




我认为大脑本质上就是一台计算机,而知觉和意识则像是计算机程序,也会随着计算机的关闭(人的死亡)而停止。理论上,这些知觉和意识是可以重新创造于一个神经网络中的,但是这太难了,因为这将需要一个人所有的记忆。 ——史蒂芬·霍金
出于对更高生产力的追求,人类从未停止发明新的工具以帮助其更快/更好的完成工作;从而可以每天什么都不用做,躺在家里的沙发上。这些工具有的可以提高人类的工作效率,有的则可以替代人类的工作。当下的人们似乎对于后者更感兴趣,才萌生了试图让计算机像人类一样拥有学习能力的想法,使计算机变得更像一个生命体。(生命体具备的特征:自我复制,不断学习,自我管理,一定程度自我修复)和其他很多的发明一样,神经网络的发明也同样来自于大自然带给人类的灵感。人类的学习/认知/或者决策行为,实际上是群体行为,大脑其实为此乱做一团,而其中个体,则是神经元。神经元与神经元直接或者间接连接并保持沟通,神经元若是认为是时候的话,则会向相应的其他神经元发送电流进行信号传输,随后可能如同链式反应一样,最终反应到人类最表层的意识。
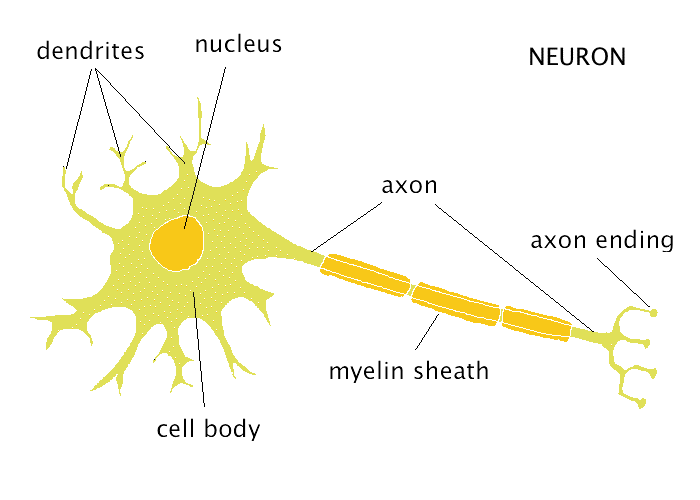
随着计算机运算能力的逐步突破,人类不禁试图将大脑这“天工之作”仿造在计算机之上,也就创造了当今的神经网络架构。受益于Google Alpha Go和Tesla自动驾驶伤亡事故的媒体传播,神经网络这两年逐渐进入大众视野,但是其思想实则起源于上世纪40年代,神经元计算模型初次面世。但是由于最初的神经元模型只能进行正向的传播运算,并不具备从结果学习的能力,所以不能算作真正的智能。