 深入理解JS引擎及代码优化方法
深入理解JS引擎及代码优化方法





 本文从JS引擎层面深入剖析JavaScript运行机制以实现优化。介绍了主流JS引擎,重点讲解V8引擎运行流程。通过示例代码分析运行速度差异,阐述V8引擎的Hidden Class原理,最后总结优化建议,如初始化定义好属性、倒叙添加属性。
本文从JS引擎层面深入剖析JavaScript运行机制以实现优化。介绍了主流JS引擎,重点讲解V8引擎运行流程。通过示例代码分析运行速度差异,阐述V8引擎的Hidden Class原理,最后总结优化建议,如初始化定义好属性、倒叙添加属性。
序言:作为一名前端工程师,对于javascript大家都不陌生,这篇文章从更深层次的方向——JS引擎去理解javascript到底是怎么运行的,从而进行优化。
JS Engine—— JS 引擎介绍
一、基本介绍
js引擎是一个专门运行javascript的解释器(interpreter)。目前比较主流的js 引擎和介绍,大家可以简单了解一下:
- V8 — 由谷歌使用C++开源的V8引擎,也是我们经常听到的一个引擎
- Rhino — 由 Mozilla Foundation完全用Java管理的一个开源引擎
- SpiderMonkey — 第一代js引擎,曾经运行在 Netscape Navigator 浏览器中,现在是Firefox
- JavaScriptCore — Safari的开源js引擎
- KJS — KDE 引擎,由 Harri Porten开发
- Chakra (JScript9) — Internet Explorer 引擎
- Chakra (JavaScript) — Microsoft Edge 引擎
- JerryScript —轻量级的js引擎,主要用于IOT
二、V8引擎运行流程
现在由于NodeJS和谷歌浏览器的普及,在此就主要介绍V8引擎的运行机制,如果大家对其他引擎感兴趣,可以自行查看,基本上是大同小异的
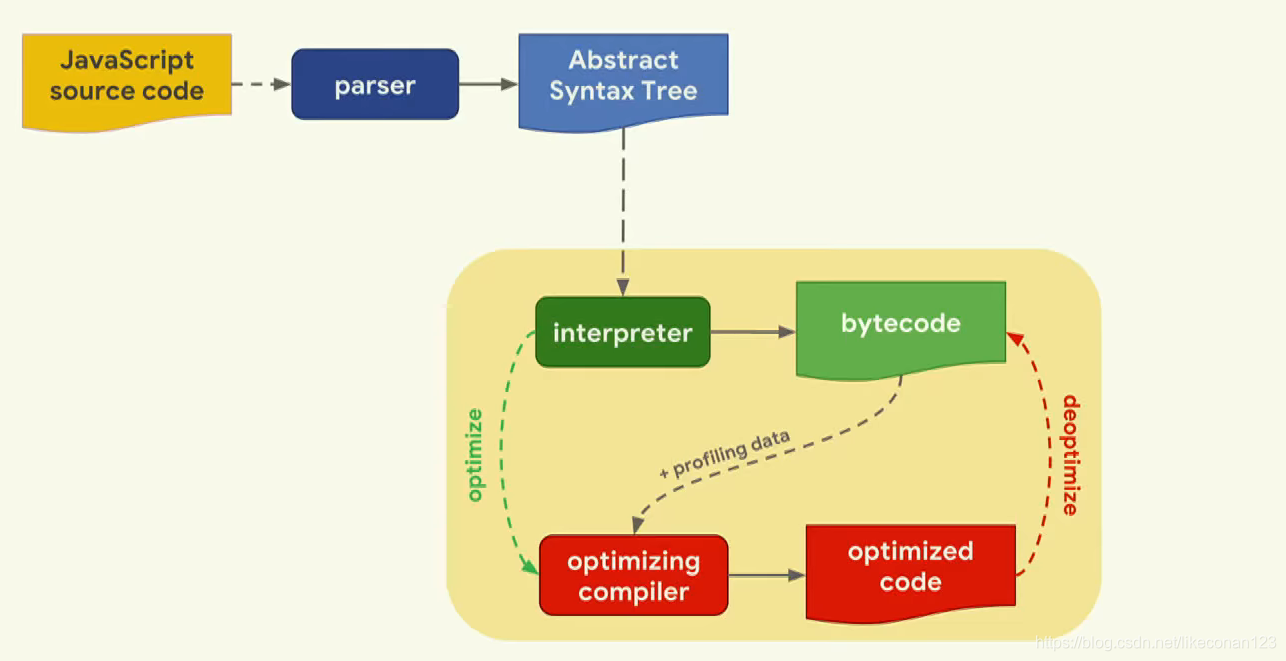
