大集群中,重启一个Solr节点可能需要超过2分钟的时间,因为在启动期间不仅需要去连接ZooKeeper,还需要进行leader的选举等操作才能进行正常工作。不仅如此,在一个大集群中,可能会有上百个Solr节点,因此完成一个GPText的升级,需要的时间有可能会超过2小时。
备选方案
为了提高GPText的升级速度,我们有两种方案。
- 并行重启Solr节点。
- 在不启动Solr节点的情况下去升级GPText。
方案1主要有两个问题。
- 如果用户生产环境重启失败了该怎么办?虽然我们发布新版本前都会进行大量的测试,但谁也无法预料用户的环境是否会有什么特殊情况导致重启失败。如果是Rolling Upgrade,GPText就可以在第一个节点重启失败时阻止后续节点的重启。由于GPText高可用的特性(每个分片都有多个副本),一个节点失效了整个集群仍可继续工作。而且,由于只有一个节点失败,恢复起来也更加容易。
- 由于每个replica都需要连接ZooKeeper,因此若所有Solr节点同时重启,就会有有大量replica同时连接ZooKeeper,会出现刚刚连接上的replica又断开连接的情况。断开连接的replica会尝试重连,进而导致其它的replica断开连接,如此循环往复产生活锁的现象。这个现象可以100%复现,不过笔者一直没有经历去深究其原因。(笔者不负责任地猜测,选举leader的时候双方约定如果多久还选不出来,相应的所有replica都要断开重连,结果产生了活锁。)
方案1不能采用的话就只能采用方案2了。那如何实现方案2呢?就是采用Java的动态加载技术。
动态加载
其实GPDB也算用了动态加载:把一些so文件替换掉之后,是不需要重启GPDB才能生效的,只需启动新的session即可。但启动新session其实也就是启动了新的进程。
而我们这里的动态加载则需更近一步,要求
- 替换jar文件后不重启新的进程就要生效
- 我们需要在原进程中载入新实现的类
- 要把以前实现的类卸载掉
实现这三点分别需要用三种技术:
- ClassLoader(以下称为类加载器),负责从文件或其它永久层中加载类
- 反射,负责通过类名生成Class对象(以下称为类对象)及其对应的对象
- 垃圾回收,负责回收无用的对象,类对象以及类加载器对象
典型用法
为了方便大家理解,接下来将向大家举个例子讲解一下动态加载的典型用法。
假设在classpath中有下面这个Foo接口。该接口只有一个bar方法。
package a.b.c;
public Interface Foo {
public void bar();
}而我们有一个FooImpl类实现了Foo接口,如下。我们将其编译打包成jar文件,放到<path>下。
package d.e.f;
public class FooImpl implements Foo {
@Override
public void bar() {
...
}
}那么我们可以用下面的代码来调用FooImpl的bar方法。
// A class loader is an object responsible for loading classes
ClassLoader customedLoader = getClassLoader(<path>)
// An Instance of the class represent a class or an interface in a running Java application
Class fooImplClass = Class.forName(“d.e.f.FooImpl”, false, customedLoader)
(Class fooImplClass = customedLoader.loadClass("d.e.f.FooImpl"))
// Foo.class
// == this.getClass().getClassLoader().loadClass(”a.b.c.Foo")
// == customedLoader.loadClass(”a.b.c.Foo")
Foo obj = (Foo) fooImplClass.newInstance()
obj.bar()上述代码中的倒数第二行
Foo obj = (Foo) fooImplClass.newInstance()能否改为
Foo obj = new FooImpl();或
FooImpl obj = (FooImpl)fooImplClass.newInstance();呢?
答案是不可以。因为classpath中并没有FooImpl这个类。如果改成上述两种写法,编译期间就会出错。
此外注意,这里要求customedLoader加载的Foo.class和当前类加载器对象加载的Foo接口是同一个,即注释中提到的
Foo.class
== this.getClass().getClassLoader().loadClass(”a.b.c.Foo")
== customedLoader.loadClass(”a.b.c.Foo")这里会涉及到后面讲的双亲委派机制。
Solr的类加载过程
下面代码为Solr的类加载过程。为了方便讲解,这里对Solr的源码进行了大幅简化和修改。
public class ReplicaContainer {
protected ClassLoader loader;
protected List<Replica> replicas;
public ReplicaContainer(ClassLoader loader) {
// This ClassLoader is passed by jetty, contains all classes in WEB-INF/lib directory
this.loader = loader;
}
public ClassLoader getClassLoader() {
return loader;
}
public void load() throws Exception {
createReplicas();
...
}
protected void createReplicas() throws Exception {
replicas = new ArrayList<>();
for (String replicaName : getReplicaNames()) {
List<Plugin> plugins = new ArrayList<>();
for (String pluginName : getReplicaPluginNames()) {
Class pluginClass = Class.forName(pluginName, false, loader);
plugins.add((Plugin) pluginClass.newInstance());
}
replicas.add(new Replica(replicaName, plugins));
}
}
...
