






 本文介绍了一个使用Python爬取斗图网表情包的实例,通过解析网页获取图片URL,并利用requests和BeautifulSoup库实现自动化下载。文章详细展示了如何处理懒加载图片,以及如何保存图片到本地的方法。
本文介绍了一个使用Python爬取斗图网表情包的实例,通过解析网页获取图片URL,并利用requests和BeautifulSoup库实现自动化下载。文章详细展示了如何处理懒加载图片,以及如何保存图片到本地的方法。
url: 协议+路径+参数 schema://path?query
麦子学院 http://www.maiziedu.com/wiki/crawler/protocol/
py2 与py3的区别:https://www.cnblogs.com/lucas0625/p/7825849.html

斗图网表情url链接
import requests
import os
import urllib
from bs4 import BeatifulSoup
BASE_PAGE_URL=‘https://www.doutula.com/photo/list/?page=’
PAGE_URL_LIST=[]
for x in range(1,1891):
url=BASE_PAGE_URL+str(x)
print(url)
在一个页面中拿到页面的url,拿图片的url
response=requests.get('https://www.doutula.com/photo/list/?page=1892')
print(response.content)
content=response.content
soup=BeatifulSoup(content,'lxml')
相同的图片都有img-responsive lazy image_dta这些类
img_list=soup.find_all('img',attrs={'class':'img-responsive lazy image_dta'})
for img in img_list:
src没有显示出来,可能会出现一个loading 图片,需要找data-original
print img
print(img['data-oraginal'])
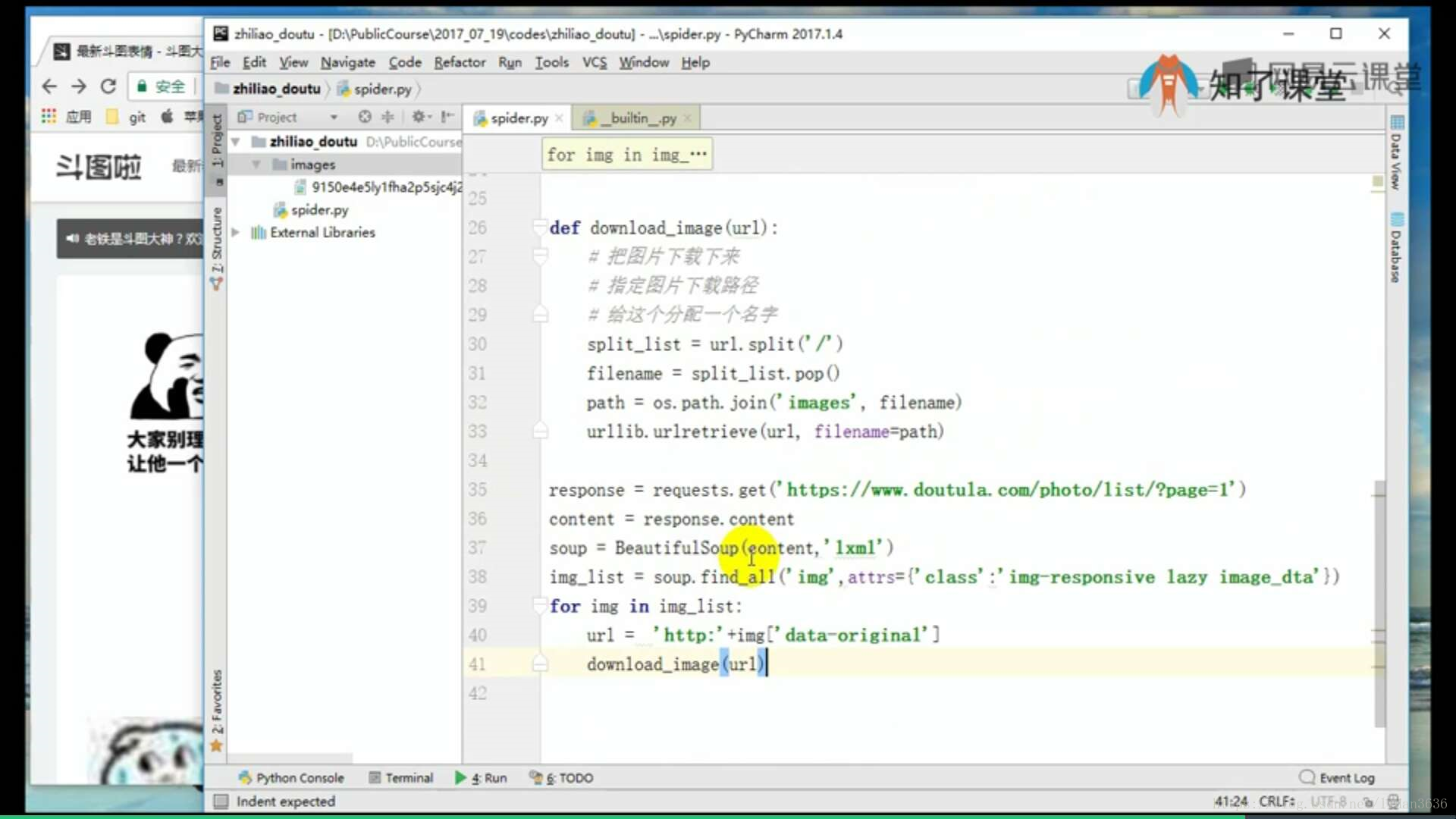
print('http:'+img['data-oraginal'])
print('------'*30)
总结:soup=BeatifulSoup(requests.get('').content,'lxml')
img_list=soup.find_all('img',attrs={'class':'img-responsive lazy image_dta'})
for img in img_list:
print('http:'+img['data-oraginal'])
把图片下载下来:
指定图片下载路径 给这个分配一个名字
url='https://ws1.sinaimg.cn/large/6af89bc8gw1f8njll5s6gj205405k74a.jpg'
split_list=url.split('/') ['https','ws1.sinaimg.cn','large']
dodo=split_list.pop() ['6af89bc8gw1f8njll5s6gj205405k74a.jpg']
path=os.path.join('images',filename)
urllib.urlretrieve(url,filename=path) urllib.urlretrieve(url,filename=dodo)


















 3067
3067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}