




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 国产TRAE打造web应用
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
对于许多技术初学者而言,“全栈开发”是一座遥不可及的大山。本文将记录一次独特的开发之旅:我先忘记自己所有的技术经验,把自己当做一个技术小白,我将尝试仅依靠国产AI开发助手 TRAE,从零开始构建一个功能完备的“AI Chat”Web应用。项目将实现用户注册登录、数据持久化存储以及与豆包大模型API的实时对话等核心功能。
我们将深入探索如何利用TRAE的 智能体(Agent)进行项目规划与代码生成,如何通过其创建MCP(Model Context Protocol)无缝对接MySQL数据库,以及如何运用上下文与项目Rules来确保AI在整个开发周期中保持逻辑一致性。本文旨在验证一个大胆的设想:在先进AI工具的加持下,一个新手开发者是否真的能“一镜到底”,独立完成一个现代化的全栈Web应用?
本次实战我在此强调的是使用国内版本的TRAE,虽然国外的版本能使用国外的大模型,但是对于我来说,国内的大模型已经足够满足我的使用,而且没有任何不适。
最终成果展示:
-
首页:
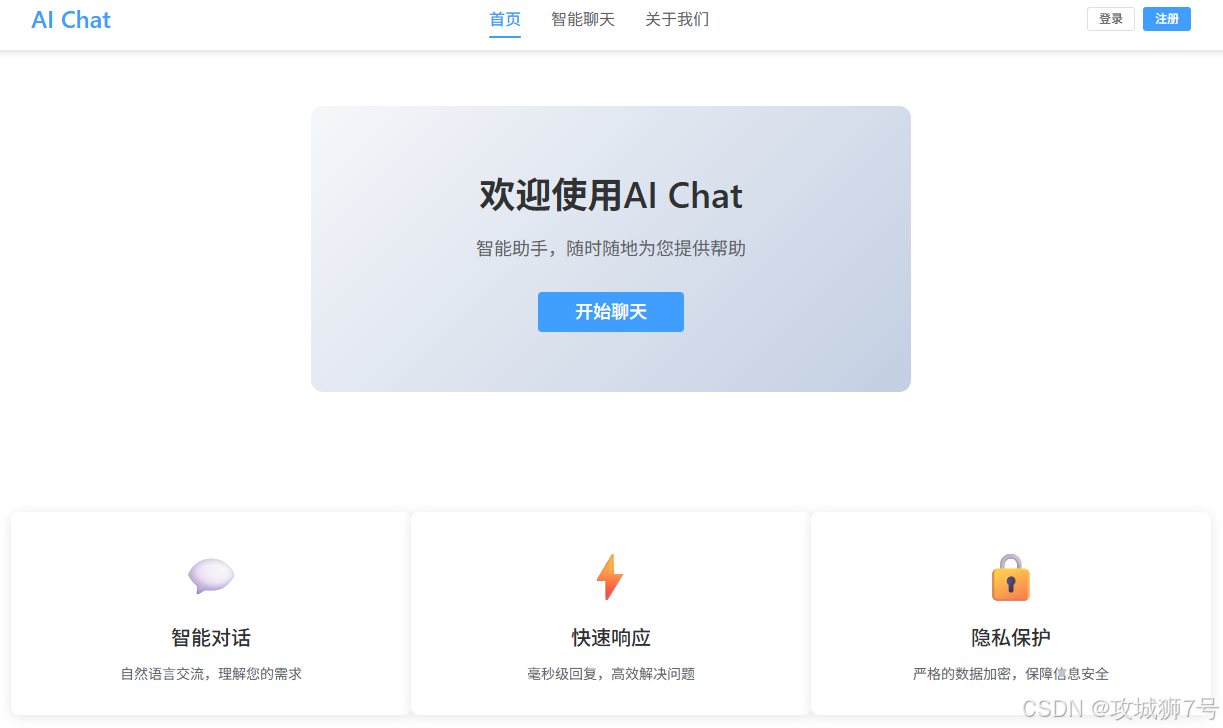
-
登录/注册页面:
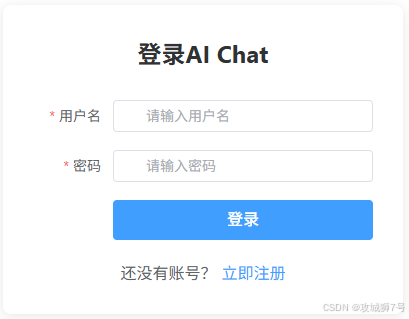
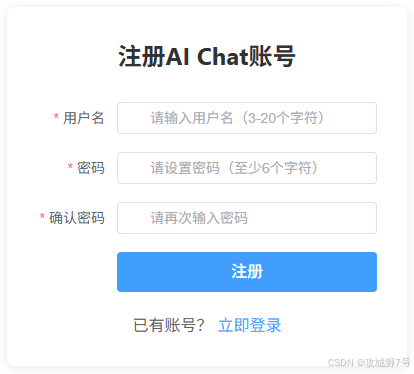
-
核心聊天界面:
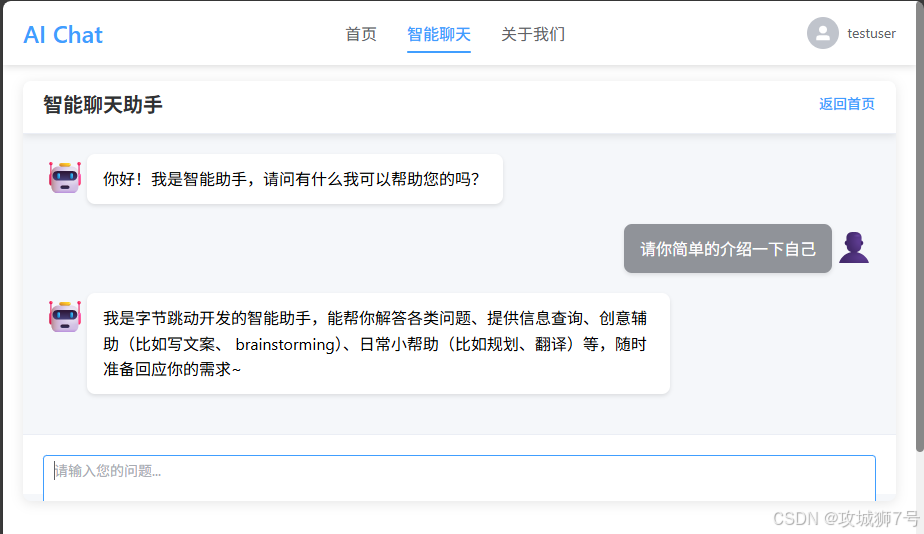
(注:以上图片为效果示意图)
一、 项目准备:兵马未动,粮草先行
在开始编码(或者说,开始“指挥”AI编码)之前,我们需要确保开发环境和所需工具都已准备就绪。这就像是烹饪前备好所有食材和厨具,能让整个过程更加顺畅。
1.1 本地开发环境
-
Node.js: 这是我们整个技术栈的基石,无论是前端的Vite还是后端的Koa,都依赖于它。我使用的是
v18.20.8,建议使用v16或更高版本。 -
MySQL: 我们选择的数据库。我本地安装的是 8.0 版本。你需要确保数据库服务已启动,并创建一个用于存放项目数据的数据库(例如,我创建了一个名为
doubao_clone的数据库)。 -
TRAE 客户端: 本次挑战的主角。我使用的是 v2.9.1 国内桌面版。它看起来像一个集成了超级AI能力的IDE,你可以在其中创建项目、编写代码、管理上下文,并与AI智能体进行交互。
1.2 云服务与API密钥
-
豆包大模型API Key: 这是让我们的应用拥有“灵魂”的关键。你需要前往豆包开放平台(或其背后的火山引擎)注册并进行大模型试用接入API,获取到API Key。这是调用大模型服务的凭证,务必妥善保管。
1.3 我的心态准备与思考
现在把自己当做一个技术小白,我深知自己对很多技术细节一知半解。因此,在开始前我为自己设定了两个原则:
-
信任但验证:我将尽可能把任务交给TRAE,相信它的能力。但我不会盲从,对于生成的代码,我会尝试去理解其核心逻辑,并在浏览器和终端中验证其运行结果。
-
沟通大于编码:我意识到,使用AI开发助手的核心技能,可能已经从“如何写代码”转变为“如何精确地向AI描述我的需求”。我将把每一次与TRAE的交互,都看作是一次产品需求沟通。
二、 奠定基石:与TRAE共建项目框架
万丈高楼平地起,一个好的项目结构是成功的开端。我没有自己动手创建文件,而是决定让TRAE来完成这项工作。
2.1 初始化TRAE工作区与设定Rules
启动TRAE后,我创建了一个新的项目工作区,命名为 doubao-clone-project。
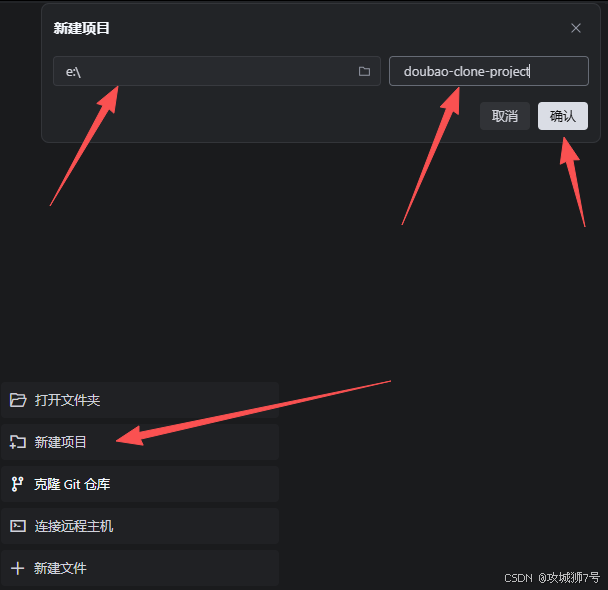
TRAE最强大的功能之一就是“项目Rules(规则)”。这相当于给整个项目设定了一个“宪法”,所有后续AI的生成和修改都会遵循这个顶层设计。当然,规则不会写,也可以叫智能体帮你设计。
我打开Rules编辑器,输入了以下核心指令:
# 项目顶层规则
## 1. 技术栈规约
- **项目类型**: 全栈Web应用,前后端分离。
- **前端**: 使用 Vue3 (组合式API, script setup语法糖), TypeScript, Vite构建工具, Pinia作为状态管理, Vue Router进行路由管理, UI库使用Element Plus。
- **后端**: 使用 Koa.js 框架, Node.js环境, 使用PM2进行进程管理。
- **数据库**: MySQL 8.0。
## 2. 项目结构
- 在根目录下创建 `frontend` 和 `backend` 两个文件夹,分别存放前后端代码。
- 前后端项目均需包含完整的 `package.json` 依赖文件。
- 后端应有清晰分层:`routes` (路由), `controllers` (控制器), `services` (服务逻辑), `models` (数据模型)。