}
从代码中可以看出,ReplicaContainer在构造的时候,获得了一个从Jetty传过来的类加载器。这个类加载器可以加载WEB-INF/lib下所有jar包里的类。
需要注意的是,这里有一个public的getClassLoader方法。这说明ReplicaContainer内的这个类加载器是可以在ReplicaContainer之外使用的。
双亲委派模型(The Parent-Delegation Model)
为了方便接下去的讲解,这里需要先介绍一下双亲委派模型。
双亲委派模型,其实就是一个普通的代理模式。在一个类加载器收到加载类A的请求时,先将这个请求由该加载器的父加载器进行处理。若父加载器无法加载类A,再由自己去尝试加载类A。简化后的代码如下
// These methods have been simplified
protected ClassLoader(ClassLoader parent) {
this.parent = parent;
}
public Class loadClass(String name) throws ClassNotFoundException {
if (parent != null) {
try {
return parent.loadClass(name);
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
}
// If still not found, then invoke findClass to find the class.
return this.findClass(name);
}
为了保证之前提到过的
Foo.class
== this.getClass().getClassLoader().loadClass(”a.b.c.Foo")
== customedLoader.loadClass(”a.b.c.Foo")就需要将this.getClass().getClassLoader()设置为customdLoader的直接或间接双亲加载器。
让Solr动态加载类
方案一 ——替换ReplicaContainer里的类加载器
直觉上,可以用下面的方法来实现动态加载。这样每当需要升级GPText时,无需重启,只需在替换掉gptext-xxx.jar文件后调用一下ReplicaContainer.reload方法即可。
public class ReplicaContainer {
protected CustomClassLoader loader;
protected List<Replica> replicas;
public ReplicaContainer(ClassLoader parentLoader, String libPath) {
// parentLoader is passed by jetty, contains all classes in WEB-INF/lib directory
this.loader = new CustomClassLoader(parentLoader, libPath);