我们可以看到,JS引擎的处理过程是先解析转换为AST语法树,然后由解释器主要做两件事,第一个是转化为机器语言bytecode,第二个是交给编辑器(optimizting compiler)进行优化,中间还有一个数据分析过程(profilling data),主要目的是为了进行优化JS的运行,优化完毕后的代码,再转化为机器语言。
而V8引起的核心组件就分别是Ignition和TurboFan了
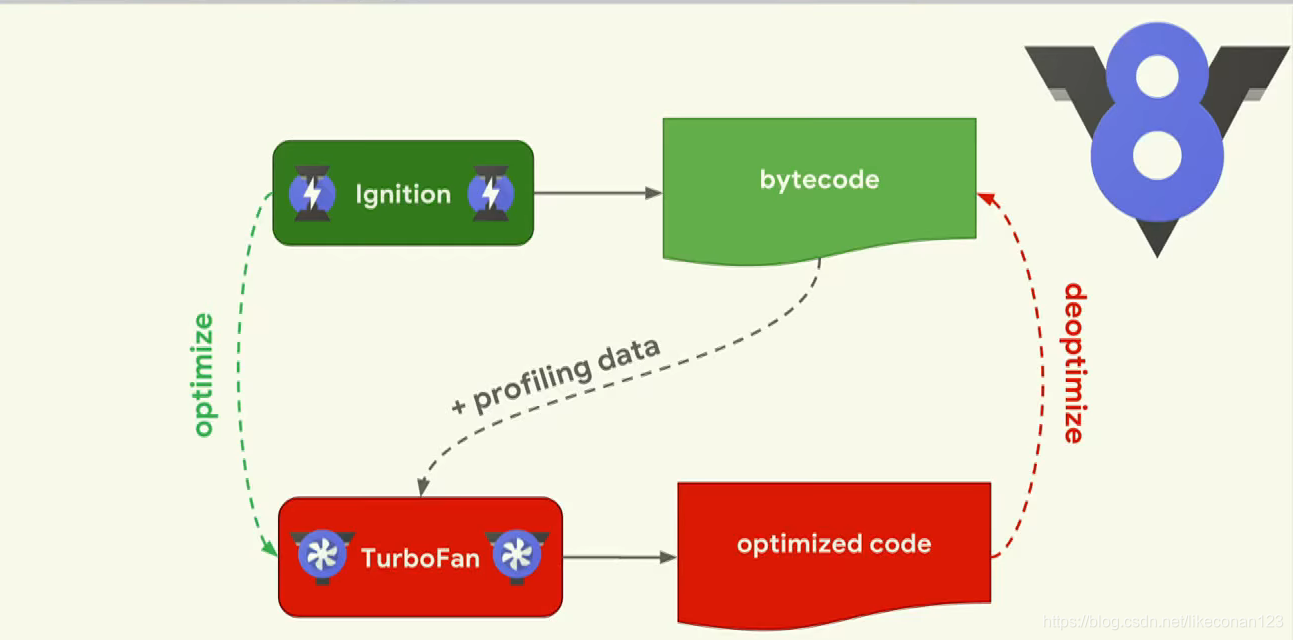
JS Code—— Talk is cheap
看到这,你肯定会想,我知道这有啥用,Talk is cheap,有没有代码可以分析的。 那么大家请看以下示例代码,通过分析代码后,我再详细介绍其中的原理
示例代码一:
// first case
var a = {}
var b = {}
console.time()
for (let k = 0; k < 9999999; k++) {
a[k] = 0
}
for (let i = 0; i < 9999999; i++) {
b[i] = 0
}
console.timeEnd()
// second case
var a = {}
var b = {}
console.time()
for (let k = 0; k < 9999999; k++) {
a[k] = 0
}
for (let i = 10000000; i < 19999999; i++) {
b[i] = 0
}
console.timeEnd()
// third case
var a = {}
var b = {}
console.time()
for (let k = 0; k < 9999999; k++) {
a[k] = 0
}
for (let i = 9999999; i < 0; i--) {
b[i] = 0
}
console.timeEnd()
看完以上代码,内容很简单,就是定义object a和b 然后不断添加属性,唯一区别的是,first case是a和b重复添加相同的属性,second case是a和b添加不同的属性,third case是a和b重复添加相同的属性,但是处理b的时候是相反顺序的。
那么问题来了:三块代码,运行速度有没有快慢之分,分别又大不大呢? (不用去确认循环次数,都是一样滴!)