## 3. 代码风格
- 所有代码遵循 Prettier 格式化标准。
- TypeScript 开启严格模式。
- 所有函数和关键逻辑需添加JSDoc注释。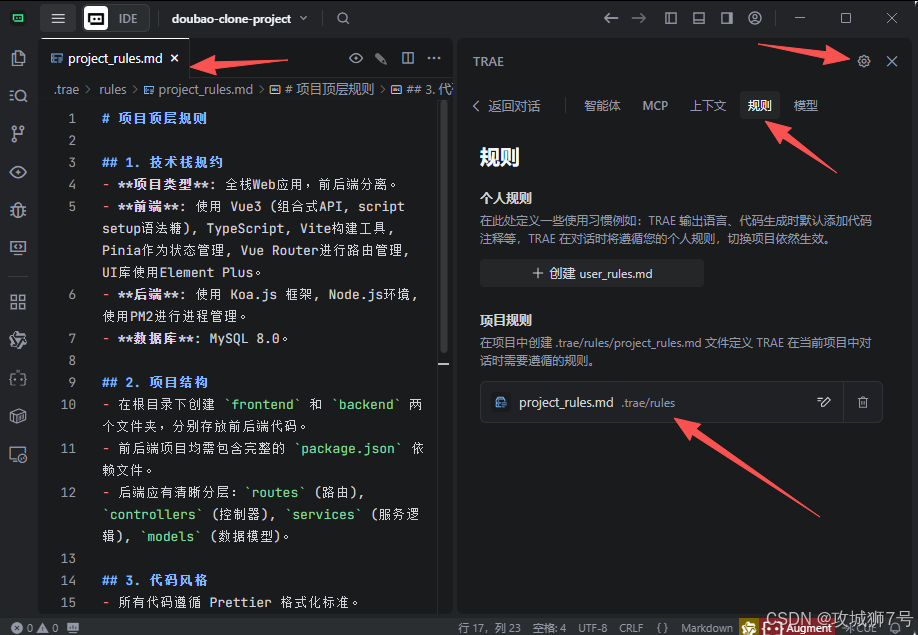
个人经验总结:
设定Rules是我认为最关键的一步。这就像是给AI画了一个清晰的“沙盘”,它之后的所有行动都会在这个沙盘内进行,极大地避免了AI因自由发挥而导致的结构混乱。规则越明确、越具体,后续的开发过程就越顺畅。对于新手来说,这解决了“项目应该如何组织”这个最头疼的问题之一。
2.2 创建智能体(Agent)并生成项目骨架
接下来,我使用了TRAE的“智能体”功能。智能体可以被理解为被赋予了特定角色的AI。我创建了一个名为“全栈架构师”的Agent,并向它发出了第一个指令:
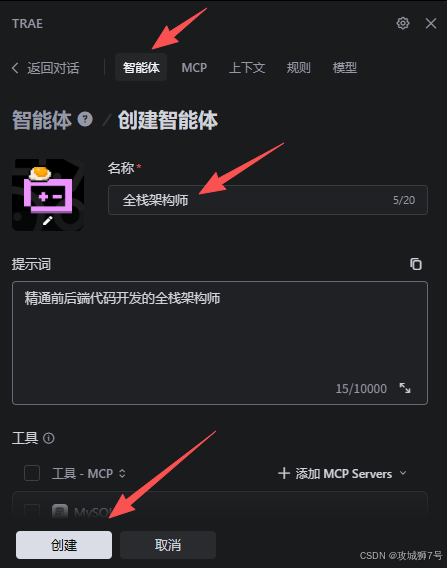
指令如下:
“你好,请根据项目Rules,为我生成
doubao-clone-project的完整前后端项目骨架文件。”
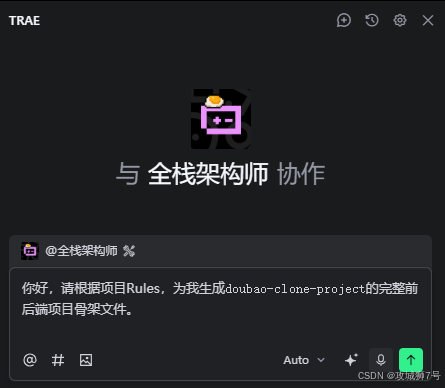
现在TRAE已经开始工作,现在的你完全可以坐在一边喝杯咖啡,静等完成,不久之后你会看到电脑右下角弹出消息框,意识已经完成任务
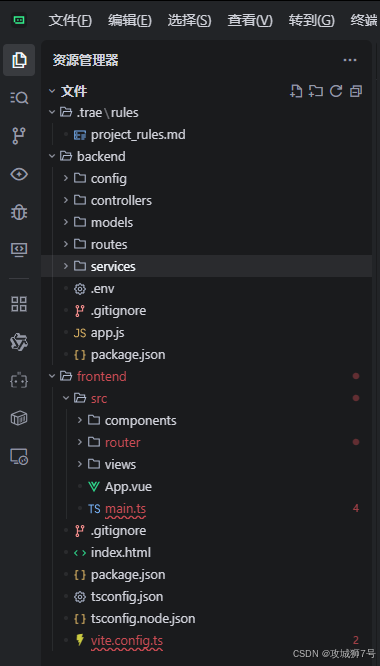
现在,TRAE的侧边栏文件树焕然一新,一个标准的、结构清晰的全栈项目诞生了:
doubao-clone-project/
├── frontend/
│ ├── public/
│ ├── src/
│ │ ├── assets/
│ │ ├── components/
│ │ ├── router/
│ │ ├── store/
│ │ ├── views/
│ │ ├── App.vue
│ │ └── main.ts
│ ├── index.html
│ ├── package.json
│ ├── tsconfig.json
│ └── vite.config.ts
├── backend/
│ ├── src/
│ │ ├── controllers/
│ │ ├── models/
│ │ ├── routes/
│ │ ├── services/
│ │ ├── app.js
│ │ └── db.js
│ ├── package.json
│ └── ecosystem.config.js
└── ...你可以先点击接受所有更改,后面完全可以再优化修改就行
TRAE不仅创建了文件和文件夹,还为package.json填充了必要的依赖(如 vue, koa, mysql2 等),并生成了Vite和Koa的基础配置文件。我只需要进入frontend和backend目录,分别执行npm install,项目的基础环境就搭建完毕了。
三、 后端先行:构建稳固的数据与逻辑服务
有了骨架,我们先从后端开始,因为它为前端提供了数据和服务支持。
3.1 使用MySQL MCP连接数据库
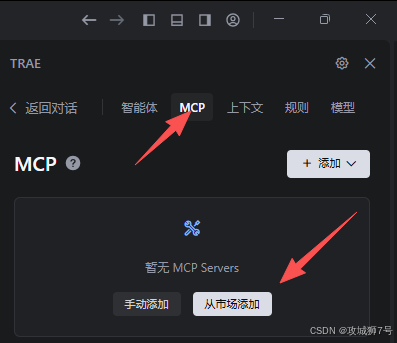
TRAE的MCP(Model Context Protocol,模型上下文协议)功能让我大开眼界。它提供了一个可视化的界面,用于连接和管理外部服务,如数据库、API等。
我打开MCP面板,选择从市场添加,直接搜索“MySQL”。这个工具能帮我们自动连接数据库,自动进行各种表操作。如下操作:
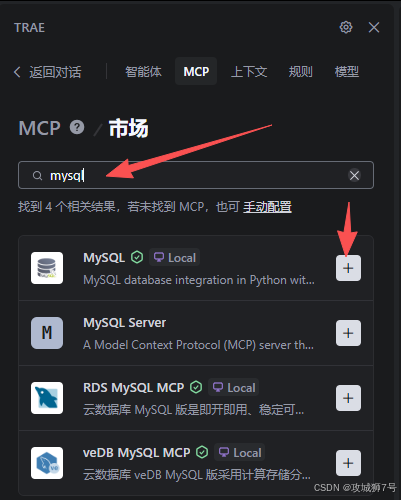
然后如下在一个表单中填入了我的本地数据库信息:
-
Host: localhost
-
Port: 3306
-
User: root
-
Password: [我的数据库密码]
-
Database: doubao_clone

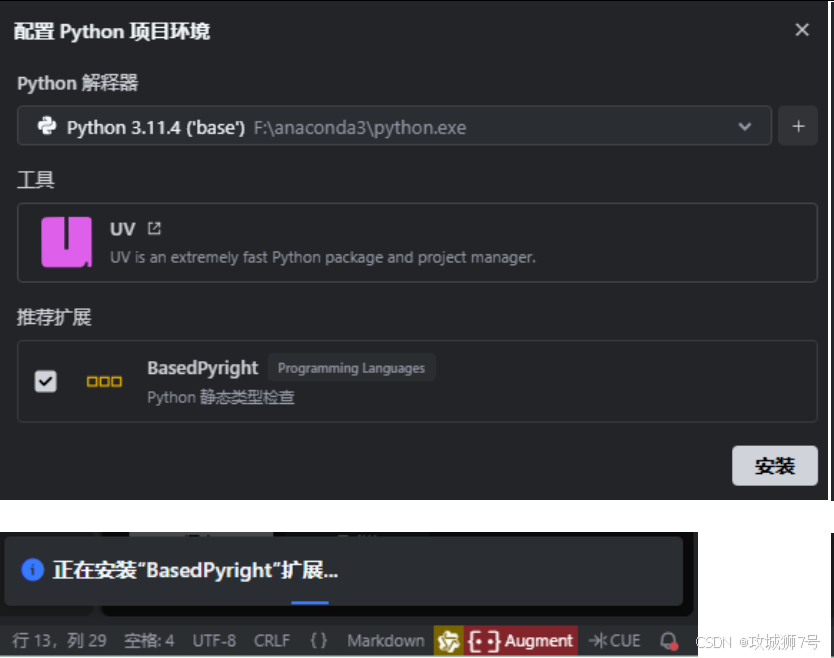
第一次添加MCP会提示安装依赖环境,流程都是自动操作,只需点击确认操作即可
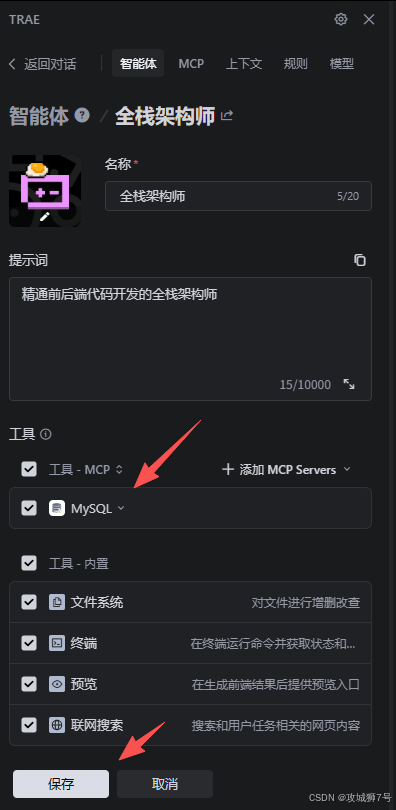
接着在自己自定义的智能体中添加刚才添加的MCP即可
如果一直提示找不到命令uvx,那么只要出现如下提示:
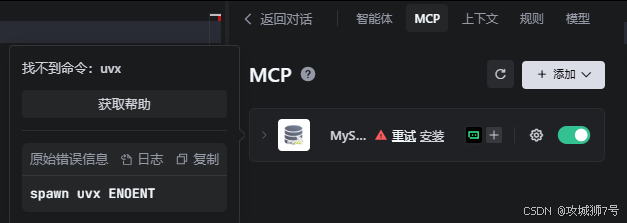
那么请看这个解决方案:https://docs.trae.ai/ide/model-context-protocol?_lang=zh
这个解决方法就是安装uvx命令,如下:
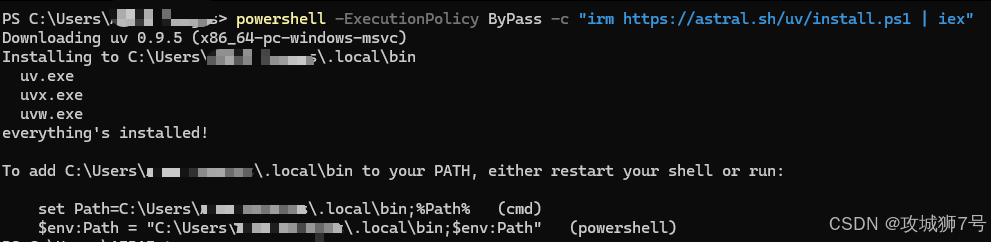
安装成功后,就能看见MCP是可用的状态
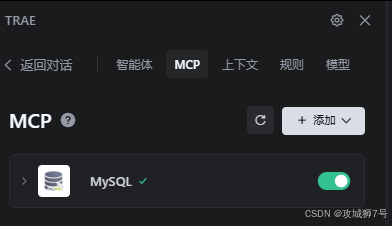
保存后,这个连接就被命名为 MySQL。接着,我回到与“全栈架构师”Agent的对话中:
“请在后端项目中,基于MCP中的 MySQL 连接,编写数据库初始化和连接的代码。”