上世纪80年代末,反向传播算法面世,使得神经网络能够根据样本结果反向修正各神经元的计算行为,从而使得神经网络真正有了学习的能力。反向传播也成了神经网络的核心思想,但是苦于当时并没有足够强大的计算机,该思想和模型并没能够广泛应用于实际的场景中。而如今,在有了足够强大的计算能力的情况下,神经网络的实现已经可以走入寻常百姓家,不仅验证了三十年前神经网络思想的正确性,近年来也有很多新的网络架构被发明出来。其在诸多人工智能课题中的表现甚是抢眼,甚至端了很多传统机器学习算法的饭碗,稳得一X。
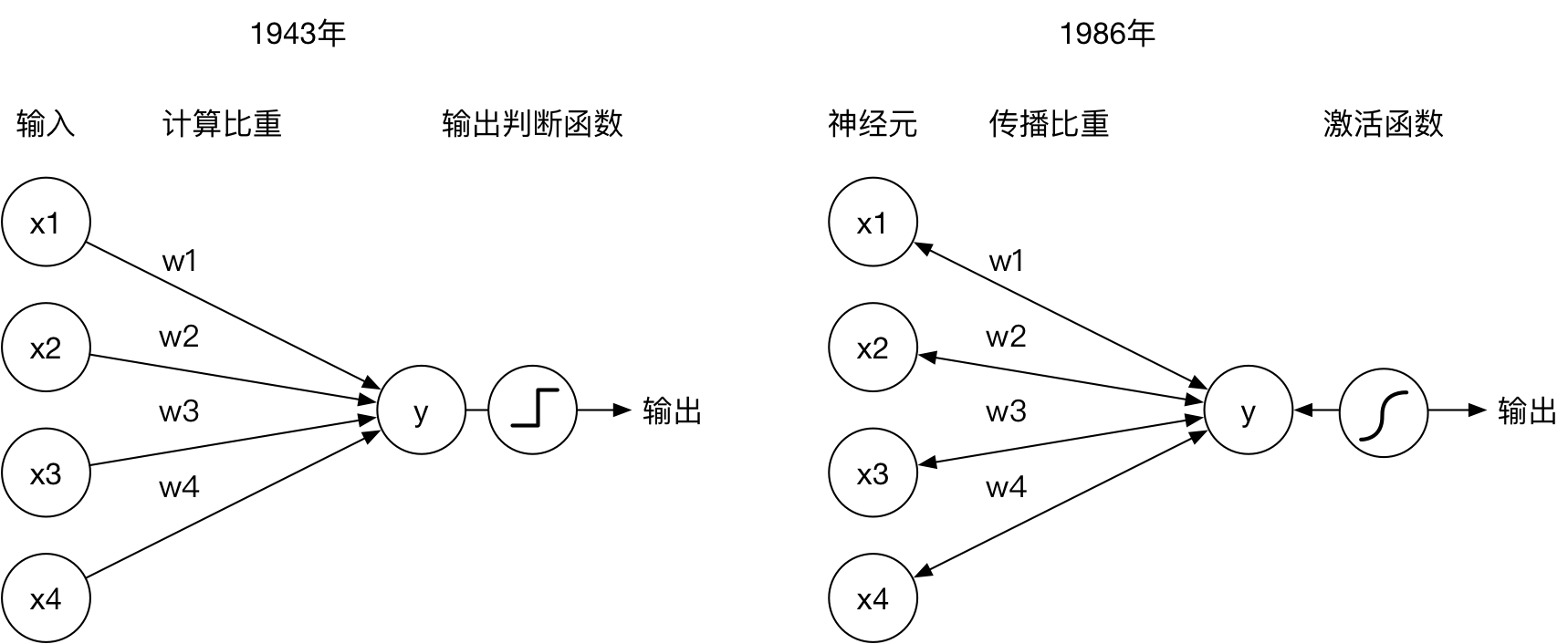
稍微技术一点来说,神经网络可以被理解为一个函数,与其他所有函数一样,给定输入参数,即可返回输出结果。一个复杂神经网络中可能包含成数以万计的神经元,而每个神经元则被模拟为储存单个数值的变量。神经元既可以用作输入 x,也可以用作结果 y,神经元之间的信息传播被模拟成了输入 x 与神经元之间相连的传播权重 w 的运算过程。与生物神经元一样,通常神经元不会直接把上一层传递来的信息不加思索地传给它的下一层神经元,而是经过一番判断来决定是否进行信号发送以及发送什么样的信号,神经网络将此行为定义为神经元的激活。以上图右侧为例,神经网络的输入为(x1, x2, x3, x4),则神经元 y 的输入为:
y(in) = x1·w1 + x2·w2 + x3·w3 + x4·w4 + b= Σ(xi·wi) + b
其中 b 为偏重值,神经元 y 的输入则为:
y(out) = f(y(in))
其中 f 为激活函数。
