



Redis 客户端
客户端组件1:Jedis
Jedis 是老牌的 Redis 的 Java 实现客户端,提供了比较全面的 Redis 命令的支持。
优点:
-
支持全面的 Redis 操作特性(可以理解为API比较全面)。
缺点:
-
使用阻塞的 I/O,且其方法调用都是同步的,程序流需要等到 sockets 处理完 I/O 才能执行,不支持异步;
-
Jedis 客户端实例不是线程安全的,所以需要通过连接池来使用 Jedis。
客户端组件2:Redisson
Redisson 是在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。Redisson 提供了使用Redis 的最简单和最便捷的方法。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务。其中包括:
BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)
Redisson 的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
优点:
-
使用者对 Redis 的关注分离,可以类比 Spring 框架,这些框架搭建了应用程序的基础框架和功能,提升开发效率,让开发者有更多的时间来关注业务逻辑;
-
提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列等。
-
Redisson基于Netty框架的事件驱动的通信层,其方法调用是异步的。
-
Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作
缺点:
-
Redisson 对字符串的操作支持比较差。
客户端组件3:lettuce
lettuce是可扩展的线程安全的 Redis 客户端,支持异步模式。lettuce 底层基于 Netty,支持高级的 Redis 特性,比如哨兵,集群,管道,自动重新连接和Redis数据模型。lettuce能够支持redis4,需要java8及以上。lettuce是基于netty实现的与redis进行同步和异步的通信。
优点:
-
支持同步异步通信模式;
-
Lettuce 的 API 是线程安全的,如果不是执行阻塞和事务操作,如BLPOP和MULTI/EXEC,多个线程就可以共享一个连接。
三者比较
Jedis使直接连接redis server,如果在多线程环境下是非线程安全的,这个时候只有使用连接池,为每个jedis实例增加物理连接 ;
lettuce的连接是基于Netty的,连接实例(StatefulRedisConnection)可以在多个线程间并发访问,StatefulRedisConnection是线程安全的,所以一个连接实例可以满足多线程环境下的并发访问,当然这也是可伸缩的设计,一个连接实例不够的情况也可以按需增加连接实例。
Jedis 和 lettuce 是比较纯粹的 Redis 客户端,几乎没提供什么高级功能。Jedis 的性能比较差,所以如果你不需要使用 Redis 的高级功能的话,优先推荐使用 lettuce。
Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
如果需要分布式锁,分布式集合等分布式的高级特性,添加Redisson结合使用,因为Redisson本身对字符串的操作支持很差。Redisson 的优势是提供了很多开箱即用的 Redis 高级功能,如果你的应用中需要使用到 Redis 的高级功能,建议使用 Redisson。
具体 Redisson 的高级功能可以参考:https://redisson.org/
使用建议
建议:lettuce + Redisson。
在spring boot2之后,redis连接默认就采用了lettuce。就像 spring 的本地缓存,默认使用Caffeine一样,这就一定程度说明了,lettuce 比 Jedis在性能的更加优秀。
链接断裂怎么办?