TRAE立即修改了 backend/src/db.js 文件,生成的代码自动从一个安全的配置文件中读取了连接参数,并创建了一个数据库连接池。这避免了将敏感信息硬编码在代码中的安全风险。但是智能体也自动给我弄了几张新数据库表,但是没关系,我可以先全部接受,后面继续改。
个人经验总结:
MCP功能对于新手极其友好。我不需要去查阅
mysql2库的文档,思考如何创建连接池、如何处理异常。我只需要提供最基本的信息,TRAE就帮我完成了最佳实践的代码实现。这种“声明式”的开发方式,让我可以更专注于业务逻辑本身。
3.2 设计用户表并实现注册/登录接口
接下来是用户系统的核心功能。我继续向Agent下达指令:
“现在我将构建一个功能完备、高度仿真的类似“豆包”Web应用。项目将实现用户注册登录、数据持久化存储以及与豆包大模型API的实时对话等核心功能。现在把之前没必要的表删掉,先按下面要求执行:
请为我设计一个用户表
users,包含id(主键,自增),username(唯一,非空),password(非空),created_at(创建时间) 字段。请生成对应的SQL建表语句。基于这张表,使用Koa,在
/api路径下实现用户注册 (/register) 和登录 (/login) 的API接口。注册时,密码需要使用
bcrypt进行加密存储。登录成功后,使用
jsonwebtoken(JWT) 生成一个token返回给前端。”
这个指令比较复杂,但我试图一次性把需求描述清楚。TRAE的执行过程让我印象深刻:
1. 它首先在聊天窗口中返回了CREATE TABLE的SQL语句,并自动在MCP MySQL 中执行,帮我在数据库中创建了users表。
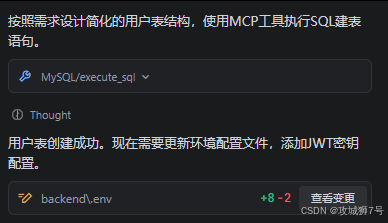
用数据库连接工具一看,确实自动创建了users表
2. 接着,它开始在 backend 项目中创建和修改文件。它创建了 user.controller.js, user.service.js, user.model.js 和 auth.routes.js,将逻辑清晰地分层。
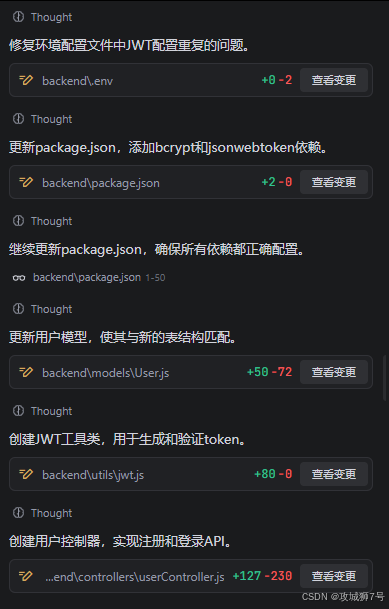
3. 它在package.json中自动添加了 bcrypt 和 jsonwebtoken 依赖,并提示我需要重新执行 npm install。
4. 生成的代码中,注册逻辑包含了用户名是否已存在的校验,密码加密的完整流程;登录逻辑则包含了用户校验、密码比对和JWT签发。
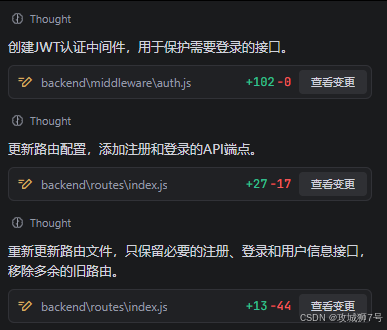
整个过程,我几乎没有编写一行代码,一个安全、标准的认证授权系统后端就完成了。
然而出人意料的是,TRAE居然把后面的前端部分也一起做了,它不仅生成了完整的Vue组件代码,包括CSS样式,还处理了数据流的接收和渲染逻辑。
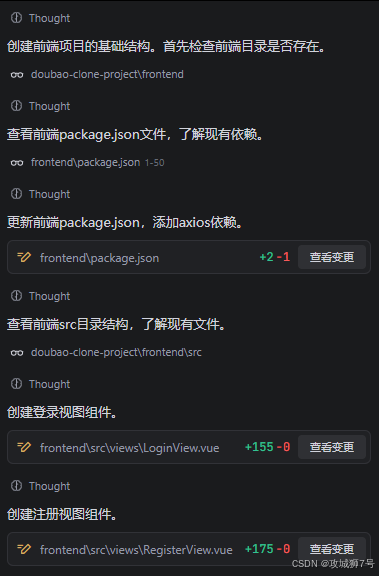
而且还对自己的实现做了总结


至于对不对,我们都先不管,后面可以继续调整。
还有上一步的编写数据库初始化和连接的代码命令会自动在backend\scripts\dbInit.js下创建多余的数据库表,自己继续下达指令修改dbInit.js,这个文件交接给新人初始化项目的时候很重要。
dbInit.js 暂时只用到一个用户表 users ,包含 id (主键,自增), username (唯一,非空), password (非空), created_at (创建时间) 字段。其他表没用的可以删掉
四、 前端呈现:打造精致的用户交互界面
后端准备就绪,现在轮到前端了。
4.1 搭建路由与状态管理
我向Agent发出了新的指令:
“现在继续排查前端实现部分,看看有没有实现如下功能,对比你的实现取最优方案:使用
vue-router设置路由,需要包含/login,/register和/chat三个页面。/chat页面需要进行路由守卫,只有在用户已登录(即Pinia中有token)的情况下才能访问,否则重定向到/login。同时,使用pinia创建一个userStore,用于管理用户的token和基本信息。”
TRAE迅速地在 frontend/src/router 和 frontend/src/store 目录下创建了相应的文件,并编写了所有配置代码。路由守卫的逻辑也写得非常完善。如下所示:

4.2 开发注册与登录页面
接下来是UI组件的开发排查。
“继续排查前端实现部分,看看有没有实现如下功能,对比你的实现取最优方案:使用 Element Plus UI库,创建登录和注册页面的Vue组件。要求包含输入框和提交按钮,并实现与后端API的交互逻辑。登录成功后,将返回的token和用户信息存入
userStore,并跳转到/chat页面。”

TRAE生成了 LoginView.vue 和 RegisterView.vue 两个文件。文件不仅包含了使用了 el-form, el-input, el-button 等组件的模板代码,<script setup> 部分也已经引入了 axios (它自动添加的依赖),编写了完整的表单提交、API调用、错误处理、状态更新和页面跳转逻辑。