}
public void reload() throws Exception {
this.loader = new CustomClassLoader(loader.getParent(), loader.getLibPath());
createReplicas();
}
public ClassLoader getClassLoader() {
return loader;
}
…
}
方法一的致命缺陷
然而这个方法有一个致命缺陷,就是getClassLoader是public方法,可以被外部调用。如果外部调用并保存了getClassLoader方法返回的类加载器,那调用reload只能替换掉ReplicaContainer里的类加载器,而不能替换后者保存的类加载器。这样的话会使得原始的类加载器得以继续使用,造成很多问题。
方案二——使用代理模式(Delegation Pattern)
实际上双亲委派模型已经是代理模式了。但我们可以再套一层代理模式,代码如下
class RealClassLoader extends ClassLoader {
public RealClassLoader(ClassLoader parent, String libPath) {
super(parent);
...
}
public String getLibPath() {
...
}
}
class CustomClassLoader extends ClassLoader {
protected RealClassLoader realClassLoader;
public CustomClassLoader(ClassLoader parentLoader, String libPath) {
// getParent is a final method, can't be overwritten and
// delegated to realClassLoader.getParent().
// Have to do this to return parentLoader in method getParent()
super(parentLoader);
realClassLoader = new RealClassLoader(parentLoader, libPath);
}
public String getLibPath() {
return realClassLoader.getLibPath();
}
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
return realClassLoader.loadClass(name);
}
public void reload() throws Exception {
realClassLoader = new RealClassLoader(realClassLoader.getParent(),
realClassLoader.getLibPath());
}
}
public class ReplicaContainer {