Jedis有心跳,能保持长连接,lettuce好像没有心跳。阿里 ecs 搭的redis tcp长时间没有传输就会断开,但是lettuce感知不到,再执行redis请求就会提示链接不可用。具体来说,可以通过用netty的空闲检测机制来维持连接。
注意:是空闲检测 不是心跳机制。
什么是心跳机制
心跳是在TCP长连接中,客户端和服务端定时向对方发送数据包通知对方自己还在线,保证连接的有效性的一种机制。在服务器和客户端之间一定时间内没有数据交互时, 即处于 idle 状态时, 客户端或服务器会发送一个特殊的数据包给对方, 当接收方收到这个数据报文后, 也立即发送一个特殊的数据报文, 回应发送方, 此即一个 PING-PONG 交互。自然地, 当某一端收到心跳消息后, 就知道了对方仍然在线, 这就确保 TCP 连接的有效性。
空闲检测 是心跳的基础机制。
什么是空闲检测
就是检测通道中的读写数据包,如果一段时间内,没有收到读写数据包,就会出发 IdleStateEvent 空闲状态事件。所以,可以借助这个机制,主动关闭 空闲的、被异常断开的连接。
import io.lettuce.core.resource.ClientResources;
import io.lettuce.core.resource.NettyCustomizer;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.Channel;
import io.netty.channel.ChannelDuplexHandler;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.timeout.IdleStateEvent;
import io.netty.handler.timeout.IdleStateHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ClientConfig {
@Bean
public ClientResources clientResources(){
NettyCustomizer nettyCustomizer = new NettyCustomizer() {
@Override
public void afterChannelInitialized(Channel channel) {
channel.pipeline().addLast(
//此处事件必须小于超时时间
new IdleStateHandler(40, 0, 0));
channel.pipeline().addLast(new ChannelDuplexHandler() {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
ctx.disconnect();
}
}
});
}
@Override
public void afterBootstrapInitialized(Bootstrap bootstrap) {
}
};
//替换掉 NettyCustomizer 通道初始化处理器
return ClientResources.builder().nettyCustomizer(nettyCustomizer ).build();
}
}
参考
-
RESP协议1:https://www.cnblogs.com/4a8a08f09d37b73795649038408b5f33/p/9998245.html
-
RESP协议2:https://my.oschina.net/u/2474629/blog/913805
-
RESP协议3:https://www.cnblogs.com/throwable/p/11644790.html
-
Redis的三个框架:Jedis,Redisson,Lettuce:https://www.cnblogs.com/williamjie/p/11287292.html
-
redis客户端选型-Jedis、lettuce、Redisson:https://blog.youkuaiyun.com/a5569449/article/details/106891111/
Order by 性能提升10倍方案
Order by 工作原理
Order by 执行流程,分为两步,具体如下:
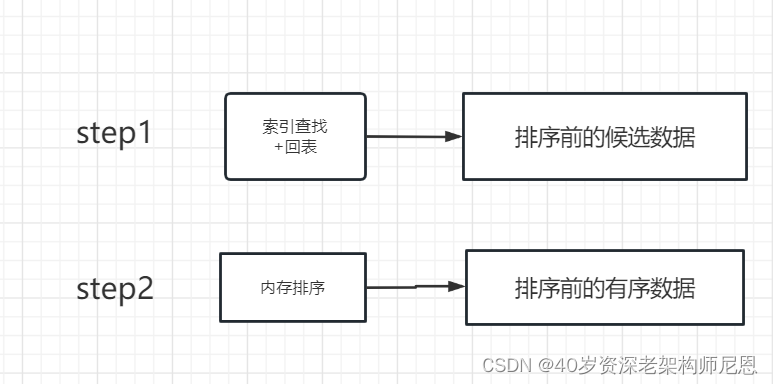
第1步:索引的查找
根据where 后面的字段,进行 二级索引的查找,找到后再回表 聚集索引,拿到需要的字段
第2步:原始数据的排序
原始数据的数据, 并不是按照 order by 有序的。所以,需要按照 order by 字段,进行排序。接下来,排序的地点在哪里呢?
