 有道云DOCX转Markdown多平台发布适配
有道云DOCX转Markdown多平台发布适配





版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/
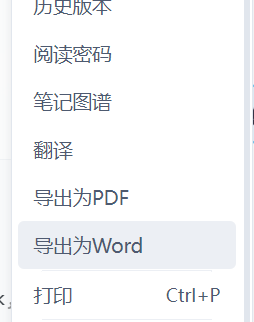
有道云导出docx
有道云笔记右上角更多按钮选择【导出为Word】,可以导出docx文档
docx转换markdown
尝试了几个docx转markdown的python库后,最终选择了python-mammoth,轻量,效率高,可自定义转换满足特定需求。
python-mammoth
python-mammoth 是一个用于将 Microsoft Word (DOCX) 文档转换为 HTML 或 Markdown 的 Python 库。
github地址:https://github.com/mwilliamson/python-mammoth
安装 python-mammoth
pip install mammoth
自定义代码块样式
通过自定义 transform 来实现自定义的代码块样式来支持有道云docx的代码块
def ynote_docx_markdown_transform(document):
...
pass
result = convert_to_markdown(docx_file, transform_document=ynote_docx_markdown_transform)
通过在自定义 transform 断点调试可以看到 document 都是由一个一个 Paragraph 组成的,代码块的 Bookmark 的 name 都是相同的,由此代码块其中一个特征就是相同且相邻的 Bookmark name。
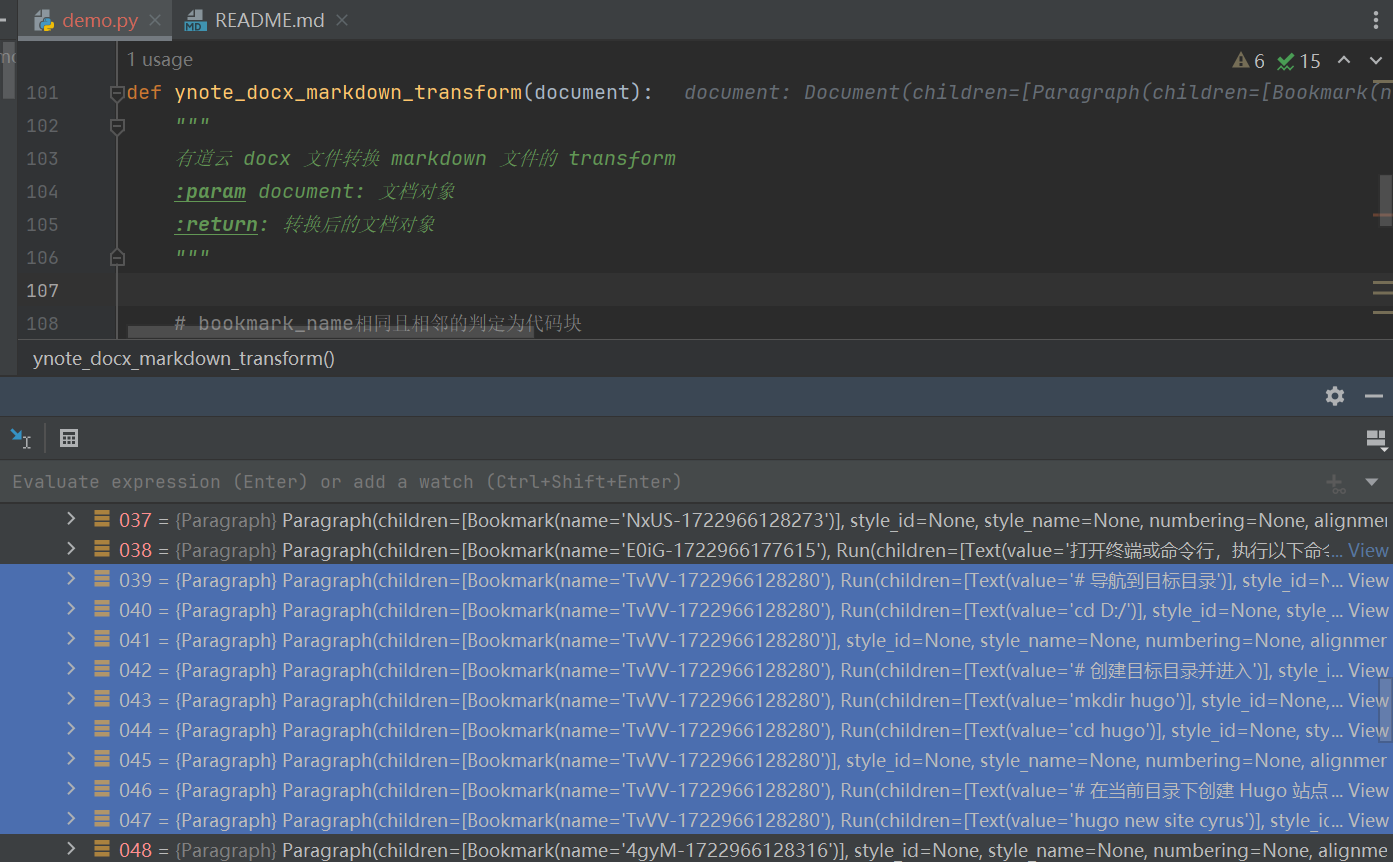
但是有的代码块只是单独的一段
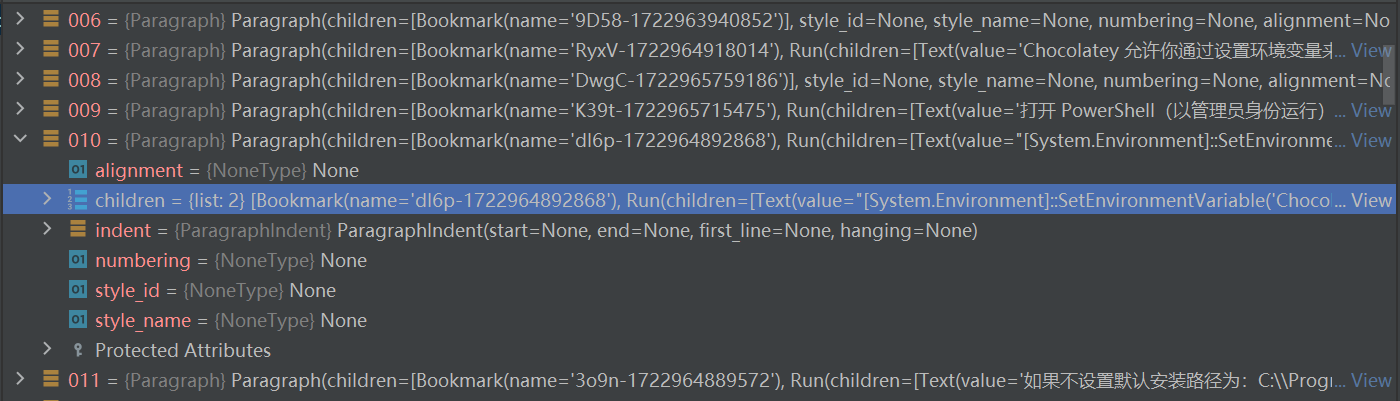
这时可以通过自定义 代码/bash 特征判断该 Paragraph 中的 Text 是不是一段 代码/bash。
def is_possible_code_or_bash(text):
# 常见的代码关键字
code_keywords = [
r'\bif\b', r'\bfor\b', r'\bwhile\b', r'\bdef\b', r'\bclass\b', r'\breturn\b', r'\bimport\b',
r'\bint\b', r'\bfloat\b', r'\bmain\b', r'\binclude\b', r'#include', r'\becho\b', r'\bcd\b',
r'\bgrep\b', r'\bexit\b', r'\belse\b', r'\belif\b', r'#!/bin/bash', r'&&', r'\|\|', r'\$', r'\>',
r'\<'
]
# 常见的 Bash 命令
bash_keywords = [r'::', r'Get-Item ']
# 以这些符号开头的都当 bash 处理
start_keywords = [r'# ', r'git ', r'choco ', r'hugo', r'cd ', r'pip ', r'pip3 ', r'conda ', r'sudo ']