protected CustomClassLoader loader;
protected List<Replica> replicas;
public ReplicaContainer(ClassLoader parentLoader, String libPath) {
// parentLoader is passed by jetty, contains all classes in WEB-INF/lib directory
this.loader = new CustomClassLoader(parentLoader, libPath);
}
public void reload() throws Exception {
this.loader.reload();
createReplicas();
}
public ClassLoader getClassLoader() {
return loader;
}
…
}
这样的话,我们便无需再担心getClassLoader传递出去的类加载器会被外部保存了,因为此时ReplicaContainer的reload的方法不再是替换掉ReplicaContainer里的类加载器,而是调用了CustomClassLoader的reload方法去替换掉其代理的类加载器。这个替换是可以影响到外部的,我们无需再担心新旧类加载器共存的情况。
方法二的致命缺陷
理想很丰满,现实很骨感。就在笔者以为即将万事大吉的时候,发现了一个问题,就是
“Class.forname”方法是带缓存的,请看下面的代码
CustomClassLoader customClassLoader = new CustomClassLoader(xxx, xxx);
Class foo1 = customClassLoader.loadClass("a.b.c.Foo");
Class foo2 = customClassLoader.loadClass("a.b.c.Foo");
System.out.println(foo1 == foo2); // true
customClassLoader.reload();
foo2 = customClassLoader.loadClass("a.b.c.Foo");
System.out.println(foo1 == foo2); // false
Class foo3 = Class.forName("a.b.c.Foo", false, customClassLoader);
System.out.println(foo2 == foo3); // true
customClassLoader.reload();
Class foo4 = Class.forName("a.b.c.Foo", false, customClassLoader);
System.out.println(foo3 == foo4); // true, but false is expected
由于Class.forName是带缓存的,传递的参数中只要类名和类加载器一致,则可能会返回同一个类对象。因此虽然调用了reload方法,但foo3和foo4依然是同一个对象。