-
优先选择内存。因为内存的性能高。
-
如果原始的数据实在规模太大,就借助磁盘进行排序。
用于排序的内存,称为 sort_buffer。原始数据放在内存 sort_buffer 中。 其实 MySQL 会给每个线程分配一块内存用于排序的 sort_buffer。
Explain查看执行计划
用Explain关键字查看一下执行计划。
select name, age, city from user where city = '北京' order by age limit 5;
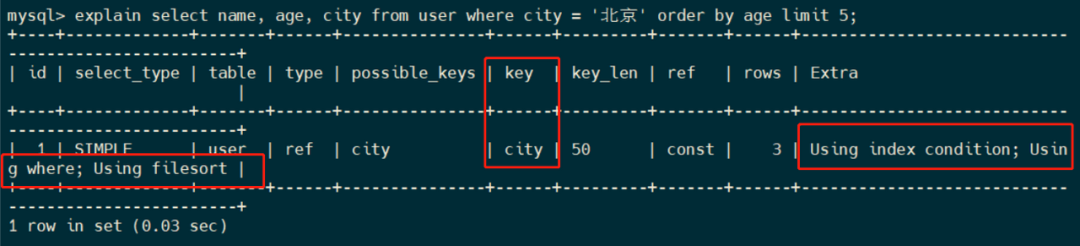
可以看到:
-
key 字段表示使用到 city 索引
-
Extra 字段中的
Using index condition表示用到了索引条件 -
Using filesort表示用到了文件排序
用到文件排序,说明第一次查出来的 原始数据,在内存放不下, 需要借助 磁盘空间进行排序,磁盘IO的性能比较低的,所以,需要进行调优。
Order by 执行完整流程,如下:
-
当前线程首先初始化 sort_buffer 块。
-
然后从 city 索引树从查询一条满足
city='北京'的主键 ID, 比如图中的id=2。 -
接着在聚簇索引树中查询
id=2的一行数据,将name、age、city三个字段的值,存到sort_buffer。 -
继续重复前两个步骤,直到 city 索引树中找不到
city='北京'的主键 ID。 -
最后在sort_buffer中,将所有数据根据
age进行排序,取前 5 行返回给客户端。
全字段排序就是将查询所需的字段,如name、age、city三个字段数据全部存到 sort_buffer 中。
3个核心概念
-
全字段排序
-
外部排序
-
rowid 排序
全字段排序
sort_buffer是 MySQL 为每个任务线程维护的一块内存区域,用于进行排序。sort_buffer 的大小可以通过 sort_buffer_size 来设置。sort_buffer_size 是一个用于控制sort_buffer内存大小的参数。
sort_buffer 是一块固定大小的内存,如果数据量太大,sort_buffer 放不下怎么办呢?
外部排序
如果要排序的数据小于 sort_buffer_size,那在 sort_buffer 内存中就可以完成排序,如果要排序的数据大于 sort_buffer_size,则需要外部排序,借助磁盘文件来进行排序。
通过执行以下命令,可以查看 SQL 语句执行中是否采用了磁盘文件辅助排序。
set optimizer_trace = "enabled=on";
select name,age,city from user where city = '北京' order by age limit 5;
select * from information_schema.optimizer_trace;
可以从number_of_tmp_files中看出,是否使用了临时文件。
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`user`",
"field": "age"
}
],
"filesort_priority_queue_optimization": {
"limit": 5,
"rows_estimate": 992,
"row_size": 112,
"memory_available": 262144,
"chosen": true
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 3,
"examined_rows": 28,
"number_of_tmp_files": 0,
"sort_buffer_size": 720,
"sort_mode": "<sort_key, additional_fields>"