个人经验总结:
这一步让我感受到了AI在前端开发中的巨大潜力。UI组件的开发往往包含大量重复的模板代码和表单逻辑,非常耗时。TRAE的生成能力极大地解放了我的双手。更重要的是,它生成的代码是基于我之前设定的后端API逻辑,前后端在这里实现了完美的“握手”。这得益于TRAE强大的上下文记忆能力,它记得我们之前是如何设计后端接口的。
五、 核心对话功能:让应用拥有“灵魂”
现在,万事俱备,只差最核心的聊天功能了。
5.1 后端代理豆包API
我们需要先登录火山引擎官网: https://www.volcengine.com/product/doubao。
如果亲还没注册就先注册登录,点击开启AI新体验,如下:
然后我们在网页的左下角看到每个模型都有免费的使用额度,我们就先用免费的额度做测试即可。如下点击第一个模型的API接入:
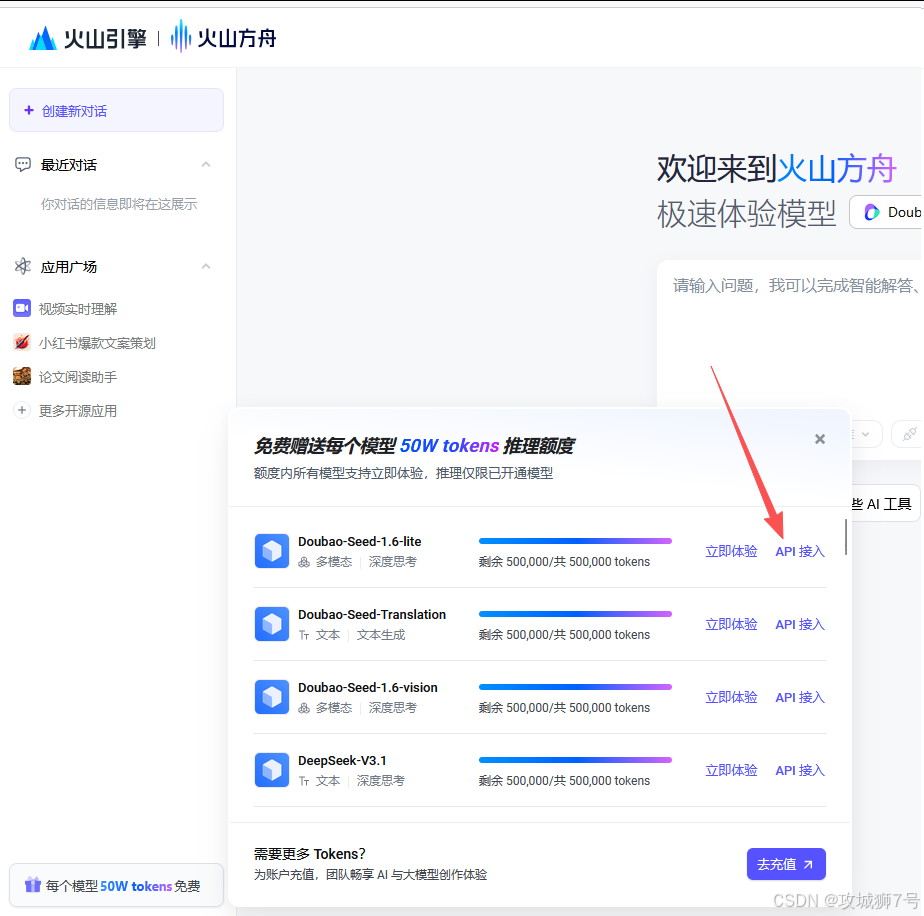
为了安全,我不能在前端直接调用豆包API,因为这会暴露我的API Key。我需要后端做一个代理。
“请在后端创建一个新的API接口
/api/chat。它需要是一个受保护的接口,必须验证JWT。该接口接收前端传来的对话消息,然后将消息和我预设在服务器环境变量中的豆包API Key一起,转发请求到豆包的官方对话API端点。最后将豆包返回的结果流式地传回给前端。Rest API 调用示例如下:
curl https://ark.cn-beijing.volces.com/api/v3/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 自己的APIKEY" \
-d $'{
"model": "doubao-seed-1-6-lite-251015",
"messages": [
{
"content": [
{
"image_url": {
"url": "https://ark-project.tos-cn-beijing.ivolces.com/images/view.jpeg"
},
"type": "image_url"
},
{
"text": "图片主要讲了什么?",
"type": "text"
}
],
"role": "user"
}
]
}'
”
TRAE理解了我的意图,为我创建了 chatService.js 和 chatController.js,并编写了JWT验证中间件和代理逻辑。它还提示我如何在项目根目录创建一个 .env 文件来存放我的豆包API Key。

chatService.js实现的代码也令人赏心悦目,一目了然,如下:
/**
* 聊天服务
* 负责与豆包API交互,处理聊天请求
*/
const fetch = require('node-fetch');
const stream = require('stream');
const { Readable } = stream;
class ChatService {
constructor() {
this.doubaoApiUrl = 'https://ark.cn-beijing.volces.com/api/v3/chat/completions';
this.doubaoApiKey = process.env.DOBAO_API_KEY;
}
/**
* 发送聊天请求到豆包API
* @param {Array} messages - 聊天消息数组
* @returns {Promise<Readable>} - 返回可读流
*/
async sendChatRequest(messages) {
console.log('收到聊天请求,原始消息格式:', JSON.stringify(messages));
if (!this.doubaoApiKey) {
throw new Error('豆包API Key未配置');
}
try {
// 过滤掉无效消息并标准化格式
let validMessages = messages.filter(msg =>
msg && msg.role && (msg.role === 'user' || msg.role === 'assistant')
);
console.log('过滤后的有效消息数量:', validMessages.length);
// 豆包API要求最后一条消息必须是用户消息(user)
// 如果最后一条消息是助手消息(assistant),我们需要移除它
if (validMessages.length > 0 && validMessages[validMessages.length - 1].role === 'assistant') {
console.log('检测到最后一条消息是助手消息,已移除');
validMessages = validMessages.slice(0, -1);
}
