




本章主要从必要性、指标和工具等方面介绍RAG评估相关内容。
1 评估必要性
在我们实现RAG整个流程之后,最后一步就是我们如何评估我们的RAG最终的效果。这个其实任何大模型落地使用过程都需要做的一件事情,那么RAG有何不同。RAG最终的目的就是生成用户问题对应的答案,而整个RAG流程最重要的其实最重要的2方面分别:
- 检索质量:衡量RAG输入的上下文(Context)的质量。包括Hit Rate、MRR、NCDG等。
- 生成质量:针对在模型能否从上下文中生成连贯的、相关的答案。包括忠实度、相关性、无害、准确性等
对于大模型能力评估方法都是很通用,比如用户反馈、人工评估、利用大模型评估、自动评估等等。但是不同方法适合在不同阶段,且不同方法耗时耗力也不同,并没有什么方法说一定就是最好的。而对于RAG的评估的评估方法
- 独立评估(Independent Evaluation):其实很好理解独立评估方法会分别评估检索模块和生成模块进行评估
- 端到端评估(End-to-End Evaluation):端到端评估就是评估RAG模型对给定输入生成的最终响应,包括模型生成答案与输入查询的相关性和对齐程度
无论哪种评估方法,其中终将要对RAG的能力和质量的相关指标进行定义,以下就RAG相关能力和质量分数指标进行说明:
2 RAG评估指标
可以将RAG能力评估总结为4种基本能力和3种质量分数,主要参考论文《Retrieval-Augmented Generation for Large
Language Models: A Survey》:
2.1 四种基本能力
- 噪声鲁棒性
噪声鲁棒性(Noise Robustness):噪声鲁棒性评价模型处理与问题相关但缺乏实质性信息的噪声文件的能力。噪声文档定义为与问题相关但不包含任何相关信息的文档。这个能力主要评估RAG的检索相关性,生成能力(处理缺乏实质性相关的检索内容)。 - 负样本拒绝能力
负样本拒绝能力(Negative Rejection):当检索到的文档不包含回答问题所需的知识时,模型应拒绝回答问题,也就是LLM预计会发出"信息不足"的拒绝回答信号。这个能力主要评估RAG的生成能力(处理不相关的检索内容)。 - 反事实的鲁棒性
反事实鲁棒性(Counterfactual Robustness):该测试评估当通过指令向大模型发出关于检索信息中潜在风险的警告时,模型能否识别检索文档中已知事实错误的风险。这个能力主要评估RAG的生成能力(处理有问题的检索内容)。 - 信息整合能力
信息整合(information integration):评估模型能否回答需要整合多个文档信息的复杂问题。这个能力主要评估RAG的生成能力(整合检索内容能力)。
2.2 三种质量分数
- 上下文相关性
上下文相关性(Context Relevance):检索得到的上下文与输入问题的相关性,也就是检索结果应重点突出,尽可能少地包含无关信息。这个质量分数主要评估RAG的检索能力。 - 回答真实性
答案真实性(Answer Faithfulness):评估生成的答案与检索结果是否一致性,也就是答案是基于给定的检索结果,而非胡乱生成的。这个质量分数主要评估RAG的生成能力。 - 回答相关性
答案相关性(Answer Relevance):评估生成的答案与问题之间是否有直接相关。这个质量分数主要评估RAG的生成能力。
2.3 总结
在论文中,针对前面四种能力和三种质量分散,给出来传统指标如何去评价这几种能力。
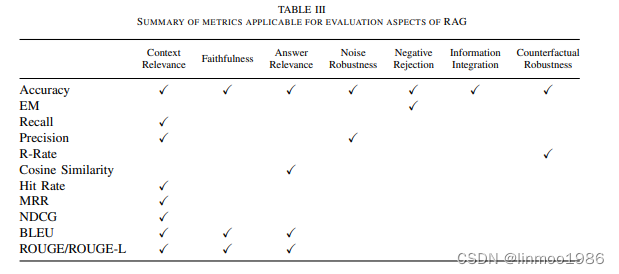
但这并不是RAG评估的最好的方案,在论文中,提出目前更好的评估基准和工具,基准的主要贡献在于构造指标和数据集,可以评估RAG各方面基本能力,一些典型基准如RGB、RECALL、CRUD等。RAG评估的工具大多数采用大模型进行评估,典型如RAGAS 、ARES和TruLens等。如下表:
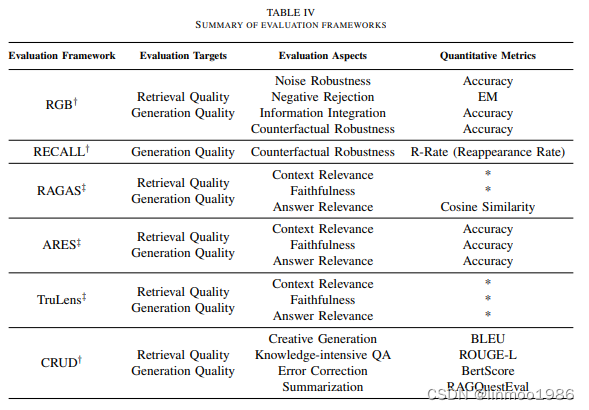
3 评估工具
所谓工欲善其事,必先利其器。下面就目前流行的几个评估工具进行简单的说明和使用。
3.1 RAGas
GitHub地址:https://github.com/explodinggradients/ragas