关于Class.forName的缓存问题,详见(可能需要科学上网)
The Programming Delusion: Class.forName caches defined class in the initiating class loader
和
Class.forName和ClassLoader.loadClass - 送码网。
由于Class.forName在Solr代码中大量使用,因此我们也无法使用方法二。
重回方法一
经过各种测试和查询,我们发现并没有哪个地方保存了ReplicaContainer.getClassLoader返回的类加载器,因此我们姑且先使用一下方法一。
垃圾回收
在介绍接下去的内容前,我们需要简单介绍一下Java的垃圾回收机制。众所周知,Java的垃圾回收是基于可达性分析的。从一堆的root对象(main函数里的对象,每个进程启动函数里的对象等)开始,去寻找被root对象直接或间接引用的对象。如果某对象没有直接或间接被root对象引用,那个这个对象就会被当做垃圾回收,如下图
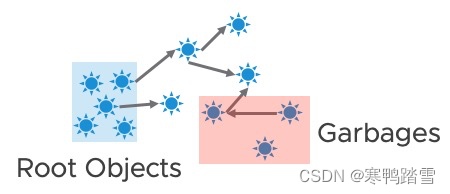
如果蓝色方框内的对象是root对象,那红色方框内的就是垃圾对象,因为它们“root不可达”。
类加载器与内存泄露
在java中,任意一个对象会引用它的类对象,而该类对象又会和它的类加载器对象相互引用,形成下图的引用关系
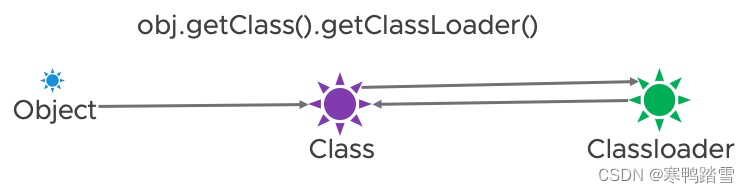
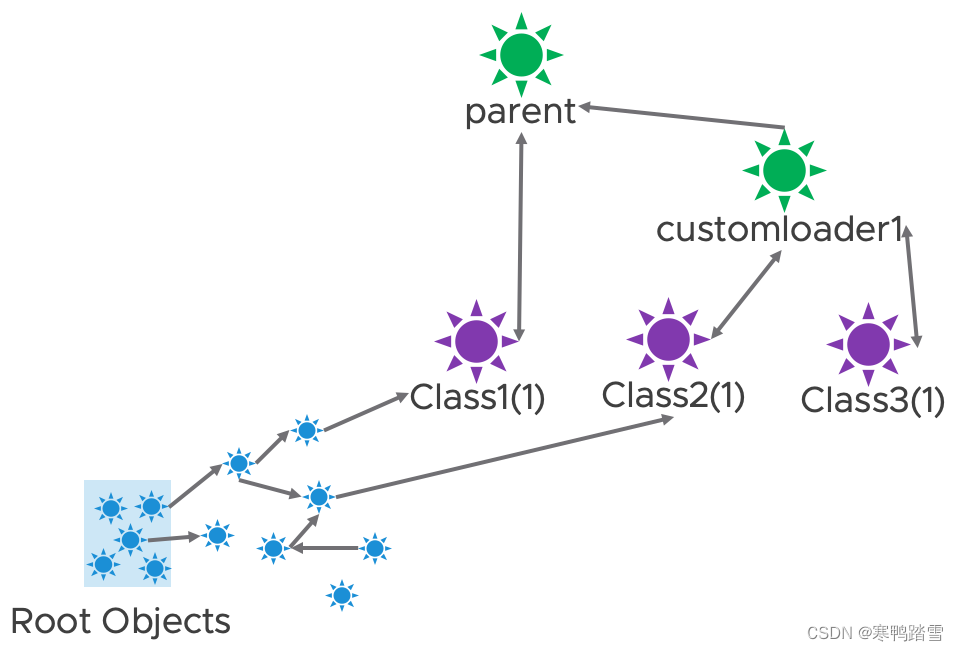
假设在我们调用ReplicaContainer.reload方法之前,引用关系如下 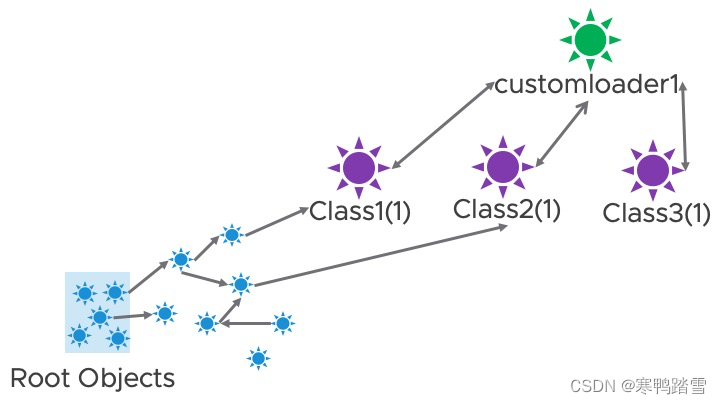
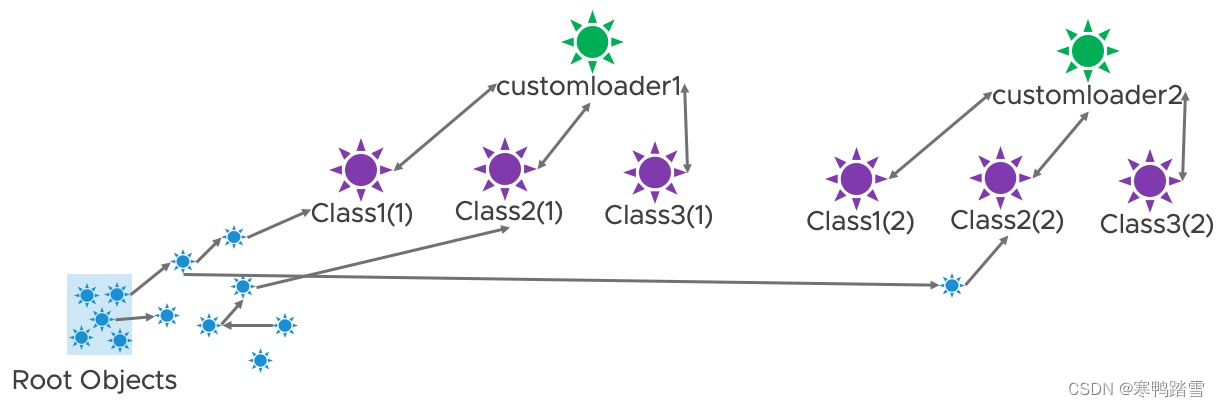
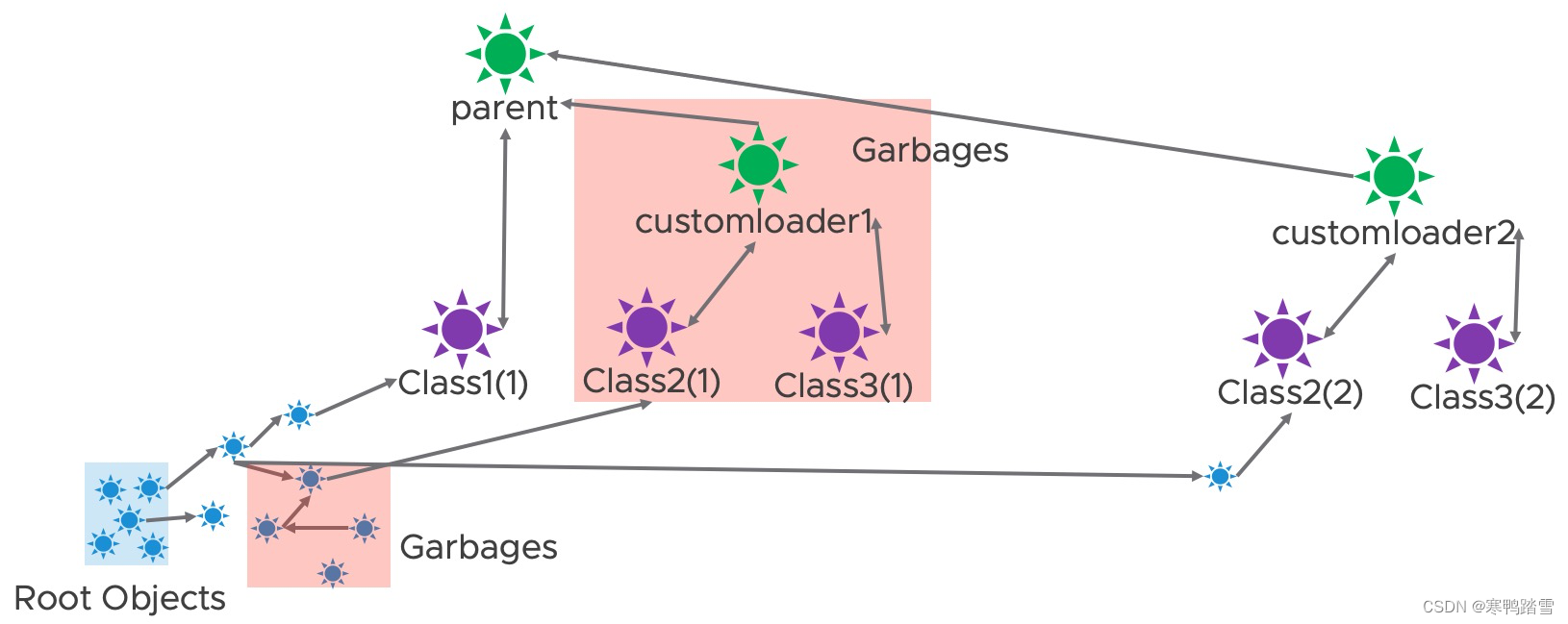
那么调用ReplicaContainer.reload方法之后,customloader1被替换成了customloader2,引用关系会变成如下图所示。由于ReplicaContainer.reload里还调用了createReplicas方法,因此会产生新的对象,对应下图中指向Class2(2)的对象。由于ReplicaContainer.getClassLoader是public类型,其返回的类加载器本身虽然没有被外部保存,但该类加载器加载的对象是会被外部保存的(即外部调用了ReplicaContainer.getClassLoader().getClass(xxx).newInstance()),在下图中则对应指向Class1(1)的对象。
此时若进行垃圾回收,根据可达性检测,可以发现如下的对象“root不可达”,会被当成垃圾回收
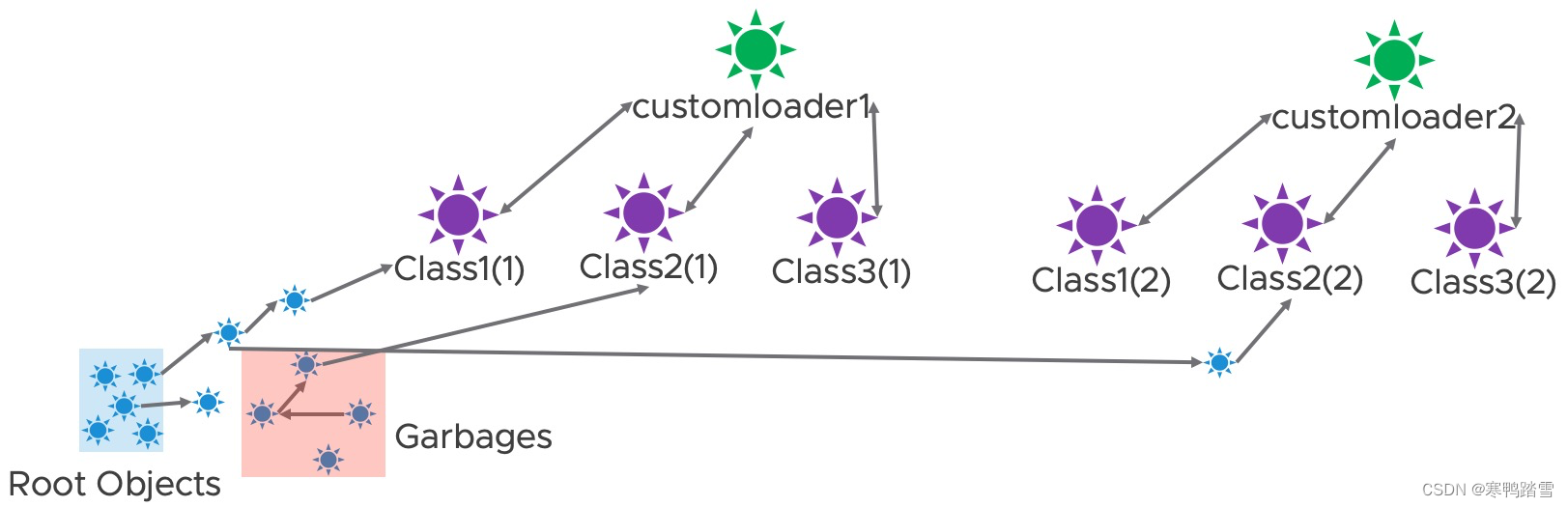 而此时,就会发生内存泄露,如下
而此时,就会发生内存泄露,如下