答案来了:用时时间大概是 3 (500ms)< 1 (1000ms) < 2 (2000ms),几乎就是2倍的速度差了。
V8 Engine —— Hidden Class
我们知道,js是动态脚本语言,什么意思呢,就是你可以很简单的给object添加/删除属性,或者改变其类型,大部分的js解释器(interpreter)使用字典结构,在内存中存储变量属性值的地址,这种方式比起java和C#(非动态语言,当然了C#的dynamic类型另当别论,不在此赘述)要低效率的多,因为js的类型是可以随时转换的,本来使用字典结构结合固定的类型进行判断,可以较容易的找到变量属性值的位置,而在js中就难以实现了。
所以V8引擎就使用了一种高效率的方法叫Hidden Class。其他的引擎也有类似的方法,有叫Map的, Structures的,Hidden Class的等等,在这里我们用Shape来定义它,这样方便大家理解。
当我们定义一个object的时候,它会包含以下内容:
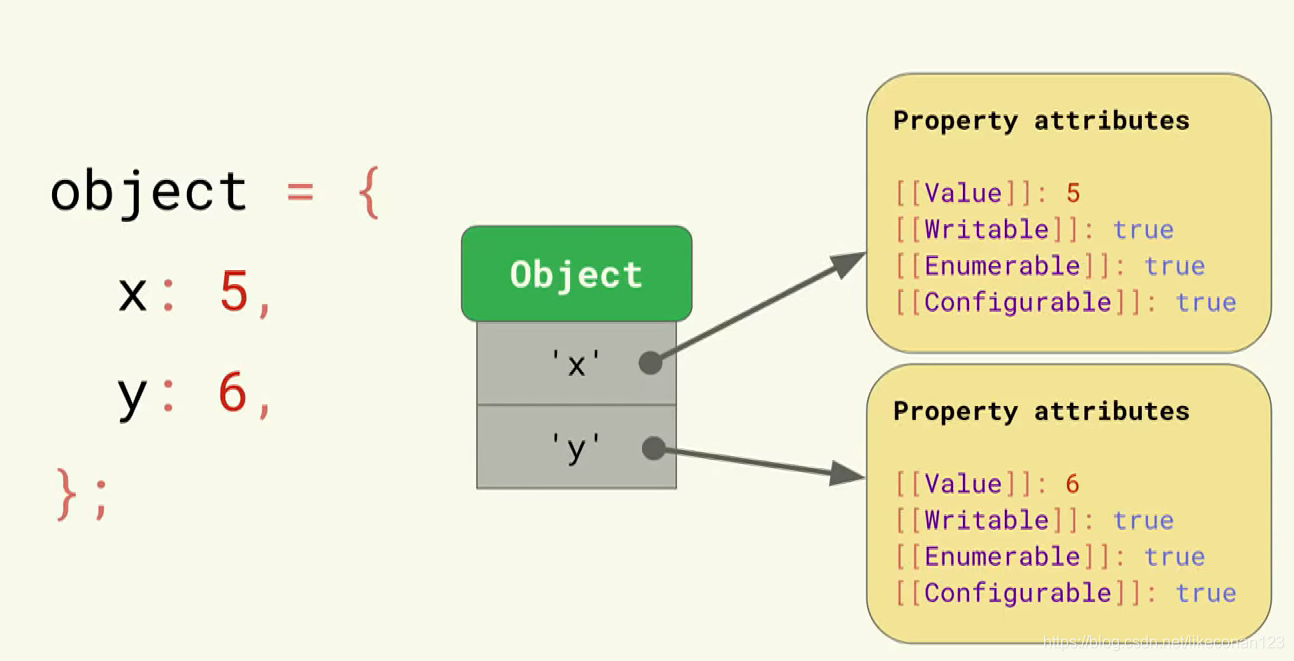

每个属性的意义可以见上表。
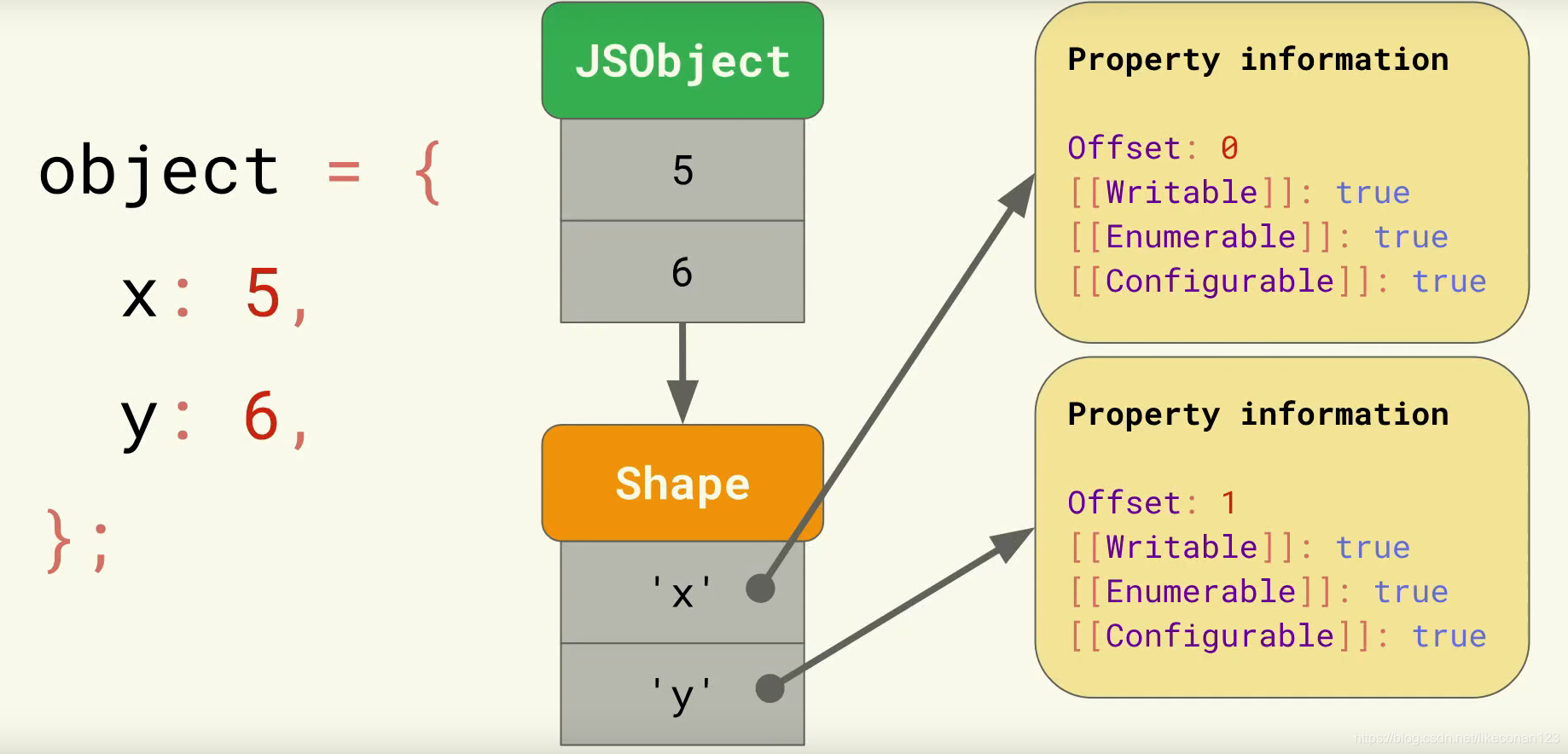
那么结合Shape,当定义一个object的时候,JS引擎会创建一个Shape (可以理解为连续的缓存buffer),它的位置0和1存储了x和y值,如下图:
如果我定义了两个object,都是包含x和y的,那么它就会共用一个shape,如下图:
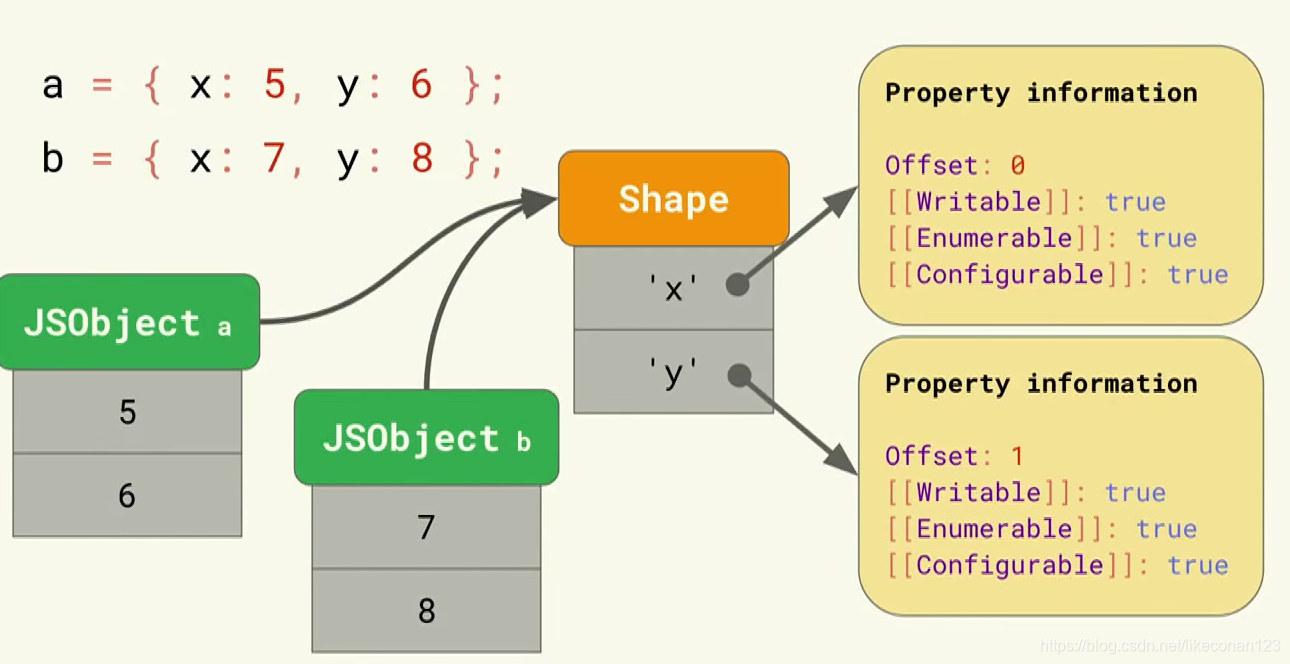
所以到这里我们可以想象的到,我们只要定义相同属性的object,那么都会共用一个shape,当我们要调用任意一个shape的属性值的时候,都可以通过同一个shape的offset来获取到了。