Ragas(Retrieval-Augmented Generation, RAG)Ragas是一个框架,可以帮助您评估检索增强生成(RAG)管道。Ragas提供了专门针对不同类型的embeddings的评估方法,例如对主流的OpenAI embeddings和BGE (Big Generative Models) embeddings等进行评估。此外,Ragas还提出了五种评估指标,包括答案真实性、答案相关性、上下文精度、上下文召回率和上下文相关性,这些指标旨在量化评估检索增强生成(Retrieval-Augmented Generation, RAG)流程的性能。因此它特别适用于评估RAG应用。
3.2.1 代码演示
这里使用智谱的API和ragas演示
前提条件:
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 设置hugging face镜像,export HF_ENDPOINT=https://hf-mirror.com。因为要从上面下载demo数据集
- 安装ragas:pip install ragas
from langchain_openai import ChatOpenAI
from ragas import evaluate, RunConfig
from ragas.metrics import faithfulness
from datasets import load_dataset
# 前置工作1:创建llm
llm = ChatOpenAI(
temperature=0.3,
model="glm-4",
openai_api_key="05f9fe2491eef6c3a7c2659957880e86.V7LJzSgrEK7raanZ",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:加载数据集
amnesty_qa = load_dataset("explodinggradients/amnesty_qa", "english_v2")
# 只取eval数据集的1条做实验
amnesty_qa = amnesty_qa["eval"].select([0, 0])
# 第二步设置一个run_config的thread_timeout,貌似glm-4比较慢,会导致线程超时
run_config = RunConfig()
run_config.thread_timeout = 300
# 第三步:调用evaluate
'''
注意,由于ragas里面的temperature默认是1e-8,这个在智谱AI的API会报错,有2种方法
1)使用调式模式,在调用API处self._post手动改0.01
2)下载ragas源码,修改写BaseRagasLLM里面async def generate,在自己编译
'''
result = evaluate(amnesty_qa, metrics=[faithfulness], llm=llm, run_config=run_config)
print(result)
3.2 ARES
GitHub地址:https://github.com/stanford-futuredata/ARES
ARES是一个开创性的框架,用于评估检索增强生成(RAG)模型。ARES对检索增强生成(RAG)模型进行全面评估,评估系统的上下文相关性、答案忠实度和答案相关性。ARES采用合成查询生成和预测驱动推理(PPI),提供具有统计置信度的准确评估。论文作者第一个为 RAG pipeline 的每个组成部分量身定制的 LLM 判断的自动化 RAG 评估系统 ARES(Automated RAG Evaluation System)。
3.3 TruLens
GitHub地址:https://github.com/truera/trulens
trulens是TruEra公司的一款开源软件工具,它可帮助您使用反馈功函数客观地评估基于 LLM 的应用程序的质量和有效性。反馈函数有助于以编程方式评估输入、输出和中间结果的质量,以便我们可以加快和扩大实验评估,并将其用于各种应用场景,包括问答、检索增强生成和基于代理的应用程序。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