}
}
]
}
}
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果 number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件后,当 sort_buffer 内存不足时,先进行排序,将排序后的数据存放到一个小磁盘文件中,清空 sort_buffer。
然后继续存放数据到 sort_buffer,重复以上步骤。最后将多个磁盘小文件合并成一个有序的大文件。
Tips: 磁盘小文件合并排序,使用的是归并排序算法
这样依然会存在问题,数据存放到临时磁盘小文件,然后还需要归并排序为大文件,再读入到内存中,返回结果集,整体排序效率低下。
rowid 排序
要解决上述问题,可以将只需要用于排序的字段和主键 ID 放入 sort_buffer 中,也就是 rowid 排序,这样就可以在 sort_buffer 中完成排序。
max_length_for_sort_data 是一个用于表示 MySQL 用于排序行数据长度的一个参数,如果单行数据的长度超过了这个值,那么可能会导致采用临时文件排序,mysql 会换用 rowid 排序。
可以通过命令看下这个参数取值。
show variables like 'max_length_for_sort_data';
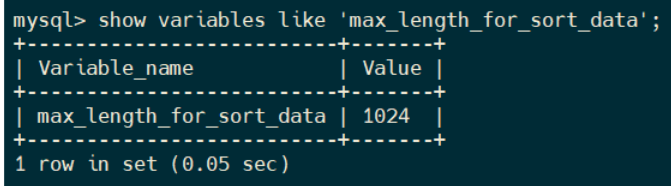
max_length_for_sort_data 默认值是 1024。本文中name,age,city 长度=64+4+64=132<1024, 所以走的是全字段排序。
我们执行以下命令,改下参数值,再重新执行 SQL。
set max_length_for_sort_data = 32;
select name,age,city from user where city = '北京' order by age limit 5;
使用 rowid 排序的后,执行示意图如下:
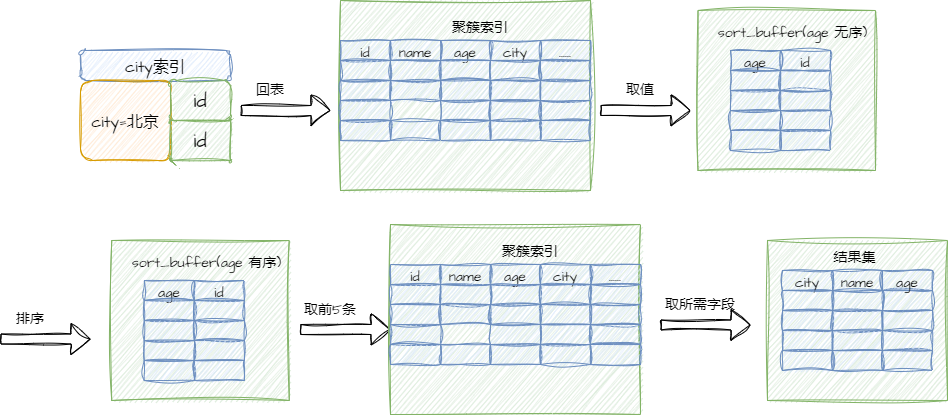
对比全字段排序,rowid 排序最后需要根据主键 ID 获取对应字段数据即多了回表查询。
当需要查询的数据在索引树中不存在的时候,需要再次到聚集索引中去获取,这个过程叫做回表
我们通过执行以下命令,可以看到是否使用了 rowid 排序的:
set optimizer_trace = "enabled=on";
select name,age,city from user where city = '北京' order by age limit 5;
select * from information_schema.optimizer_trace;
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`user`",
"field": "age"
}
],
"filesort_priority_queue_optimization": {
"limit": 5,
"rows_estimate": 992,
"row_size": 8,
"memory_available": 262144,
"chosen": true
},
"filesort_execution": [],
"filesort_summary": {
"rows": 3,
"examined_rows": 28,
"number_of_tmp_files": 0,
"sort_buffer_size": 96,
"sort_mode": "<sort_key, rowid>"
}
}
]
}
}
sort_mode表示排序模式为 rowid 排序。
Order by 的优化思路
-
联合索引优化
如果数据本身是有序的,那就不需要排序,而索引数据本身是有序的,所以,我们可以通过建立联合索引,跳过排序步骤。