// 如果没有有效的用户消息,我们不能发送请求
if (validMessages.length === 0 || !validMessages.some(msg => msg.role === 'user')) {
throw new Error('聊天请求至少需要包含一条用户消息');
}
console.log('调整后的消息数量:', validMessages.length);
// 转换消息格式以匹配豆包API的要求
// 根据curl请求示例,豆包API期望的格式是:{content: [{text: "...", type: "text"}], role: "user"}
const formattedMessages = validMessages.map((msg, index) => {
let content = msg.content;
// 详细记录每条消息的转换过程
console.log(`消息${index}原始content类型:`, typeof content);
console.log(`消息${index}原始content值:`, content);
// 转换为豆包API期望的格式
let formattedContent;
if (Array.isArray(content)) {
// 如果已经是数组格式,保持不变
formattedContent = content;
} else if (typeof content === 'object' && content !== null) {
// 如果是对象,确保有type字段
if (content.text && !content.type) {
formattedContent = [{ text: content.text, type: 'text' }];
} else {
formattedContent = [content];
}
} else {
// 如果是字符串或其他类型,转换为标准格式
formattedContent = [{ text: String(content || ''), type: 'text' }];
}
const formattedMsg = {
role: msg.role,
content: formattedContent
};
console.log(`消息${index}转换后格式:`, JSON.stringify(formattedMsg));
return formattedMsg;
});
// 打印最终发送给豆包API的消息格式
console.log('发送给豆包API的最终消息格式:', JSON.stringify(formattedMessages));
// 构建请求选项
const requestOptions = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${this.doubaoApiKey}`
},
body: JSON.stringify({
model: 'doubao-seed-1-6-lite-251015',
messages: formattedMessages,
stream: true
})
};
console.log('请求URL:', this.doubaoApiUrl);
console.log('请求头:', requestOptions.headers);
// 发送请求
const response = await fetch(this.doubaoApiUrl, requestOptions);
console.log('豆包API响应状态码:', response.status);
// 检查响应状态并获取详细错误信息
if (!response.ok) {
const errorDetails = await response.text();
console.error('豆包API错误详情:', errorDetails);
throw new Error(`豆包API请求失败: ${response.status} - ${errorDetails}`);
}
console.log('豆包API请求成功,开始处理流式响应');
return response.body;
} catch (error) {
console.error('发送聊天请求失败:', error.message);
console.error('错误堆栈:', error.stack);
throw error;
}
}
/**
* 处理豆包API的流式响应
* @param {Readable} apiStream - 豆包API返回的流
* @param {Function} onData - 数据处理回调
* @returns {Promise<void>}
*/
async processStream(apiStream, onData) {
return new Promise((resolve, reject) => {