那么,当我们给object添加属性的时候呢?V8引擎会根据类过渡(class transition)原理创建新的shape来标记位置,如下图
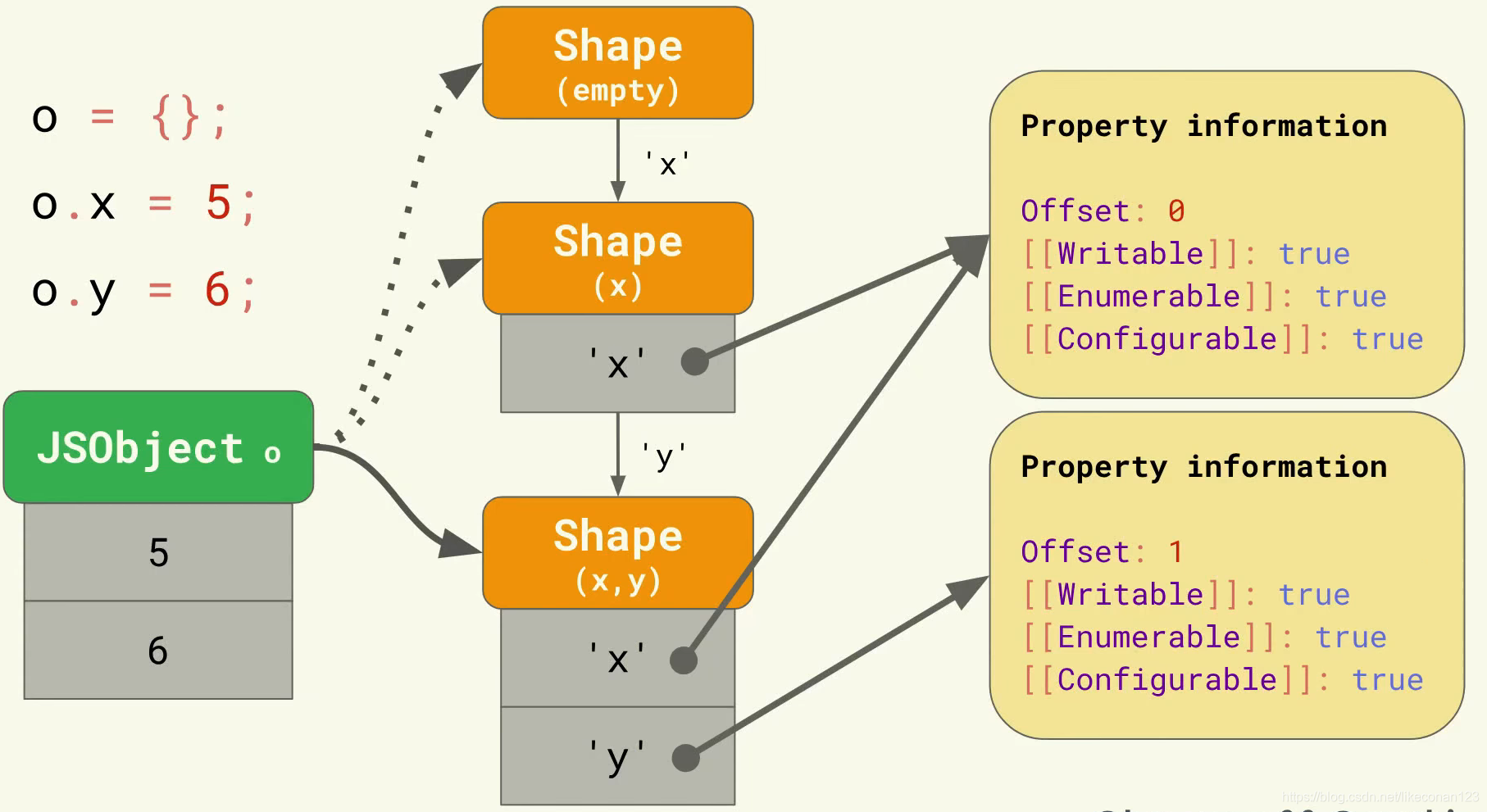
也就是说,我们创建了3个shape,通过过渡链(transition chain)来实现一个object的追溯。
看到这里,大家肯定在想,每多一个shape肯定就会多占用一块内存,那么我为了优化的话,尽量在初始化的时候把属性都定义好就能优化了,Bingo~ 我们可以参照下图来验证:
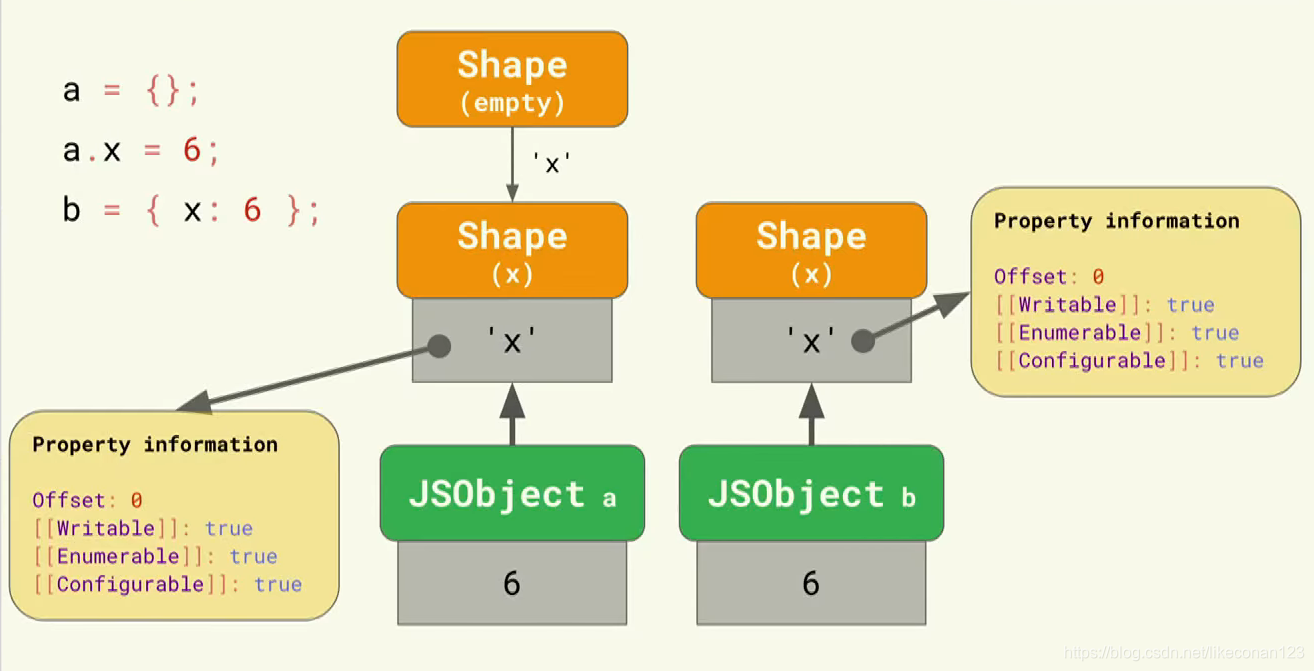
通过以上的原理解释,相信大家肯定能够推算解释出,我们的示例代码的执行速度的区别了
First Case:
1. Shape (empty) for a和b
2. Shape 1....9999999 for a