-
参数优化
可以通过调整max_length_for_sort_data等参数优化排序算法;
参数优化
通过调整参数,也可以优化order by的执行。
-
调整 sort_buffer_size 参数的值。如果 sort_buffer 值太小而数据量大的话,MySQL 会采用磁盘临时文件辅助排序。MySQL 服务器配置高的情况下,可以将参数调大些。
-
调整 max_length_for_sort_data 的值,值太小的话 MySQL 会采用 rowid 排序,会多一次回表操作导致查询性能降低。同样可以适当调大些。
Select分页 性能提升100倍方案
MySQL分页起点越大查询速度越慢
在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取。
-
limit语句的查询时间与起始记录的位置成正比
-
mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
SELECT * FROM 表名 limit m,n;
SELECT * FROM table LIMIT [offset,] rows;
注释:Limit子句可以被用于强制 SELECT 语句返回指定的记录数。Limit接受一个或两个数字参数,参数必须是一个整数常量。如果给定两个参数,
-
第一个参数指定第一个返回记录行的偏移量,
-
第二个参数指定返回记录行的最大数目。
1.m代表从m+1条记录行开始检索,n代表取出n条数据。(m可设为0)
2.值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据。
如:SELECT * FROM 表名 limit 6,-1;
表示:取出第6条记录行以后的所有数据。
3.若只给出m,则表示从第1条记录行开始算一共取出m条。
MySQL百万级数据大分页查询优化
方法1: 直接使用数据库提供的SQL语句
语句样式:
SELECT * FROM 表名称 LIMIT start, count
功能
Limit限制的是从结果集的start 位置处取出count 条输出,其余抛弃。
原因/缺点:
全表扫描,速度会很慢。而且,有的数据库结果集返回不稳定。
适应场景:
适用于数据量较少的情况,元祖数量、记录数量级别:百/千级
方法2: 建立主键或唯一索引, 利用索引(假设每页10条)
语句样式:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) LIMIT M
除了主键,也可以 利用唯一键索引快速定位部分元组,避免全表扫描
比如: 读第1000到1019行元组(pk是唯一键).
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因:
索引扫描,速度会很快。
缺点:
如果数据查询出来并不是按照pk_id排序,并且pk_id全部数据都存在没有缺失可以作为序号使用,不然,分页会有漏掉数据。
适应场景:
-
适用于数据量多的情况(元组数上万)
-
id数据没有缺失,可以作为序号使用
方法3: 基于索引再排序
语句样式:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
适应场景:
适用于数据量多的情况(元组数上万),最好ORDER BY后的列对象是主键或唯一索引,id数据没有缺失,可以作为序号使用。
使得ORDERBY操作能利用索引被消除但结果集是稳定的。
原因:
索引扫描,速度会很快,但MySQL的排序操作,只有ASC没有DESC。MySQL中,索引存储的排序方式是ASC的,没有DESC的索引。这就能够理解为啥order by 默认是按照ASC来排序的。
虽然索引是ASC的,但是也可以反向进行检索,就相当于DESC。
方法4: 基于索引使用prepare
语句样式:
PREPARE stmt_name FROM SELECT * FROM 表名称
