




 本文深入探讨了分类问题,从二元分类到多元分类,利用mnist数据集展示了随机梯度下降(SGD)、混淆矩阵、精准率、召回率、ROC曲线和AUC分数等评估指标。还介绍了随机森林模型的优势,并探讨了支持向量机(SVM)和SGD在多类别分类中的应用。此外,文章提到了多标签和多输出分类,以实例解释了这些概念。
本文深入探讨了分类问题,从二元分类到多元分类,利用mnist数据集展示了随机梯度下降(SGD)、混淆矩阵、精准率、召回率、ROC曲线和AUC分数等评估指标。还介绍了随机森林模型的优势,并探讨了支持向量机(SVM)和SGD在多类别分类中的应用。此外,文章提到了多标签和多输出分类,以实例解释了这些概念。
目录
1. 学习目标
本章以mnist数据集为例,研究
- 二元分类器
- 多元分类器
- 精准率,召回率
- F1_score
- ROC曲线
2. 数据集介绍
很普通的入门级数据集——mnist手写数字识别
看看其中的一张图片
# 展示图片
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_digit = X[36000]
plot_digit(X[36000].reshape(28,28))

# 更好看的图片展示
def plot_digits(instances,images_per_row=10,**options):
size=28
# 每一行有一个
image_pre_row=min(len(instances),images_per_row)
images=[instances.reshape(size,size) for instances in instances]
# 有几行
n_rows=(len(instances)-1) // image_pre_row+1
row_images=[]
n_empty=n_rows*image_pre_row-len(instances)
images.append(np.zeros((size,size*n_empty)))
for row in range(n_rows):
# 每一次添加一行
rimages=images[row*image_pre_row:(row+1)*image_pre_row]
# 对添加的每一行的额图片左右连接
row_images.append(np.concatenate(rimages,axis=1))
# 对添加的每一列图片 上下连接
image=np.concatenate(row_images,axis=0)
plt.imshow(image,cmap=mpl.cm.binary,**options)
plt.axis("off")
plot_digits(x_train_[:25],images_per_row=5)
plt.show()

3. 二元分类案例
我们用一个二元分类的例子,来说明分类器的评价指标应该怎么样决定
3.1 加载数据
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train_ = x_train.reshape(60000,784)
x_test_ = x_test.reshape(10000,784)
判断一个数字是不是5,如果是5 就是True,不是5 就是False
我们来基于mnist,制作二元分类数据,将标签是5的改为True,不是5的改为False
如下所示:
y_train_5 = (y_train == 5)
效果:

3.2 随机梯度下降(SGD)模型
建立一个随机梯度下降的模型,将图片训练集和自己建立的目标集放入模型中训练,然后考虑模型的评价方法
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(x_train_,y_train_5)
res = sgd_clf.predict([x_train_[0]])
print(res)
3.3 评估分类器
评估分类器比评估回归器要困难的多
使用交叉验证评估随机梯度下降模型
res = cross_val_score(sgd_clf,x_train,y_train_5,cv=3,scoring='accuracy')
print(res)
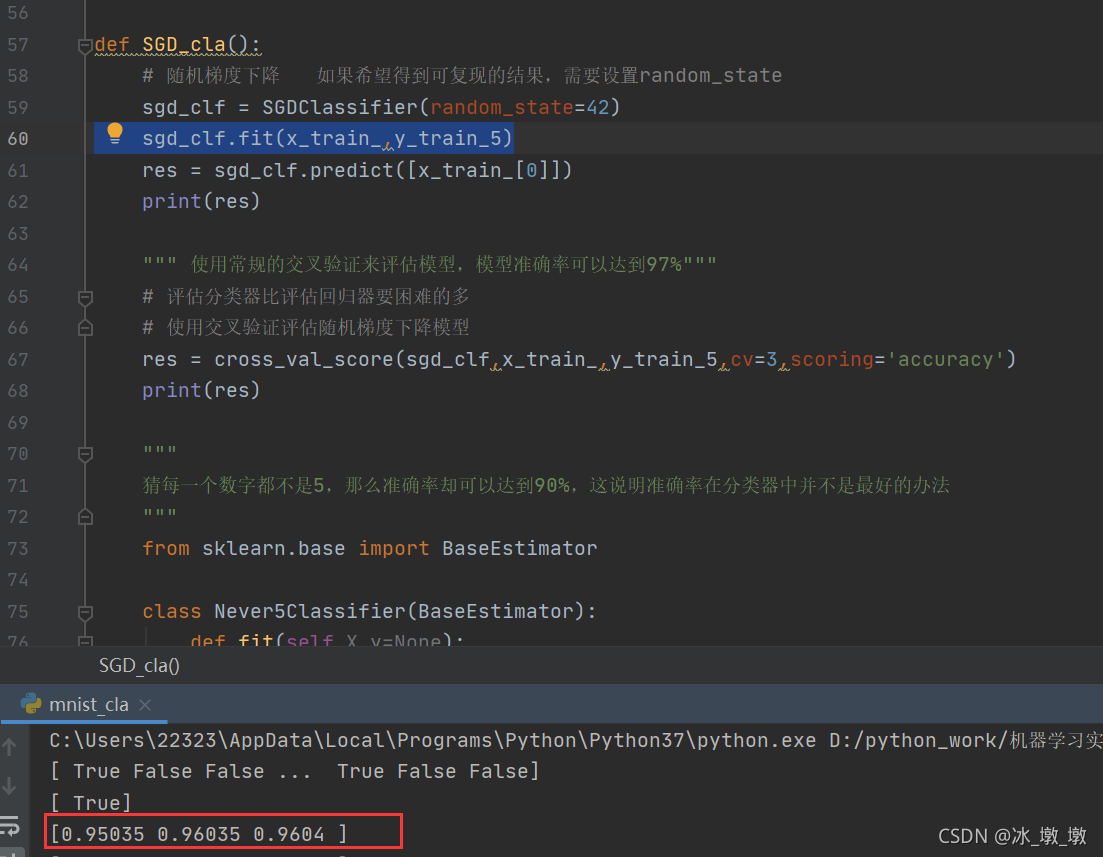
可以发现:
使用常规的交叉验证来评估模型,模型准确率可以达到97%。
一切看起来都很顺利吧,现在有这样一个问题,如果我们建立一个新的分类器,我们这个分类器猜测每一个数字都不是5,那这10个数字,不是5的可能性是90%,我们可以说模型效果很好吗?如下:
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self,X,y=None):
return self
def predict(self,X):
# print(len(X))
# print(np.zeros((len(X), 1),dtype=np.int))
# 返回[[False]] 不管是什么结果,都会返回false
return np.zeros((len(X),1),dtype=bool)
never_5_clf = Never5Classifier()
res = cross_val_score(sgd_clf,x_train_,y_train_5,cv=3,scoring='accuracy')
print(res)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