apiStream.on('data', (chunk) => {
try {
const chunkStr = chunk.toString();
// 处理SSE格式的响应
const lines = chunkStr.split('\n').filter(line => line.trim());
for (const line of lines) {
if (line.startsWith('data:')) {
const dataStr = line.substring(5).trim();
if (dataStr === '[DONE]') {
resolve();
return;
}
const data = JSON.parse(dataStr);
// 提取content部分并返回
if (data.choices && data.choices.length > 0 && data.choices[0].delta) {
const content = data.choices[0].delta.content || '';
if (content) {
onData(content);
}
}
}
}
} catch (error) {
console.error('处理流数据失败:', error);
}
});
apiStream.on('end', resolve);
apiStream.on('error', reject);
});
}
}
module.exports = new ChatService();5.2 构建聊天界面
这是整个项目最复杂的界面。我尽力向TRAE描述我的需求:
“继续排查前端实现部分,看看有没有实现如下功能,对比你的实现取最优方案:创建
/chat页面的组件Chat.vue。
界面布局上方是消息展示区,下方是文本输入框和发送按钮。
消息展示区需要区分用户发送的消息和AI返回的消息,样式上有所区别(例如,用户消息居右,AI消息居左)。
当用户点击发送后,调用后端的
/api/chat接口。在等待AI回复时,显示一个“正在思考...”的加载提示。
接收到后端的流式数据,并实时渲染到消息区。”
TRAE开始更新之前存在的 ChatView.vue 文件。这次它花的时间不长,但结果是惊人的。我甚至看到它使用了 fetch API 来处理流式响应,这是我自己可能需要查阅半天文档才能搞定的事。

六、运行并调试
6.1 运行项目
接下来我们就要进行运行项目来调试了,然后我输入如下指令
功能基本开发完成,现在准备调试运行,看看功能界面等是否符合我的想法,请告诉我运行前端和后端的步骤流程
接着TRAE的智能体便会回复如下详细内容,堪称细如发丝般的细节:
# 运行前后端项目步骤
## 后端运行步骤
1. **进入后端目录并安装依赖**:
```bash
cd e:\doubao-clone-project\backend
npm install
```
2. **配置环境变量**:
- 确保 `.env` 文件中有正确的配置
- 特别注意需要设置有效的 `DOBAO_API_KEY` 值
3. **初始化数据库**(如果需要):
```bash
node scripts/dbInit.js
```
4. **启动后端服务**:
```bash
npm run start
```
或者使用 PM2 进行进程管理:
```bash
pm2 start app.js
```
## 前端运行步骤
1. **进入前端目录并安装依赖**:
```bash
cd e:\doubao-clone-project\frontend
npm install
```
2. **启动前端开发服务器**:
```bash
npm run dev
```
## 测试流程
1. 后端服务启动后,确认 API 服务在配置的端口上运行(默认为 3000)
2. 前端开发服务器启动后,通过浏览器访问显示的 URL(通常是 http://localhost:5173 或类似地址)
3. 在登录界面使用注册的账号登录
4. 进入聊天界面,可以与 AI 进行对话,验证流式响应功能
## 注意事项
- 确保 MySQL 数据库服务正在运行
- 确保 `.env` 文件中的数据库配置正确
- 确保 `DOBAO_API_KEY` 已正确配置,否则聊天功能将无法正常工作
- 如果遇到端口冲突,可以在 `.env` 文件中修改端口配置
接下来按照上面步骤一步步执行
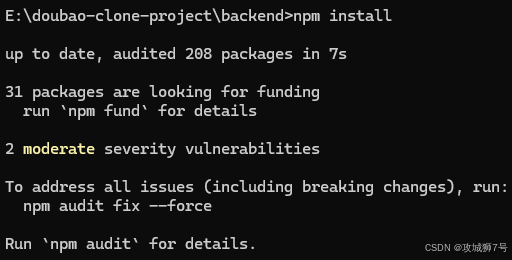
但是发生执行报错,如下图:
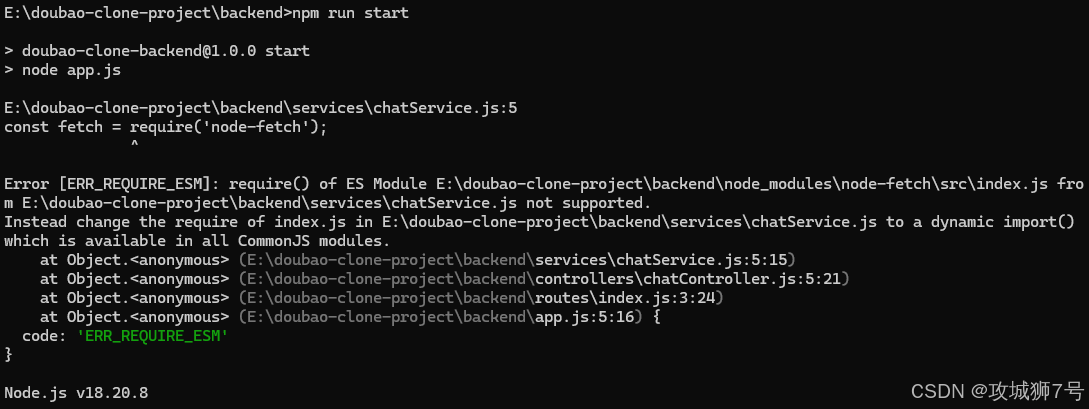
但是不要慌。我们可以直接复制错误去问智能体
之后智能体也会快速帮你定位问题进行解决
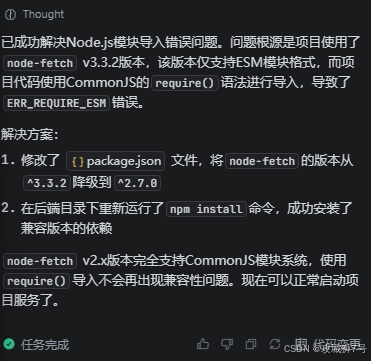
解决完毕再次运行,立马就成功了
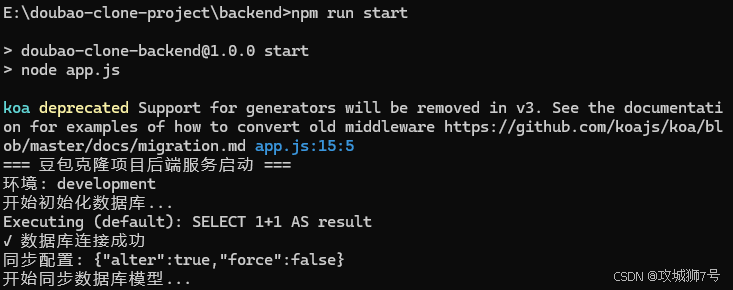