# 检查是否包含代码关键字
for keyword in code_keywords:
if re.search(keyword, text):
return keyword
# 检查是否包含 Bash 命令
for keyword in bash_keywords:
if re.search(keyword, text):
return keyword
# 检查是否包含代码符号
for keyword in start_keywords:
if text.startswith(keyword):
return keyword
return None
实现步骤:
- bookmark_name相同且相邻的判定为代码块
- 其它不相邻的数据通过特征值判断是否可能是代码
- 在代码块前后加上代码块符号
def ynote_docx_markdown_transform(document):
"""
有道云 docx 文件转换 markdown 文件的 transform
:param document: 文档对象
:return: 转换后的文档对象
"""
# bookmark_name相同且相邻的判定为代码块
bookmark_name_list = []
for index, element in enumerate(document.children):
if isinstance(element, Paragraph) and element.children:
bookmark = element.children[0]
if isinstance(element.children[0], Bookmark):
bookmark_name_list.append(bookmark.name)
indices = find_adjacent_duplicates_indices(bookmark_name_list)
# 过滤出非相邻的数据
filtered_indices = filter_out_indices(document.children, indices)
# 其它不相邻的数据通过特征值判断是否可能是代码
for index in filtered_indices:
element = document.children[index]
if len(element.children) >= 2:
run = element.children[1]
if isinstance(run, Run):
text = run.children[0]
if isinstance(text, Text):
feature = is_possible_code_or_bash(text.value)
if feature:
print('=====================================找到代码块======================================================= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