WHERE id_pk > (?*10) ORDER BY id_pk ASC LIMIT M
第一个问号表示pageNum
适应场景:
大数据量
原因:
索引扫描,速度会很快。prepare语句又比一般的查询语句快一点。
方法5: 利用"子查询+索引"快速定位元组
利用"子查询+索引"快速定位元组的位置,然后再读取元组。
SELECT * FROM your_table
WHERE
id <= (
SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize)
ORDER BY id desc LIMIT $pagesize
方法6: 利用"连接+索引"快速定位元组的位置,读取元组
SELECT * FROM your_table AS t1
JOIN
(SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize) AS t2
WHERE t1.id <= t2.id
ORDER BY t1.id desc LIMIT $pagesize;
方法7: 利用表的索引覆盖来调优
利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外MySQ中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
方法8: 利用复合索引进行优化
如果对于有where 条件,又想走索引用limit的,必须设计一个索引,将where 放第一位,limit用到的主键放第2位,而且只能select 主键。
MySQL数据库开发三十六条军规
一.核心军规
-
尽量不在数据库做运算,cpu计算的事务必移至业务层
-
控制表、行、列数量【控制单张表的数据量 1年/500W条,超出可做分表】,【单库表数据量不超过300张】 、【单张表的字段个数不超过50个,多了拆表】
-
三大范式没有绝对的要使用,效率优先时可适当牺牲范式
-
拒绝3B(拒绝大sql语句:big sql、拒绝大事物:big transaction、拒绝大批量:big batch)
二.字段类军规
-
用好数值类型(用合适的字段类型节约空间); 如:一个字段注定就只有1跟2 要设计成 int(1) 而不是 int(11)
-
字符转化为数字(能转化的最好转化,同样节约空间、提高查询性能)
如,一个字段注定就只有1跟2,要设计成int(1) 而不是char(1) 查询优化如:字段类型是 char(1) 查询应当where xx='1' 而不是 xx=1 会导致效率慢 -
避免使用NULL字段
NULL字段很难查询优化、NULL字段的索引需要额外空间、NULL字段的复合索引无效
如:要设计成 `c` int(10) NOT NULL DEFAULT 0 而不是 `c` int(10) NOT NULL
-
少用text/blob类型(尽量使用varchar代替text字段), 需要请拆表
-
不在数据库存图片,请存图片路径,然后图片文件存在项目文件夹下。
三.索引类军规
-
合理使用索引
改善查询,减慢更新,索引一定不是越多越好;
如:不要给性别创建索引
-
字符字段必须建前缀索引;
`pinyin` varchar(100) DEFAULT NULL COMMENT '小区拼音', KEY `idx_pinyin` (`pinyin`(8))
-
不在索引做列运算;
如:WHERE to_days(current_date) – to_days(date_col) <= 10
改为:WHERE date_col >= DATE_SUB('2011-10- 22',INTERVAL 10 DAY);
-
innodb主键推荐使用自增列
主键建立聚簇索引,主键不应该被修改,字符串不应该做主键
如:用独立于业务的AUTO_INCREMENT
-
