




 本文围绕STM32单片机展开,介绍了液晶显示逻辑,包括字符编码(如ASCII、中文编码GB2312、GBK、Gig5、Unicode等),阐述了汉字显示原理,即通过内码查找点阵库解析显示,还提及字库生成方法。最后给出实验程序,实现开机检测字库并显示汉字的功能。
本文围绕STM32单片机展开,介绍了液晶显示逻辑,包括字符编码(如ASCII、中文编码GB2312、GBK、Gig5、Unicode等),阐述了汉字显示原理,即通过内码查找点阵库解析显示,还提及字库生成方法。最后给出实验程序,实现开机检测字库并显示汉字的功能。
目录
1. 液晶显示逻辑
字符编码:
由于计算机只能识别 0 和 1,文字也只能以 0 和 1 的形式在计算机里存储,所以我们需要对文字进行编码才能让计算机进行处理,编码的过程就是规定特定的 01数字串 来表示特定的文字,最简单的字符编码例子就是ASCII码。例如在C语言的编译环境下,我们输入"abcd",实际上存储到内存中的是0x61 0x62 0x63 0x64(也就是字符对应的ASCII码)
ASCII编码:
在程序设计中使用ASCII编码表约定了一些控制字符、英文及数字。它们在存储器中,本质也是二进制数,只是我们约定这些二进制数可以表示某些特殊意义,如以ASCII编码解释数字 “0x41” 时,它表示英文字符 “A”
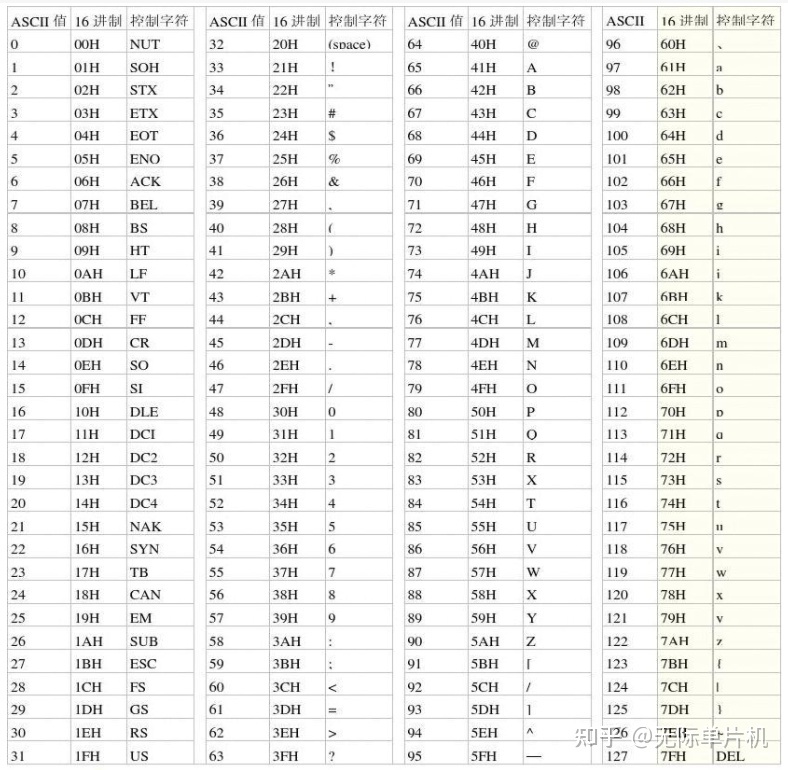
ASCII码表分为两部分,第一部分是控制字符和通讯专用字符,它们的数字编码从0~31,它们并没有特定的图形显示,但会根据不同的应用程序,对文本显示有不同的影响。ASCII码的第二部分包括空格、阿拉伯数字、标点符号、大小写英文字母以及 “DEL(删除控制)”,这部分符号的数字编码从32~127,除最后一个DEL符号外,都能以图形的方式来表示,它们属于传统文字书写系统的一部分。
后来,随着计算机被引入到其他国家,由于它们使用的不是英语,他们使用的字母在ASCII码表中没有定义,所以他们采用了127号之后的位来表示这些新的字母,在此基础之上加入了各种形状,一直编码到255。从128到255这些字符被称为ASCII扩展字符集。
中文编码:
英文书写系统是由26个基本字母组成,利用26个字母可以组合出不同的单次,所以用ASCII码表就能表示整个英文书写系统。
中文书写系统中的汉字是独立的方块,由于汉字非常多,常用字就有6000多个,如果像ASCII编码表那样只使用1个字节最多只能表示256个汉字,所以我们使用2个字节来编码。打个比方说:B0A3 =哎 ,通过两个字节的1011 0000 1010 0011来表示一个中文汉字哎。
GB2312标准:
我国首先定义的是GB2312标准。它把ASCII码表127号之后的扩展字符集直接取消掉,规定小于127的编码按原来ASCII标准解释字符。当两个大于127的字符连在一起时,就表示一个汉字,第一个字节使用(0xA1~0xFE)编码,第二个字节使用(0xA1~0xFE)编码,这样的编码组合起来可以表示7000多个符号,其中包括6763个汉字。

如上表,当我们设定系统使用GB2312标准的时候,他遇到一个字符串时,会按字节检测字符值的大小,若遇到连续两个字节的数值都大于127时就把这两个连续的字节合在一起,用GB2312解码,若遇到的数值小于127,就直接用ASCII把它解码。
区位码:
GB2312编码对所收录字符进行了 “分区” 处理,共94个区,每个区含94个位,共8836个码位。这种表示方式也称为区位码。
- 01-09区收录除汉字外的682个字符。
- 10-15区为空白区,没有使用。
- 16-55区收录3755个一级汉字,按拼音排序。
- 56-87区收录3008个二级汉字,按部首/笔画排序。
- 88-94区为空白区,没有使用。
比如说: “啊” 字是GB2312编码中的第一个汉字,它位于 16 区的 01 位,所以它的区位码就是1601.
GBK编码:
虽然GB2312编码中表示的6763个汉字已经覆盖中国大陆99.75%的使用率,但是有些生僻字在人名、文言文中出现的频率还是非常高的。
为此在GB2312标准的基础上又增加了14240个新汉字和符号,这个方案被称为GBK标准。如果按照GB2312原来的标准进行编码,2个字节已经存储不下了,因此GBK标准中只要第一个字节大于127就表示这是一个汉字的开始,这样同时也兼容ASCII和GB2312标准。
Gig5编码:
在台湾、香港等地区,使用较多的是Gig5编码,它的主要特点是收录了繁体字。Big5编码和GBK编码是不兼容的。
Unicode编码:
由于各个国家或地区都根据使用自己的文字系统制定标准,同一个编码在不同的标准里表示不一样的字符,各个标准互不兼容,无法用一个标准表示所有的字符。国际标准化组织ISO舍弃了地区性的方案,重新给全球上所有文化使用的字母和符号进行编号,该编号集被称为Universal Multiple-OcteCoded Character Set,简称UCS,也被称为Unicode。
2. 汉字显示原理
汉字在液晶上的显示其实就是一些点的显示与不显示,这就相当于我们的笔一样,有笔经过的地方画出来,没有经过的地方就不画出来。所以我们要显示汉字,首先要知道汉字的点阵数据,这些数据可以由专门的软件来生成。只要知道了汉字点阵的生成方法,那么我们在程序里面就可以把这个点阵数据解析成一个汉字了。(同51点阵屏的显示原理一样)
知道显示了一个汉字,就可以推及整个汉字库了。汉字在各种文件里面的存储不是以点阵数据的形式存储的(否则那占用的空间就太大了),而是以内码的形式(1个高8位,1个低8位)存储的,就是GB2312/GBK/BIG5等这几种的一种,每个汉字对应着一个内码,再知道这个内码之后再去字库里面查找这个汉字的点阵数据,然后在液晶上显示出来。这个过程我们是看不到的,但是计算机是要去执行的。
汉字内码(GBK/GB2312)--->查找点阵库--->解析--->显示
接下来很大的问题就是:制作一个与汉字内码对得上号的汉字点阵库。方便单片机的查找。每个GBK码由2个字节组成,第一个字节为0x81~0xFE,第二个字节分成两部分,一是0x40~0x7E,二是0x80~0xFE。
我们习惯上把第一个字节代表的意义称为区,那么GBK里面总共有126个区(0xFE-0x81+1),每个区内有190个汉字(0xFE-0x80+0x7E-0x40+2),总共就有126*190=23940个汉字。我们的点阵库只要按照这个编码规则从0x8140开始,逐一建立,每个区的点阵大小为每个汉字所用的字节数*190(每个区有190个汉字,190乘以每个汉字所占的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4709
4709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









