




大模型毫无疑问是当前技术发展的热点,成为大家默认的提升生产力工具。
但是,大模型训练主要使用互联网上的公开数据为主,没有企业内部的数据,所以大模型本质上自带的都是一些通用智能。
缺乏行业知识,以及没有实际企业内部的数据,导致大模型也就无法处理真正的企业业务问题,也没有办法作为生产力工具。
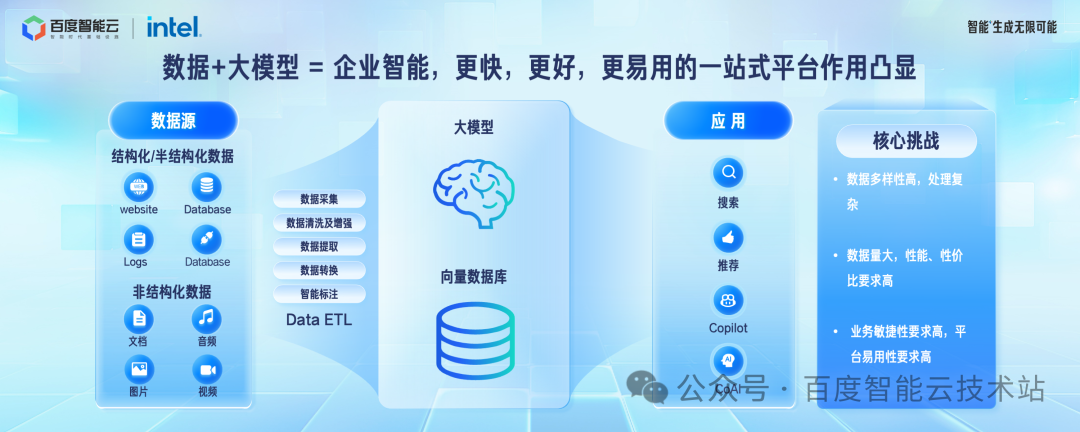
要解决这个问题,业界主要有两种方法,一种是通过精调的方法,一种是通过企业 RAG 的方式;让大模型使用企业的数据,再加上通用模型,从而拥有了企业智能。
要想拥有好的企业智能,会有几个方面的挑战:
-
大模型要的企业的数据,包括结构化和非结构的数据都在原来的各种存储,数据库里面。需要经过一系列加工,包括采集,清洗,转换,标注等等才能转换成大模型或者向量数据库可以处理的数据,从而支撑后面的各种业务。因此需要有很好的平台和能力可以支撑这些数据的处理、存储、以及查询。
-
企业业务持续经营,数据规模会同步增长。同时,大模型进一步促进更多的数据增加。这对数据平台的性能,性价比要求进一步提高。
-
对于企业来说,先人一步构建好的应用,是非常关键的。所以大模型业务天然是敏捷性要求高的业务。那为了更容易的构建业务,平台本身的易用性是非常关键的。
所以,在大模型时代,企业原来生产系统,以及新智能的应用对平台的挑战是越来越大的。更快,更好,更易用的一站式平台作用也更凸显。
接下来我给大家介绍一下在过去一年时间,百度智能云在数据库和大数据领域的重要更新,以便更好地帮助企业更好的在大模型时代迎接数据处理和存储的挑战。
我将从内核和平台两个维度展开介绍。
首先是内核维度。如果我们从企业数据量大小来分,通常也可以认为,越是在线数据,数据量相对较少,价值也相对较高。
通常可以分为缓存数据、关系型数据、文档数据、向量数据、在线分析数据、离线分析数据。企业的数据有不同的类型,所以需要不同能力的引擎才能处理好这些数据。
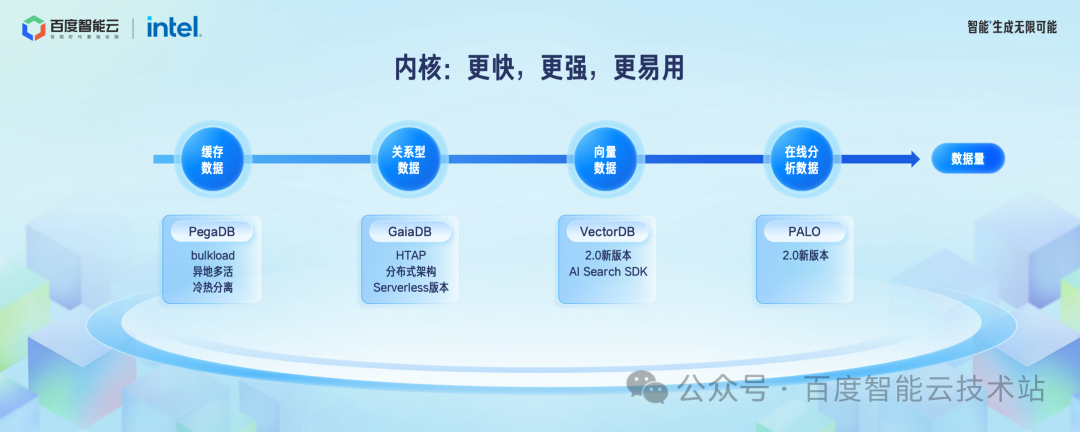
首先看缓存数据。百度智能云有自研的 KV 数据库 PegaDB,对标开源 Redis 等产品,除了传统的互联网场景,KV 数据库在 AI 场景也有很广泛的应用。缓存数据库核心挑战还是在性能、成本、高可用方面,在过去一年里面,我们核心优化了这些方面,性能上支持批量加载,高用上支持异地多活的能力,成本上支持冷热分离,通过把相对较冷的数据自动迁移到 SSD 上显著降低成本。
在 KV 数据库这个领域, PegaDB 处在业界领先的位置,体现在几个方面:
首先是性价比上,我们通过领先的价格,价
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









