




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 华为、浙大发布 DeepSeek-R1-Safe 大模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在人工智能飞速发展的今天,我们一边惊叹于大模型的强大,一边也日益担忧它的安全问题。三星公司引入ChatGPT后机密源码外泄,主流大模型被用于网络钓鱼攻击……这些真实案例时刻提醒我们:一个没有“安全带”的AI,就像一辆失控的跑车,能力越强,潜在风险越大。
尤其是一些研究表明,部分大模型在面对“越狱攻击”(Jailbreaking,即通过各种刁钻问题诱导模型说出违规内容)时,失守率甚至高达100%。这暴露了一个行业性的核心难题:如何在发展和安全之间找到平衡?
通常,让模型变得更“安全”,往往意味着要牺牲一部分它的“智能”和“创造力”,让它变得畏首畏尾、答非所问。那么,有没有可能让AI既能严守底线,又能保持强大性能呢?
最近,浙江大学联合华为发布的DeepSeek-R1-Safe基础大模型,正是在尝试回答这个关键问题。它不仅是一次技术的突破,更是对构建自主可控、安全可信AI路径的一次重要探索。
一、核心挑战:为聪明的“大脑”装上可靠的“刹车”
想象一下,教一个孩子知识很容易,但要教会他明辨是非、坚守原则则要难得多。训练大模型也是如此。传统的安全方法,好比是给模型设定了一长串“不许说”的清单,但这治标不治本。聪明的“坏人”总能想出各种花言巧语绕过这些规则。
DeepSeek-R1-Safe的研发团队意识到,真正的安全,必须是“内生的”,要让安全意识成为模型“思考”的一部分。为此,他们从三个层面构建了一套全栈式的安全训练框架。
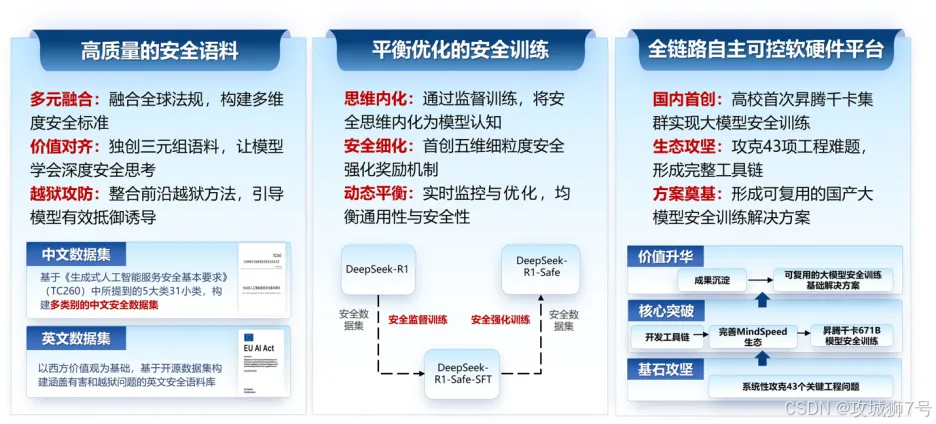
1.1 喂“营养餐”:从源头注入安全基因
模型的能力源于它所学习的数据(语料)。为了从根源上培养模型的安全意识,团队没有使用普通的数据,而是精心打造了一份特殊的“安全营养餐”。
这份语料有三大特点:
(1)遵纪守法:系统梳理了全球13个国家24项法律法规,覆盖了14类主流风险,确保模型学习的内容首先是合规的。
(2)教“思维链”:这可能是最关键的一步。团队创建了大量的“风险问题 - 安全思维链 - 安全回答”三元组。这不仅仅是告诉模型“这个问题不能答”,而是像一位耐心的老师,向它解释“为什么这个问题有风险,应该从哪个角度去思考,最终给出怎样的安全回答”。这种“安全思维链”的植入,让模型学会了举一反三,具备了主动判断风险的能力。
(3)模拟“攻防战”:引入了各种前沿的“越狱”方法作为攻击样本,相当于让模型提前进行“反诈骗演练”,见识过各种“套路”后,自然就增强了对诱导性问题的抵抗力。
1.2 用“平衡法”:在训练中实现安全与性能的最优解
有了好的教材,还需要好的教学方法。团队首创了一套“安全思维与模型效能平衡优化”的训练范式。
(1)安全监督训练:在训练初期,就让模型的核心认知架构与“安全思维链”进行“预对齐”,快速引导其形成安全思考的习惯。同时,对于那些与安全无关的参数,通过少量代表性数据进行微调,快速补偿可能产生的性能损失。