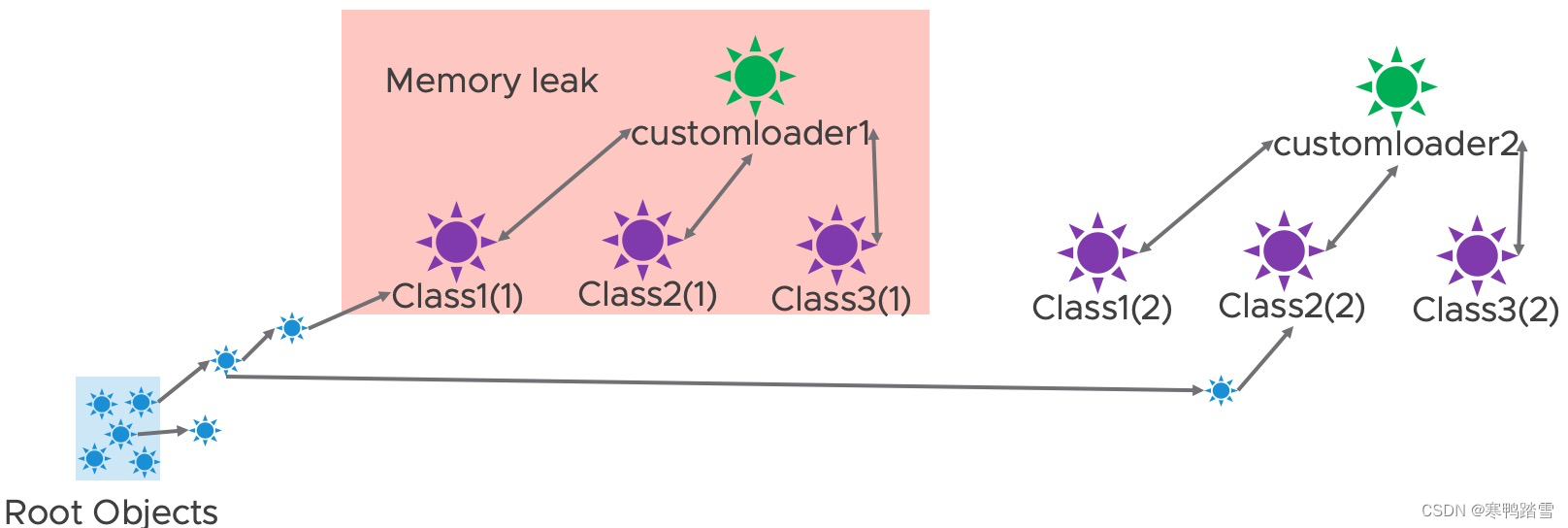
关于类加载器导致的内存泄露问题,详见(可能需要科学上网)http://frankkieviet.blogspot.com/2006/10/classloader-leaks-dreaded-permgen-space.html
解决内存泄露——方法一
直觉上,切断其它对象对垃圾对象的引用即可解决内存泄露问题。
因此,我们可以追踪所有customerloader1所加载的类生成的所有对象,并在ReplicaContainer.reload时将这些对象替换为customerloader2加载的类生成的对象,如下图
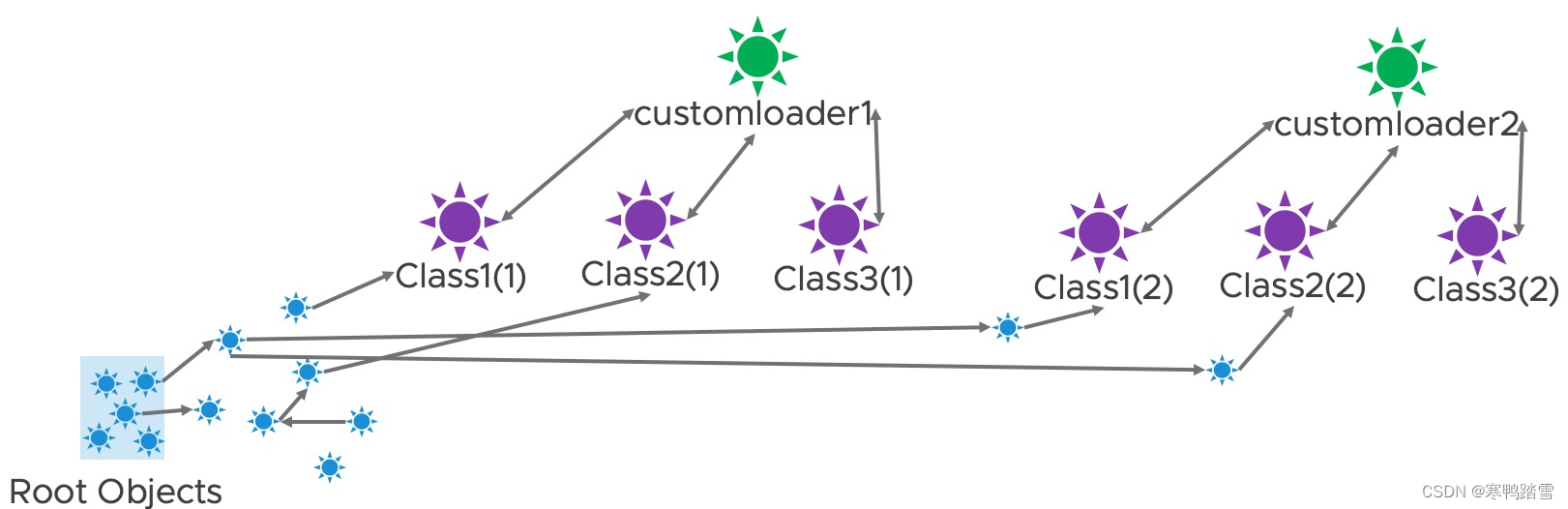
那么此时进行垃圾回收,就会有如下效果,不会产生内存泄露。
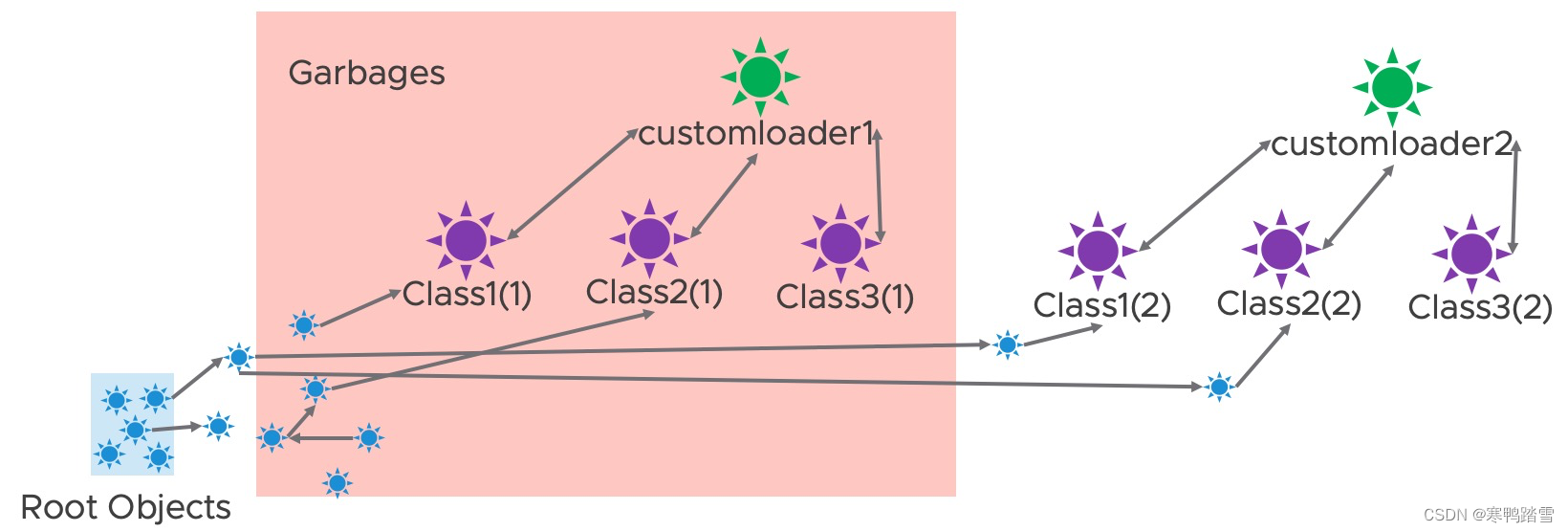
然而,追踪customloader1加载的类的所有对象几乎是不可能的,因此该方案不具有可行性。
解决内存泄露——方法二
毕竟我们只是为了升级GPText,也就是替换gptext-xxx.jar文件,因此,我们没必要重新加载WEB-INF/lib底下的所有jar文件。我们可以把gptext-xxx.jar放在其它文件夹,然后用自定义的类加载器去加载,并将jetty传过来的类加载器设置为自定义类加载器的双亲加载器,如下图(gptext-xxx.jar内的类不会在ReplicaContainer之外被加载和使用)
那么,调用ReplicaContainer.reload之后进行垃圾回收就会产生如下效果,不会产生内存泄露。
 当然,一旦WEB-INF/lib下的文件发生改动,比如升级了Solr,那么我们还是需要进行Rolling Upgrade的。不过这种情况仅占了GPText升级情况的不到十分之一。
当然,一旦WEB-INF/lib下的文件发生改动,比如升级了Solr,那么我们还是需要进行Rolling Upgrade的。不过这种情况仅占了GPText升级情况的不到十分之一。
测试内存泄露
理论上,采用方法二后即可避免内存泄露。但是光靠理论支持还不够,还需要进行测试。
测试垃圾回收时,我们采用了弱引用技术(WeakReference)。与平时使用的强引用不同,可达性分析时不会对弱引用所引用的对象标记为可达,因此该对象可能被标记为垃圾以便后续回收(但若弱引用的对象被其它root可达的对象强引用,依然会被标记为可达)。
关于弱引用,详见软引用、弱引用、虚引用-他们的特点及应用场景 - 简书
有了弱引用技术,在单元测试时,我们可以把代码中的ReplicaContainer替换成如下的ReplicaContainerForTest。由于reload中使用了弱引用,若没有发生内存泄露,则垃圾回收后原来的类加载器会被回收,使得弱引用所引用的对象变为null,通过assert语句的测试。
class ReplicaContainerForTest extends ReplicaContainer {
public ReplicaContainerForTest(ClassLoader parentLoader, String libPath) {