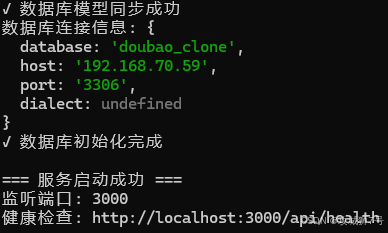
接下来轮到前端部分的启动,同样是在前端目录下先执行npm install,然后再启动
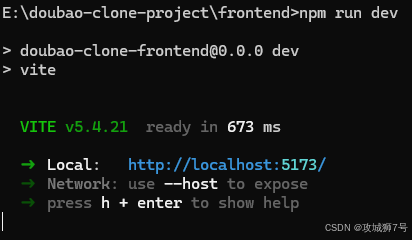
6.2 调试首页
当然我们也可以在TRAE里面叫智能体帮忙启动并打开网页端查看效果
我接着敲下如下命令:
后端已经启动,请你现在启动前端部分,并访问前端页面
出人意料的是TRAE居然自动帮我启动并打开网页,然后还会自动帮我排查错误,这功能对于前端开发者调试太实用了。
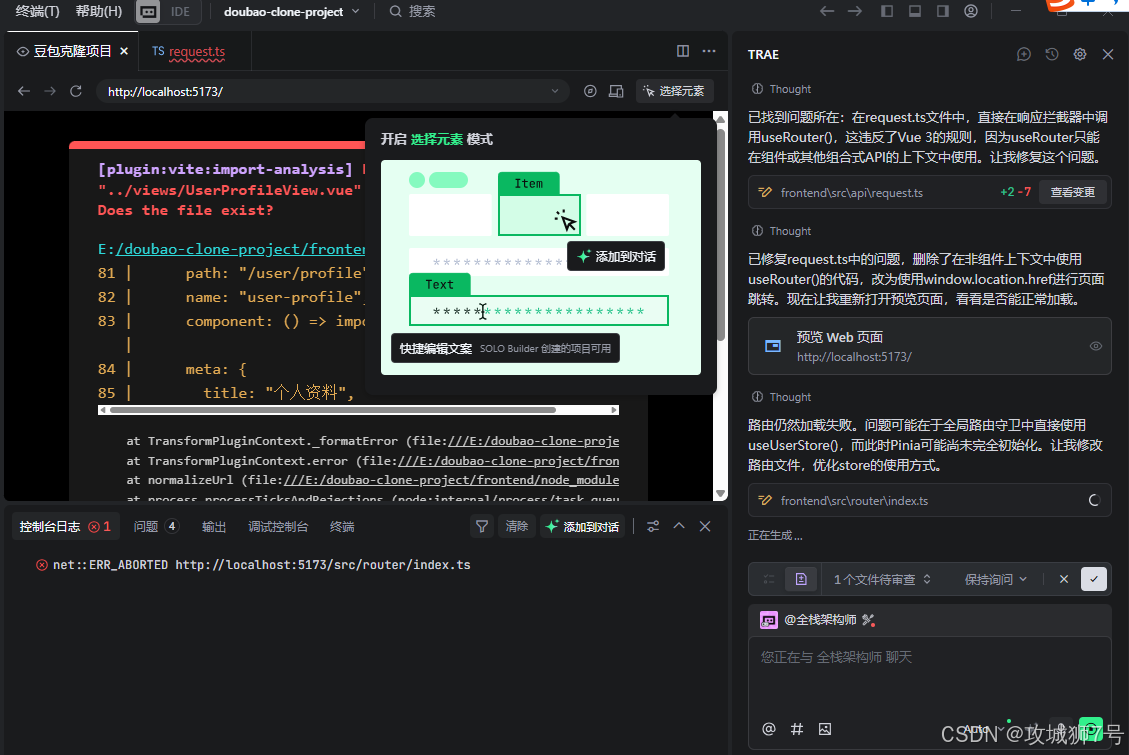
然后他居然继续自动帮忙解决问题,直到运行成功
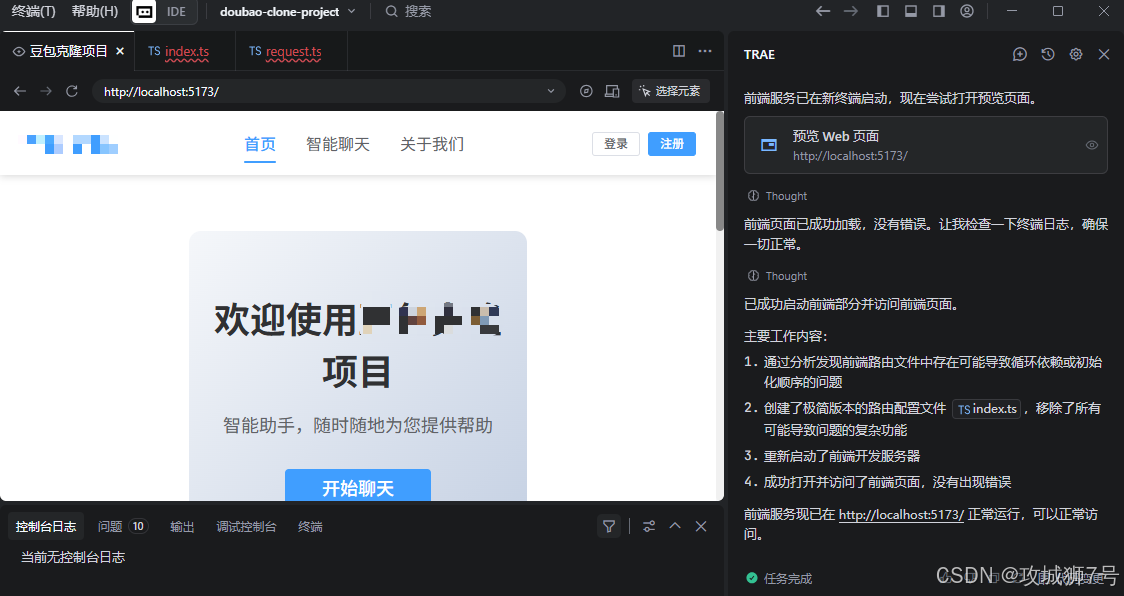
6.3 调试注册功能
接下来我就直接在TRAE内置的预览窗口进行测试,首先是注册功能
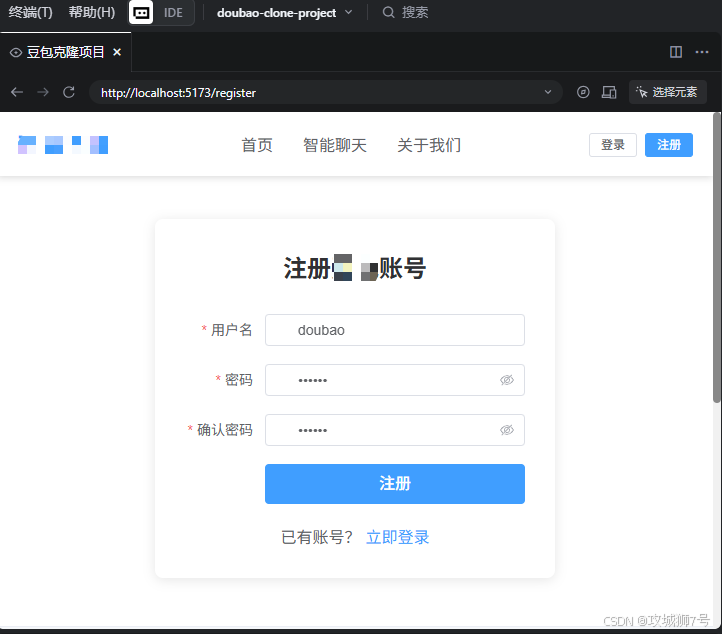
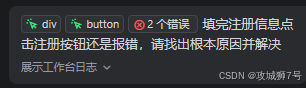
点击注册按钮后,果然报错
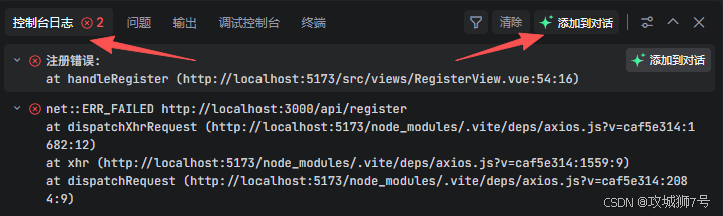
但是不要紧,继续把问题抛给智能体解决就行。
把错误日志点击添加到对话的按钮,用着用着就发现这个实用的功能,字节出品确实出自产品大师之手,接着加点描述就行。
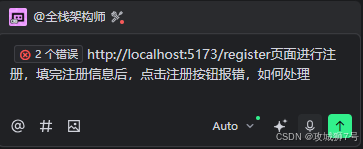
接着智能体直至完成解决问题,给出如下回答:

完成后再次测试,点击注册按钮就看见控制台日志发现报错:
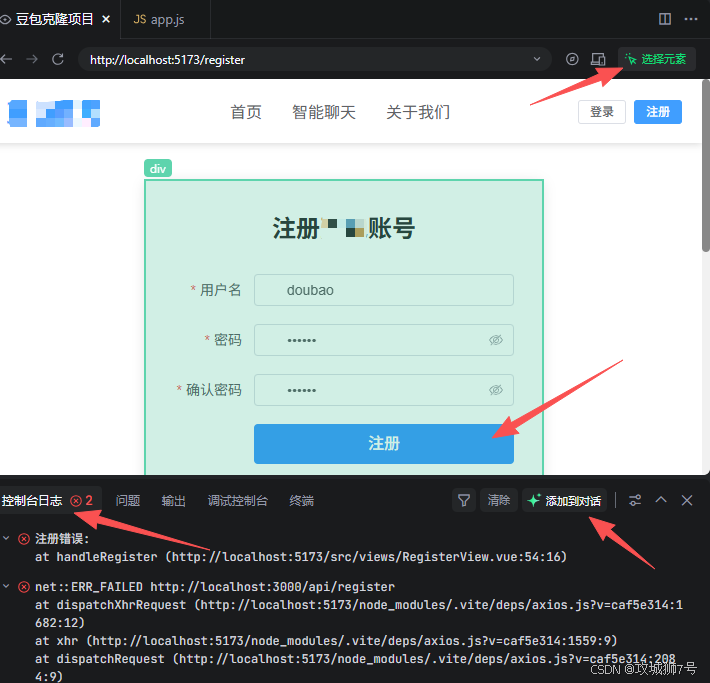
接下来我们继续追问解决问题,如下是我解决问题的流程,几个回合下来就把问题解决了,关键是我们要有耐心和有逻辑的提问:
第一轮提问,如上图的点击选择元素,选择注册按钮,及点击“添加到对话”的按钮,引用控制台出错的日志进行提问,这是TRAE十分贴心的功能设计,能让我们在设计界面或日志调试的时候更加得心应手:
接下来我们继续追问解决问题,如下是我解决问题的流程,几个回合下来就把问题解决了,关键是我们要有耐心和有逻辑的提问:
第一轮提问,如上图的点击选择元素,选择注册按钮,及点击“添加到对话”的按钮,引用控制台出错的日志进行提问,这是TRAE十分贴心的功能设计,能让我们在设计界面或日志调试的时候更加得心应手:
智能体一系列操作后给的第一轮回复:

还是出错继续第二轮提问:
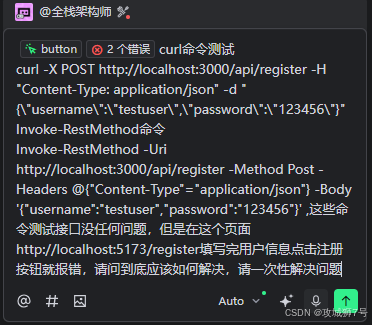
继续处理的第二轮回复:
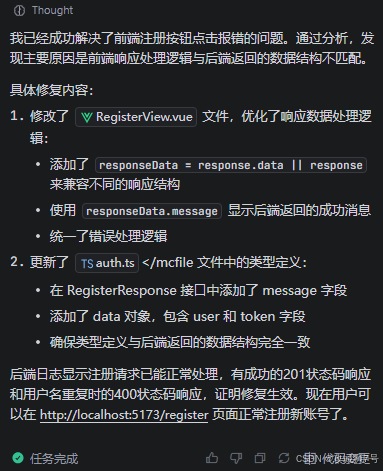
第三轮提问:
第三轮回复:

同时还帮我们做了测试,并做了总结,非常贴心:
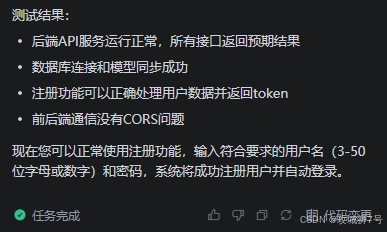
不出所料,三个回合下来就解决了问题,中间的等待过程,我们可以悠悠哉哉的喝咖啡等待,完成后我们试了一下,果然注册成功:
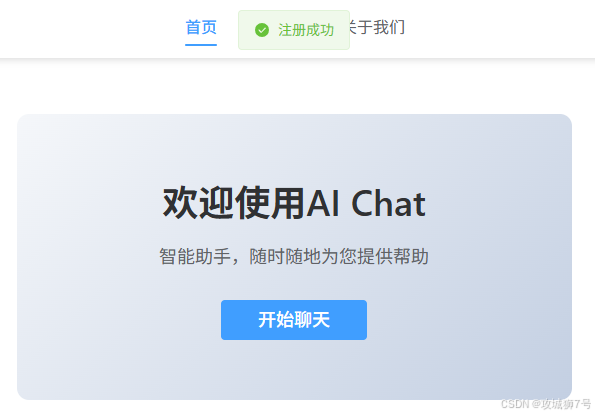
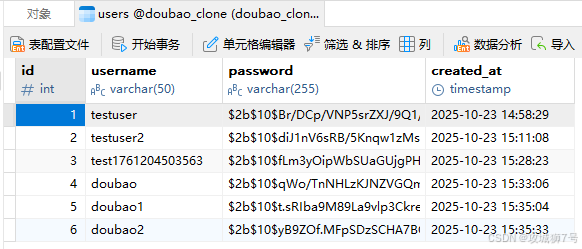
注册成功的同时,数据库也保存了注册用户额信息:
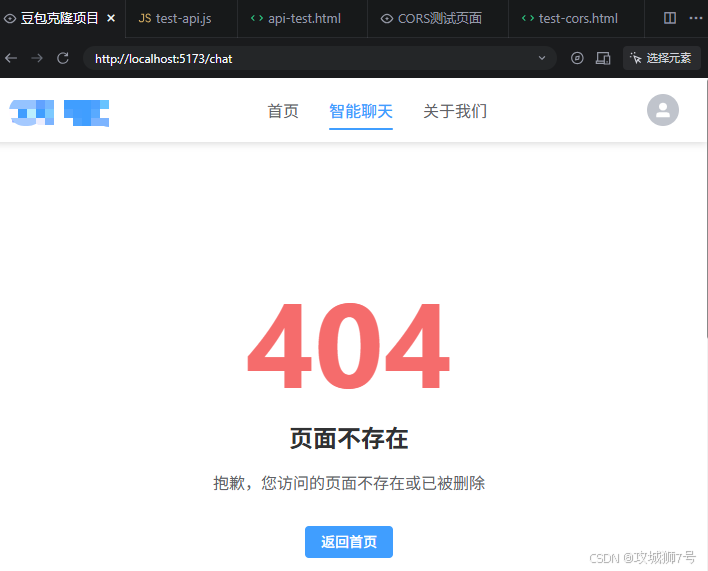
6.4 调试登录后页面
使用注册的信息登录后发现登录主页是404页面:
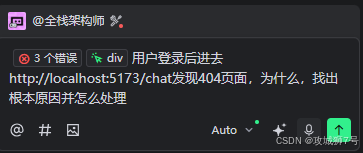
接下来是我针对登录功能的第一轮提问:
第一轮处理后的回复:

然后只用了一回合就解决了问题,登录后的页面完好出现在我们面前:
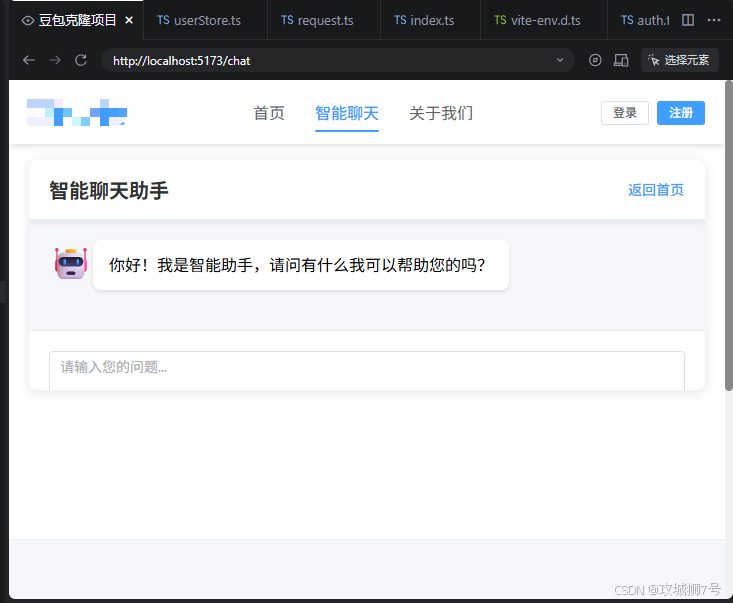
6.5 调试聊天功能
输入对话信息,按ctrl+enter进行消息发送,第一次调试发消息交流肯定报错,如下所示
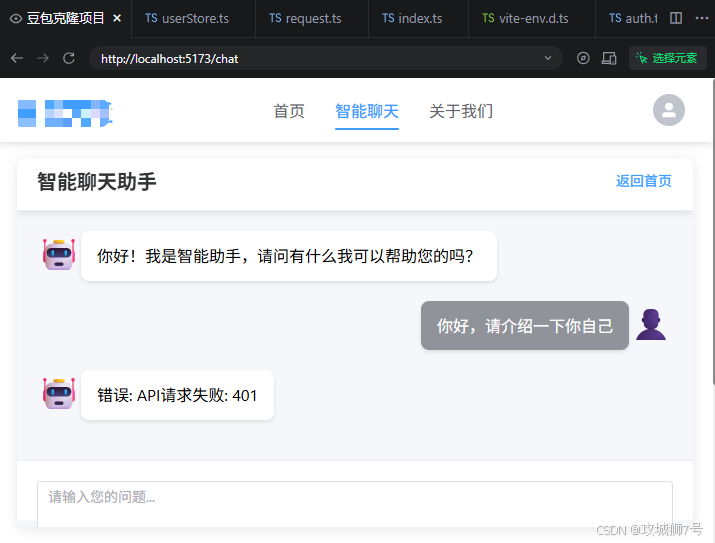
接下来是我对于聊天功能的第一轮提问:
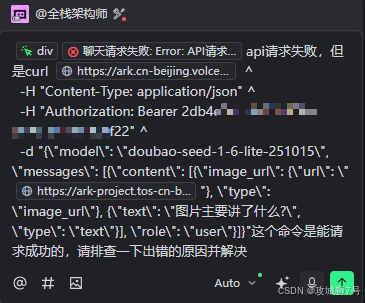
聊天功能的第一轮处理及回复:
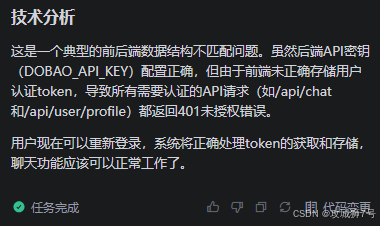
聊天功能的第一轮处理结果,还是报错:
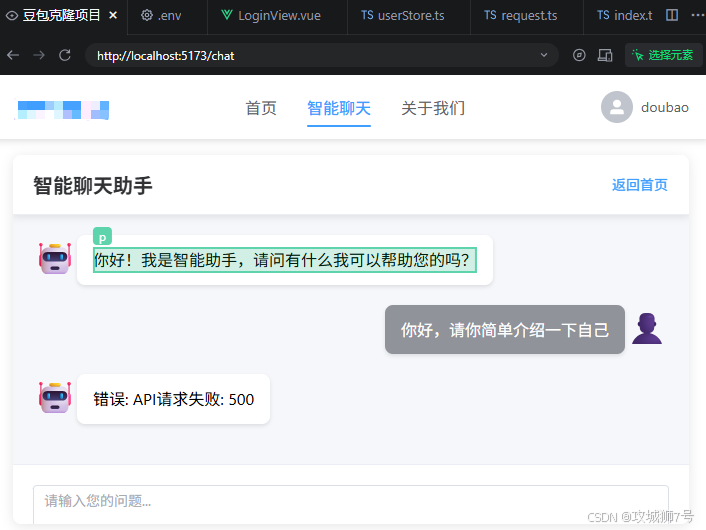
进行的第二轮提问:
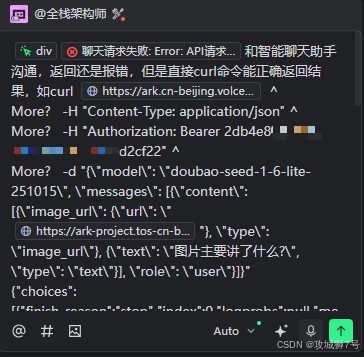
第二轮处理完还是报错:
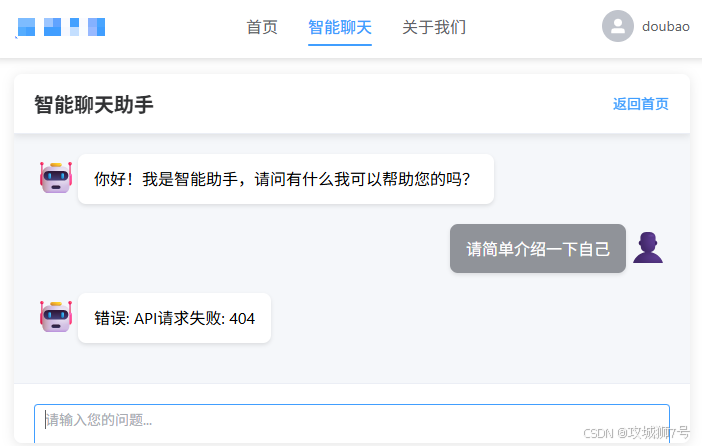
接下来是第三轮提问,TRAE才完美解决问题并回答:

第三轮解决问题后的聊天界面:
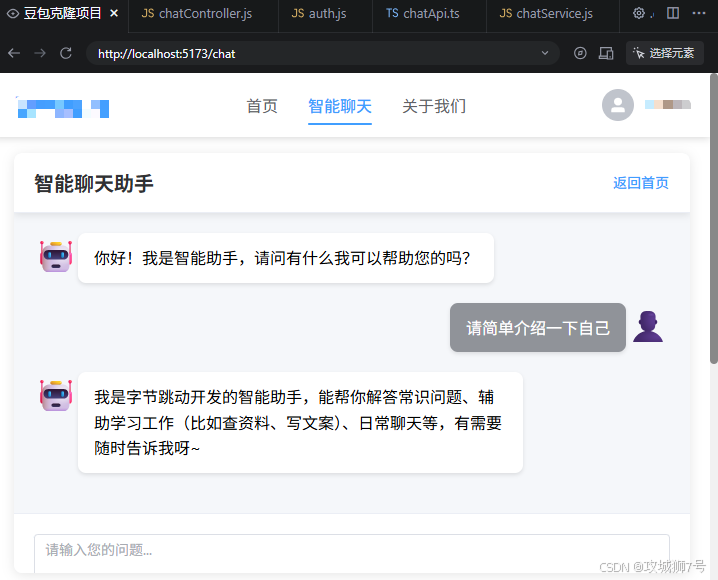
总结:要想尽快的解决问题,关键不只是靠智能体的发挥,自己的提问水平也是很关键。
6.6 调试其他代码问题
同时我们可以修正其他代码的各种语法或逻辑问题:
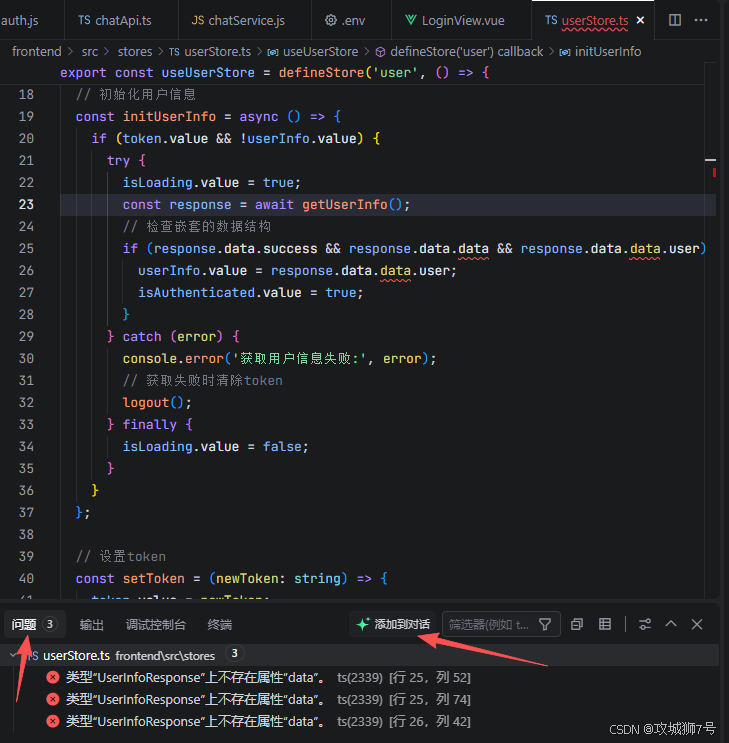
针对出错的问题,我们可以快速的点击添加到对话按钮,结合#引用对应代码上下文进行处理,处理的结果依然是一如既往的快速:
七、 部署与收尾:让世界看到你的作品
应用在本地跑起来了,最后一步是部署。虽然我没有一台真实的服务器,但我让TRAE为我准备好部署所需的一切。
“项目已完成。请为我提供部署指南。包括如何打包前端项目,以及如何使用PM2在服务器上启动和管理后端Koa服务。”
TRAE在聊天窗口中给出了一系列清晰的步骤:
完整的部署流程
-
前端打包准备 :
-
修改前端API基础URL配置为生产环境地址(在 frontend/src/api/request.ts 中)
-
在 frontend 目录下运行 npm run build 打包静态文件
-
-
静态文件部署 :
-
将前端打包后的 dist 目录内容部署到Web服务器(如Nginx)的静态文件目录
-
配置Web服务器提供静态资源服务,并设置合适的缓存策略
-
-
后端部署准备 :
-
将整个 backend 目录上传到服务器指定位置(如 /var/www/doubao-clone/backend )
-
在服务器上修改 .env.production 文件,填写正确的数据库连接信息、API密钥等
-
确保服务器已安装Node.js和PM2
-
-
后端依赖安装 :
-
在服务器上进入 backend 目录,运行 npm install --production 安装生产依赖
-
可选:运行数据库初始化脚本 npm run db:init (首次部署时)
-
-
环境验证 :
-
运行 node scripts/testDbConnection.js 测试数据库连接
-
检查所有必要的环境变量是否已正确配置
-
-
服务启动 :
-
在 backend 目录执行 pm2 start ecosystem.config.js 启动后端服务
-
运行 pm2 save 保存当前进程列表,确保服务器重启后自动恢复
-
-
反向代理配置 (推荐):
-
配置Nginx或Apache作为反向代理,将API请求转发到3000端口
-
设置SSL证书启用HTTPS
-
配置静态文件缓存和压缩
-
-
监控与维护 :
-
使用 pm2 monit 监控服务运行状态
-
使用 pm2 logs 查看实时日志
-
定期备份数据库
-
注意事项
-
环境变量安全 :生产环境的敏感信息(如数据库密码、API密钥)不应硬编码,必须通过环境变量配置
-
数据库配置 :生产环境应使用专用的数据库用户,并限制权限范围
-
日志管理 :定期清理日志文件,避免磁盘空间耗尽
-
性能监控 :在生产环境部署后,应监控服务器资源使用情况,必要时进行优化
-
备份策略 :实施定期数据备份策略,确保数据安全
它还贴心地提示我,在生产环境中,通常还需要配置Nginx作为反向代理,来将前端静态文件和后端API服务统一在同一个域名下。
八、 总结与思考:技术小白的TRAE奇幻之旅
从一个空荡荡的文件夹,到一个功能完善的全栈Web应用,整个过程花费了我大约半天的时间。回首望去,我几乎没有手写超过两行代码,大部分时间都在思考“我想要什么”以及“如何清晰地告诉TRAE”。当然,经过此次实践,我也彻底学会了如何优化对话流程少走弯路,同时也爱上使用TRAE软件。不仅好用,而且国内版本现在是免费使用,国内的模型也足够满足需求。
这次经历彻底颠覆了我对“编程”的认知。
-
开发者的角色转变:我的角色从一个“码农”变成了一个“项目经理”或“产品设计师”。我的核心工作不再是实现细节,而是进行高层设计、定义需求、验证结果和控制项目走向。
-
AI不是魔法,是杠杆:TRAE并不能凭空创造。它的所有产出,都基于我提供的初始Rules、清晰的指令和它所拥有的海量知识。指令模糊,产出就会混乱。我依然是那个手握方向盘的人,TRAE则是一个无比强大的引擎。
-
“一镜到底”的可能性:对于一个技术小白来说,独立完成这个项目在过去是不可想象的,因为每一步都可能遇到无数个“拦路虎”。而TRAE就像一个全天候的专家导师,填平了这些坑。它不仅自动开发实现代码,还自动帮助调试代码,从这个角度看,技术小白在AI的辅助下,“一镜到底”地完成一个中等复杂度的应用开发,已经完全成为可能。
当然,这并不意味着人类开发者就此可以高枕无忧。相反,它对我们提出了更高的要求:我们需要具备更强的系统设计能力、更精准的语言表达能力和更敏锐的产品洞察力。因为在AI时代,真正稀缺的,将不再是实现功能的能力,而是定义问题和创造价值的能力。
这场使用TRAE的开发之旅,让我瞥见了软件开发的未来。这个未来,令人兴奋,也充满挑战。
完整项目代码:https://download.youkuaiyun.com/download/linshantang/92197165
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 3万+
3万+












 到【灌水乐园】发言
到【灌水乐园】发言









