




 本文详细介绍如何通过IDEA进行Spark项目的远程调试。主要包括四个步骤:将Spark项目打包并复制到集群Master节点;配置IDEA的远程调试连接;在Master节点上启动Spark-Submit;在IDEA中设置断点并开始调试。
本文详细介绍如何通过IDEA进行Spark项目的远程调试。主要包括四个步骤:将Spark项目打包并复制到集群Master节点;配置IDEA的远程调试连接;在Master节点上启动Spark-Submit;在IDEA中设置断点并开始调试。
IDEA远程调试Spark很简单,大概分四步:
1、打包到master
将Spark项目打包后拷贝到master节点上,这里用spark-examples.jar做下示例。
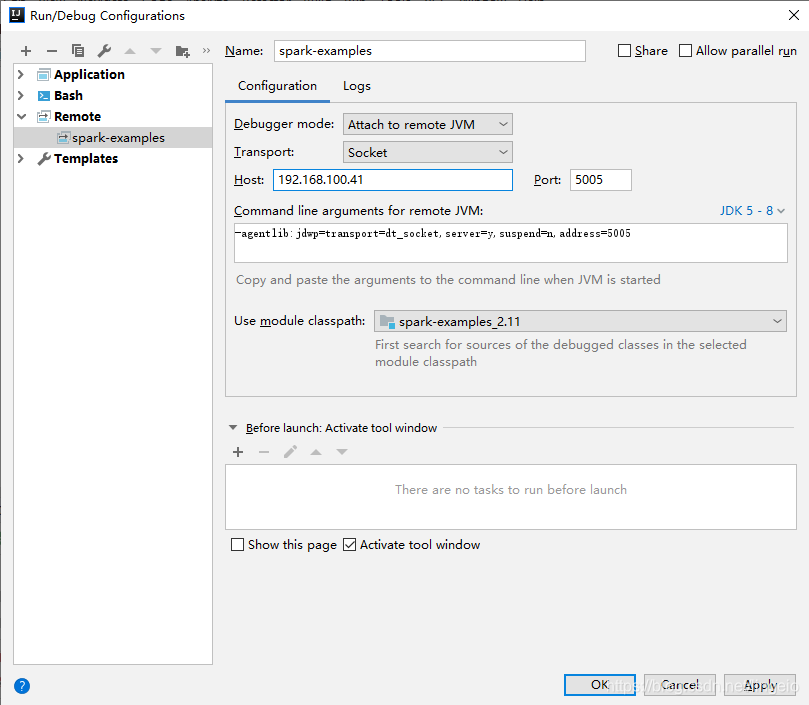
2、IDEA设置Remote连接
添加Remote:Menu -> Run -> Edit Configurations -> 选择 + -> Remote。
修改服务器IP,端口只要没有占用的就可以。
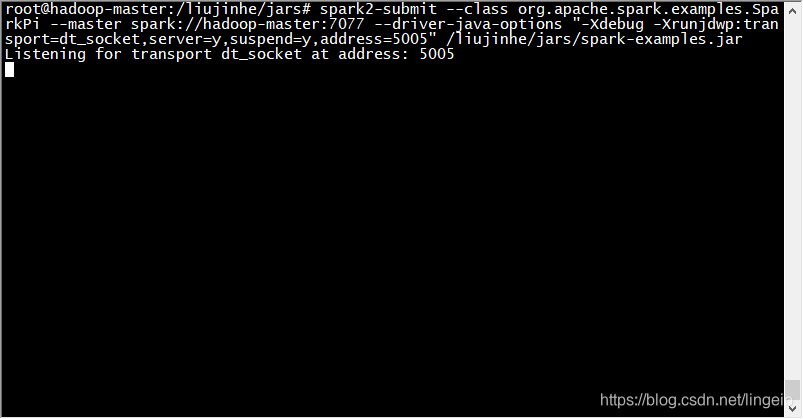
3、服务器启动Spark-Submit
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop-master:7077 \
--driver-java-options \
"-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005" \
/liujinhe/jars/spark-examples.jar
或者,在conf/spark-env.sh添加环境变量:
export SPARK_JAVA_OPTS+="-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005"
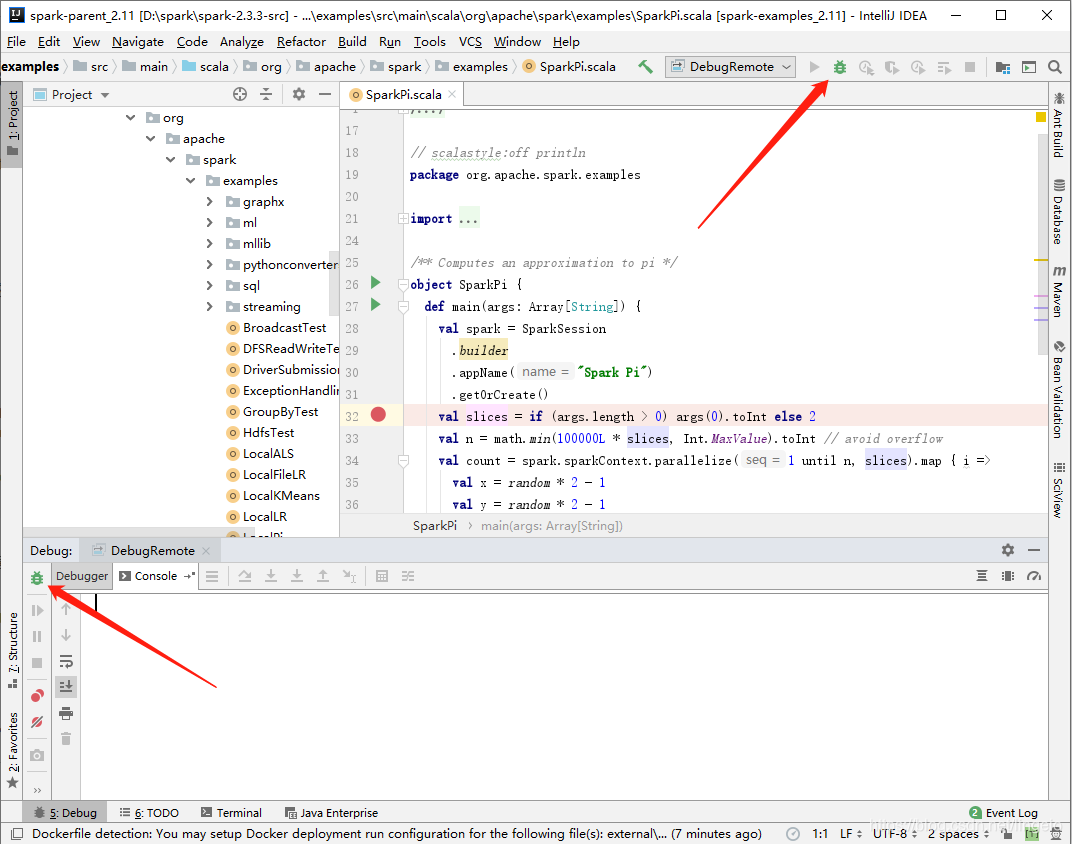
4、IDEA中打断点,开启Debug
IDEA中,在要调试的类中打上断点,运行Debug模式。
其他
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=8888
jvm参数属性说明:
- -Xdebug: 启用调试特性
- -Xrunjdwp:启用JDWP实现,包含若干子选项
- transport=dt_socket:JPDA front-end和back-end之间的传输方法。dt_socket表示使用套接字传输
- server=y:y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器
- suspend=y:y表示启动的JVM会暂停等待,直到调试器连接上才继续执行。suspend=n,则JVM不会暂停等待
- address=5005:JVM在5005端口上监听请求,这个设定为一个不冲突的端口即可
问题
19/07/23 09:03:59 INFO client.StandaloneAppClient$ClientEndpoint: Connecting to master spark://hadoop-master:7077...
19/07/23 09:03:59 WARN client.StandaloneAppClient$ClientEndpoint: Failed to connect to master hadoop-master:7077
org.apache.spark.SparkException: Exception thrown in awaitResult:....
Caused by: java.net.ConnectException: 拒绝连接
出现无法连接,先检查Spark是否启动。


















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