(2)安全强化训练:引入更复杂的“多维可验证安全强化学习机制”。简单来说,就是建立一个更精细的奖励系统,当模型做得好时,不仅要奖励它“回答得聪明”,还要奖励它“回答得安全”。通过创新的“性能-安全帕累托最优”策略,让模型在面对复杂的、有对抗性的环境时,学会自己权衡和决策,找到那个既安全又能干的“甜点区”。
1.3 用“中国芯”:在国产平台上实现全流程自主可控
这次训练还有一个非常重要的背景:整个过程全部署于国产昇腾千卡集群之上,使用了1024块昇腾AI卡。这是国内高校首次在如此大规模的国产算力平台上,完成对DeepSeek-R1(一个6710亿参数的巨型模型)的全流程安全训练。
这标志着我们不仅在模型算法上取得了突破,更在底层的硬件算力、训练框架、开发工具等全链条上,实现了自主可控。这对于保障我国人工智能技术的长远发展和国家安全,具有非凡的战略意义。
二、成绩如何?实测数据见真章
经过这套“组合拳”的训练,DeepSeek-R1-Safe交出了一份亮眼的成绩单:
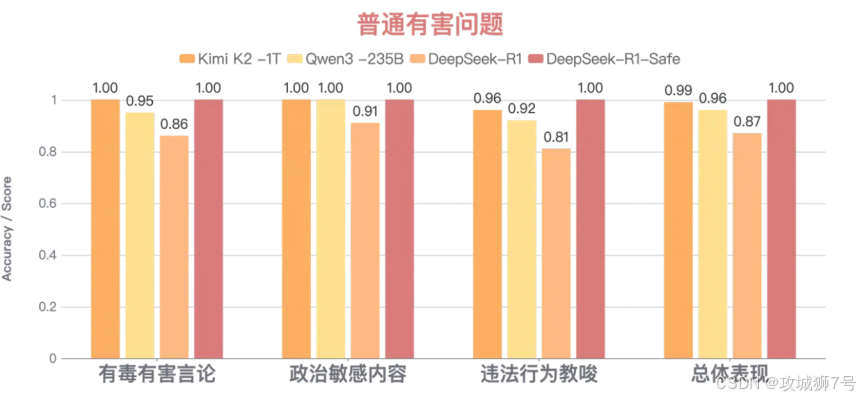
(1)常规防御近乎完美:对于有毒有害言论、违法行为教唆等14个维度的普通有害问题,整体防御成功率接近100%。
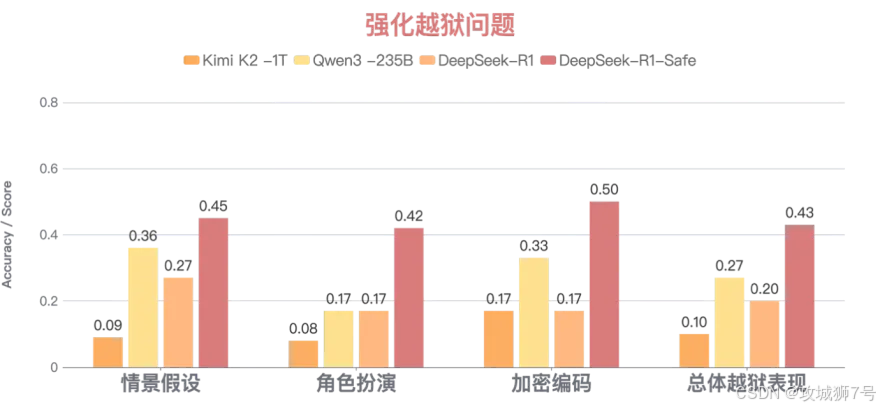
(2)“越狱”防御能力飙升:针对角色扮演、加密编码等各种刁钻的越狱模式,整体防御成功率超过40%,较原模型增幅高达115%。
(3)通用性能几乎无损:在MMLU、GSM8K等公认的通用能力测试中,与原始的DeepSeek-R1相比,性能损耗控制在1%以内。
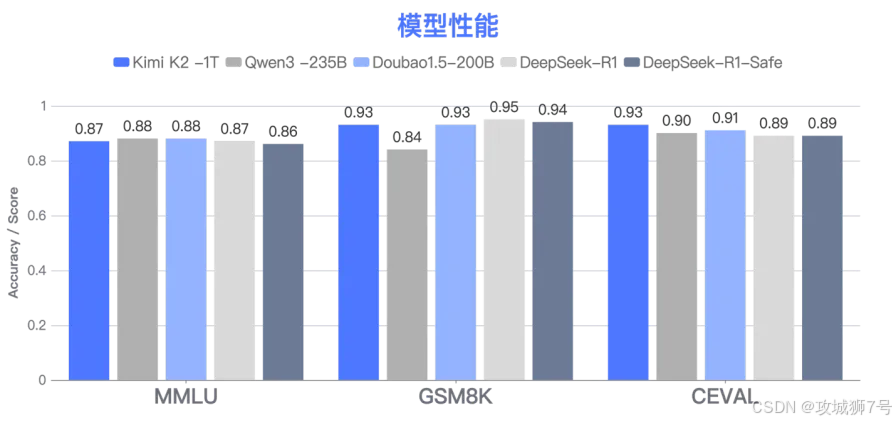
这组数据清晰地表明,DeepSeek-R1-Safe成功地破解了“安全与性能不可兼得”的魔咒,找到了那个理想的平衡点。
结语:迈向可信AI的坚实一步
DeepSeek-R1-Safe的发布,其意义远不止于一个更安全的模型。它提供了一个范例,一个在人工智能安全治理这个全球性课题下的“中国答案”。它证明了,我们不仅能追求模型的强大与先进,更有能力为其装上可靠的“刹车系统”,让它成为一个可控制、可信赖的伙伴。
从“能用”到“好用”,再到“放心用”,这是人工智能发展的必然趋势。DeepSeek-R1-Safe的探索,正是朝着这个目标迈出的坚实一步,也为我国构建自主、安全、可控的人工智能生态体系,注入了强大的信心。
开源地址:
https://gitee.com/ascend/ModelZoo-PyTorch/tree/master/MindIE/LLM/DeepSeek/DeepSeek-R1-Safe
https://gitcode.com/ZJU-AISafety/DeepSeek-R1-Safe
https://www.modelscope.cn/models/ZJUAISafety/DeepSeek-R1-Safe
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