super(parentLoader, libPath);
}
public void reload() throws Exception {
WeakReference<CustomClassLoader> weakReference = new WeakReference<>(loader);
super.reload();
System.gc();// Can't guarantee that GC actually happens
assert weakReference.get() == null: "Memory leak in reloading classes!";
}
}
反之,若发生了内存泄露,则会使得assert的条件无法满足,从而抛出异常。
经过测试,笔者确实发现了内存泄漏!一番profile过后,笔者发现Solr源码中,对SolrCore进行reload的时候,会复用一个IndexDeletionPolicyWrapper对象,而这个对象又间接持有了SolrCore对象本身(循环引用),如下
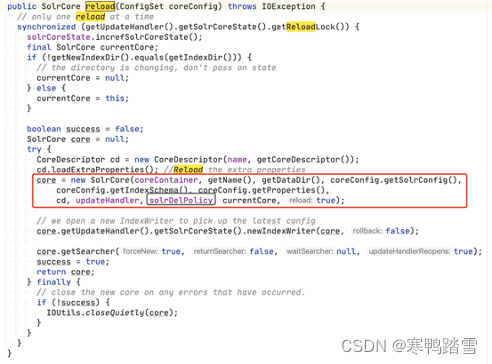
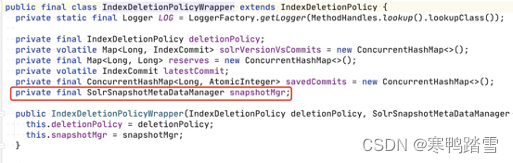
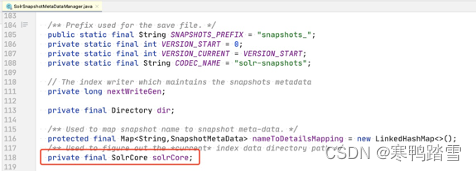
由于SolrCore对象中会含有gptext-xxx.jar内的类产生的对象,因此便有了内存泄露。要想解决这个内存泄露难度较高。IndexDeletionPolicyWrapper.snapshotMgr和SolrSnapshotMetaDataManager.solrCore都是private final类型的对象,因此只有使用反射才能进行替换。当然,也可以重写SolrCore.reload函数,然后不再复用solrDelPolicy对象。
由于这个solrDelPolicy对象会一直复用下去,因此不论调用ReplicaContainer.reload多少次,这里的内存泄露仅仅会出现一次,不会产生可观察的影响。为了防止对Solr源码进行较大改动产生风险, 笔者一番思索后决定在这里进行一下妥协,允许这个内存泄露。
为了通过内存泄露的测试,笔者对ReplicaContainerForTest进行了如下修改
class ReplicaContainerForTest extends ReplicaContainer {
protected boolean firstReload = true;
public ReplicaContainerForTest(ClassLoader parentLoader, String libPath) {
super(parentLoader, libPath);
}
// Need to invoke this method several times
public void reload() throws Exception {
if (firstReload) {
super.reload();