3. Shape 1....9999999 for b
a和b都共用了相同的shape,可以重复使用
Second Case:
1. Shape (empty) for a和b
2. Shape 1....9999999 for a
3. Shape 10000000....19999999 for b
一共定义了 1 到 19999999的shape,那么second case肯定时间要比first case要花多一倍的时间了
Thrid Case:
1. Shape (empty) for a和b
2. Shape 1....9999999 for a
3. Shape 9999999 ....1 for b
a和b都共用了相同的shape,可以重复使用和1是一样的,这里我们在测试的时候,发现却比1用的时间少了一倍,为什么呢?大家可以思考一下...
前面的V8引擎工作原理图,相信大家看到了,TurboFan会先优化代码,换句话说,在我们定义a和b并且开始赋值的时候,TurboFan通过分析数据,发现了共用相同的shape,而且还是我刚刚用完的,那么直接重新使用一遍就完毕了(毕竟最后转换的是机器语言)
(以上是我的猜测,感兴趣的同学可以研究下V8源码)
JS- array 是一种特殊的object和上述原理一致,在此就不再赘述了~
优化总结:
1. 尽量申明变量的时候一开始就把属性值定义好
2. 尽量倒叙来添加属性(即刚用完刚添加)
鸣谢:我是一名来自盛安德的Shinetecher,感谢盛安德公司及同事们对IT技术的支持,分享和热情,让我有时间和动力完成此博文。
联系:欢迎各位朋友有任何问题和建议留言至此博客下,或者邮件联系:liyijia428@126.com 进行沟通交流学习

















 101
101



 到【灌水乐园】发言
到【灌水乐园】发言