以上描述的就是一个拥有5个神经元的神经网络(感知器)的一次正向传播。然而这个神经网络所计算出来的输出结果可能并非所愿,因为我们并不知道权重 w 和偏重 b 的值,目前的这些权重都只是猜测而已。为了使这个神经网络正常工作,我们则需要用大量的输入以及相对应的已知输出结果来不断修正这些值,直到神经网络能够有比较好的表现。这个过程即为反向传播,修正过后的权重和偏重则是神经网络模型中重要的一部分。
实际应用中,神经网络通常除了输入层和输出层之后,还会有1个或多个隐藏层,用于记录计算中途的隐性特征信息,可以理解为潜意识,或者脑路。我们不一定需要知道潜意识里到底发生了什么,但是需要它。
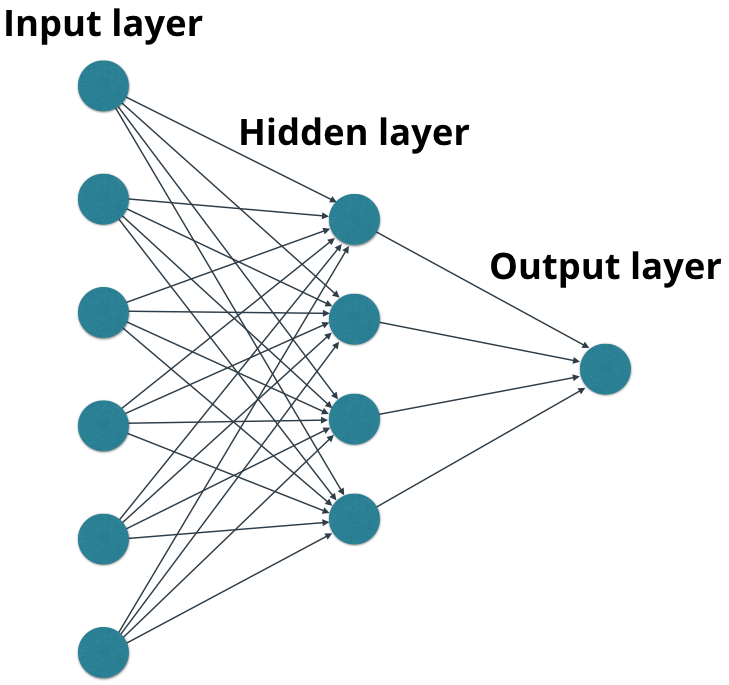
神经网络的应用可谓五花八门,凡是模棱两可,乍看令人抓耳挠腮,却实际有很多历史数据的问题,都可以用神经网络尝试一下。常见的成功用例有:
- 模式识别
- 商务分析
- 风格迁移
- 自动驾驶
- 吟诗作对
- 机器翻译
- 内容总结
- 人机AI
- 内容推荐
- 编码压缩
- 图片降噪
盗图一张(调皮):
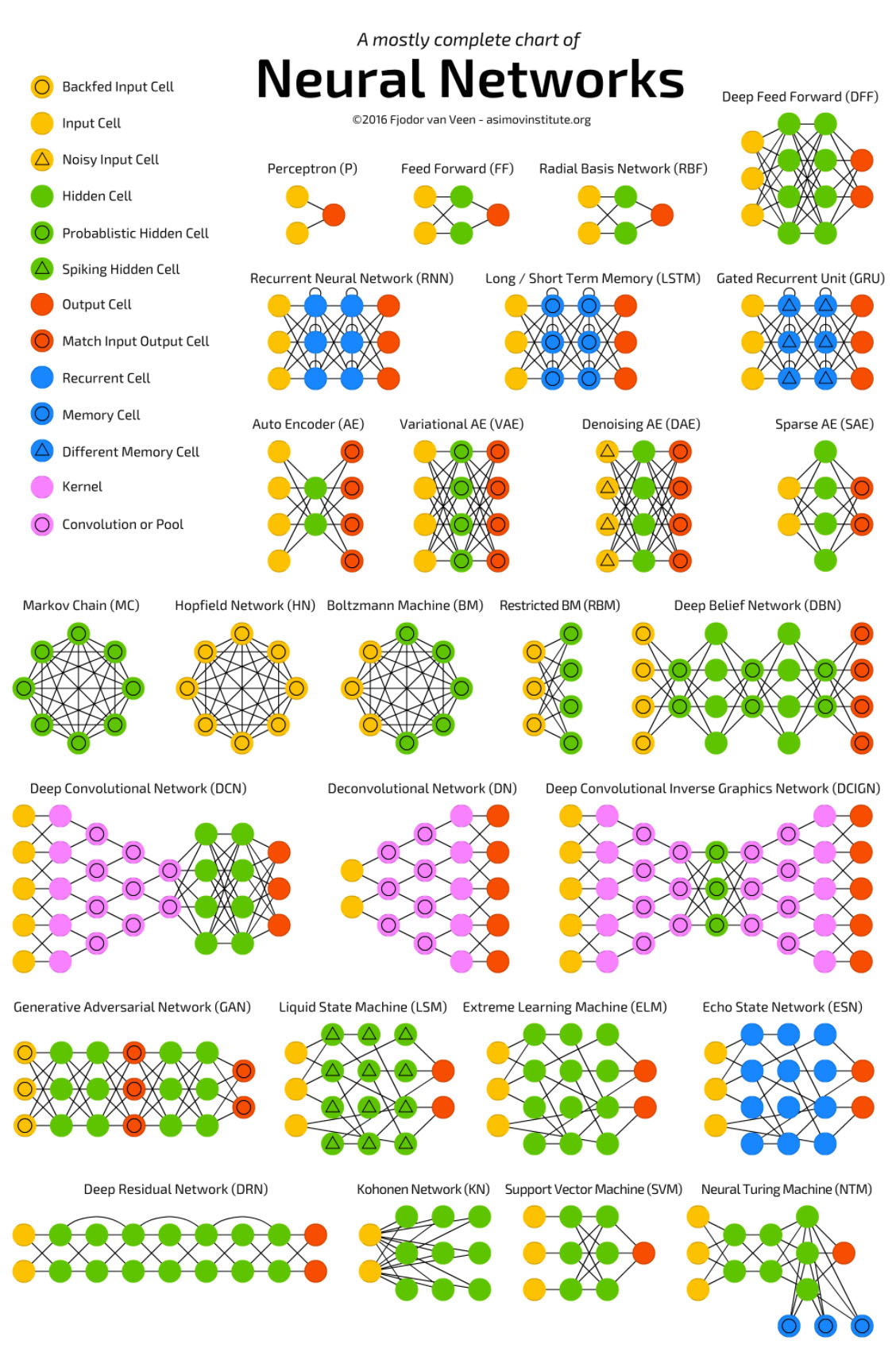
怎么样,是不是迫不及待想要自己摸一摸
本文的意图在于开一个坑,免得自己偷懒。将在随后记录分享深度学习知识,内容既会包含模型结构和算法原理解析,也会包含具体的神经网络实现。大致会提到以下网络类型:
- 深度正向传播:简单的分类
- 自动编码:教会计算机手写数字
- CNN:图像识别
- RNN:趋势预测
- LSTM:语义分析
- GAN:内容生成

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