firstReload = false;
return;
}
WeakReference<CustomClassLoader> weakReference = new WeakReference<>(loader);
super.reload();
System.gc();// Can't guarantee GC actually happens
assert weakReference.get() == null: "Memory leak in reloading classes!";
}
}
用修改后的代码进行单元测试,未再发现其它内存泄露。
需要注意的是,理论上System.gc并不能保证垃圾回收一定会被执行,但据笔者所知,并没有理论上100%能执行垃圾回收的方式。笔者经过测试,在笔者环境中这里垃圾回收的执行率是100%。退一步讲,即便这里没有进行垃圾回收,也只会产生假阳性,不会产生假阴性,笔者认为可以接受(CI pipeline上对该测试设置重试机制即可)。
升级速度测试
| 单个Solr节点的replica数量 | 重启一个Solr节点所需时间(秒) | Reload一个Solr节点所需时间(秒) |
|---|---|---|
| 0 | 25.3 | 0.01 |
| 8 | 25.3 | 4.2 |
| 32 (典型值) | 36 | 14.5 |
| 64 | 58 | 27 |
| 128 | 111 | 58 |
有的读者可能会疑问,为何在Solr节点的replica数量为0和8时重启所需的时间一致。其实这里是程序检查的问题。在笔者环境中,不论replica数量有多少,重启一个Solr节点本身所需的时间为15秒左右。然而重启Solr节点后还需要进行ZooKeeper连接、选举leader等等操作,这个Solr节点才完全进入可用状态,而这些操作是没有同步API去等待其结束的。因此笔者只能写代码,每隔5秒去查询一次Solr节点的状态。加上各种损耗,会导致这里的时间有所偏差。考虑到Rolling Upgrade时也是采用类似方法去检查Solr节点状态,因此这里的比较并不会不公平。
读者可能还会有疑问,标题明明写了升级速度有10倍提升,为何这里只有1倍左右。因为reload时不需要重新进行zookeeper连接和选举leader,因此可以并行reload Solr节点而不会发生活锁的现象。此外,若升级过程中出现问题,也可以并行reload回原来的版本,时间较短,不会产生不可接受的down time。考虑到一个GPText集群通常有几十甚至上百个Solr节点,因此这里的速度提升其实远远超过了10倍!
注意,升级中过程中需要保证没有任何的请求在GPText中运行,防止产生一些同步方面的问题。
总结
通过动态加载技术,笔者用reload代替重启,既大幅降低了重启Solr节点所需的时间,又使得并行升级Solr节点成为可能,最终使得GPText的升级速度远远提高了10倍。

















 4333
4333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