不用外键(由程序保证约束);
四.SQL类军规
-
sql语句尽可能简单
一条sql只能在一个cpu运算,大语句拆小语句,减少锁时间,一条大sql可以堵死整个库;
-
简单的事务;
-
避免使用trig/func(触发器、函数不用,由客户端程序取而代之);
-
不用select *(消耗cpu,io,内存,带宽,这种程序不具有扩展性);
如:select a,b,c 会比 select * 好 只取需要列
-
OR改写为 IN
如:where a=1 or a=2 改 a in(1,2)
-
OR改写为UNION
针对不同字段 where a=1 or b=1
改:select 1 from a where a=1 union select 1 from a where b=1
-
避免负向%;
如 where a like %北京% 改为 where a like '北京%'
-
limit高效分页(limit越大,效率越低);
如 Limit 10000,10 改为 where id >xxxx limit 11
-
使用union all替代union(union有去重开销);
-
高并发db少用2个表以上的join;
-
使用group by 去除排序加快效率;
如:group by name 默认是asc排序
改:group by name order by null 提高查询效率
-
请使用同类型比较;
如:where 双精度=双精度 数字=数字 字符=字符 避免转换导致索引丢失
-
打散大批量更新;
如:在凌晨空闲时期更新执行
五.约定类军规
-
隔离线上线下
如:开发用dev库,测试用qa库,模拟用sim库, 线上用线上库,开发无线上库操作权限
-
不在程序端加锁,即外部锁,外部锁不可控,会导致 高并发会炸,极难调试和排查
-
统一字符 UTF-8 校对规则 utf8_general_ci 出现乱码 SET NAMES UTF8
-
统一命名规范,库表名一律小写,索引前缀用idx_ 库名 用缩写(2-7字符),不使用系统关键字保留字命名
参考链接
https://blog.youkuaiyun.com/qq_43518425/article/details/113876287
https://blog.youkuaiyun.com/whzhaochao/article/details/49126037
https://blog.youkuaiyun.com/wuzhangweiss/article/details/101156910
https://blog.youkuaiyun.com/Jerome_s/article/details/44992549
处理Nginx后端服务大量TIME-WAIT
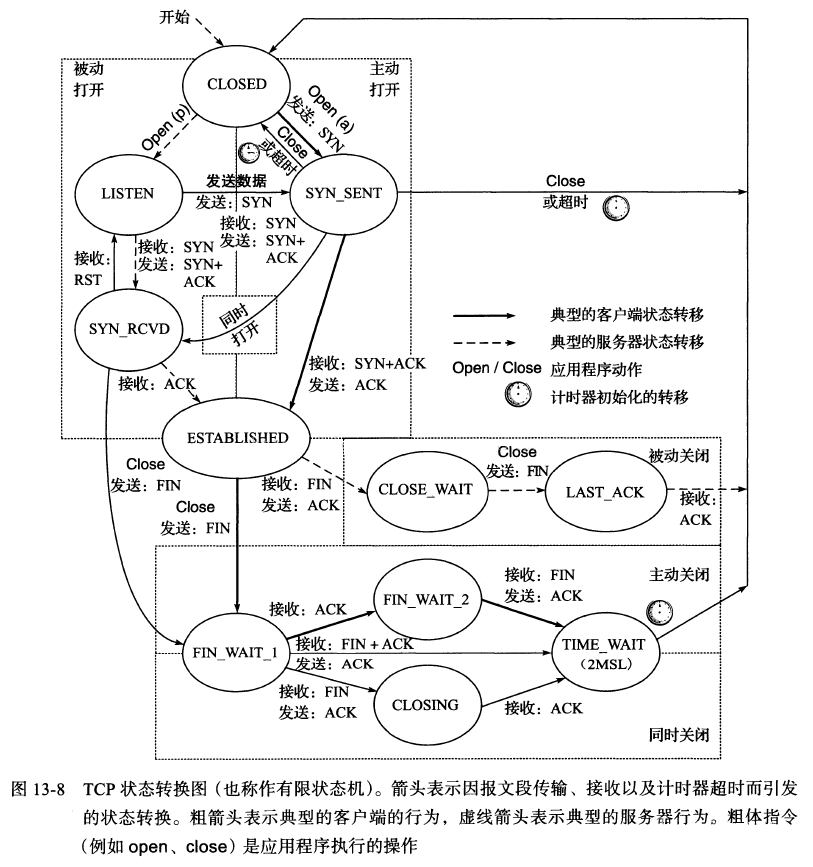
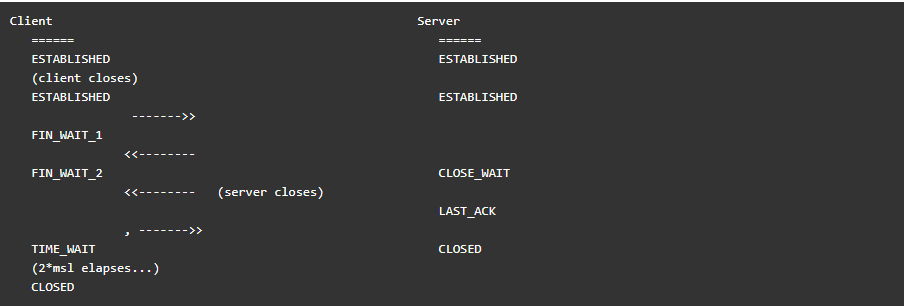
在构建TCP客户端服务器系统时,一些看似简单的错误可能会严重影响系统的可伸缩性。其中,对状态考虑不足是一个常见问题。特别是TIME_WAIT状态,它经常被误解,但它在TCP状态转换图中扮演着重要角色。套接字进入TIME_WAIT状态后,会保持一段时间,如果系统中存在大量处于该状态的套接字,那么创建新连接的能力就会受限,进而影响客户端服务器系统的扩展能力。
关于套接字为何以及如何进入TIME_WAIT状态,很多人存在误解,但实际上这一过程并不复杂。从TCP状态转换图中可以看出,TIME_WAIT通常是TCP客户端的最终状态。我们需要明确,这个过程并非神秘莫测,而是有其存在的合理性和必要性。
虽然状态转换图上标明TIME_WAIT为最终状态,但这并不意味着只有客户端会进入TIME_WAIT。实际上,任何执行“主动关闭”操作的对等端,无论是客户端还是服务器,都可能达到这个最终状态。所谓“主动关闭”,指的是在TCP连接中,首先调用Close()来结束连接的一方。
在许多协议和客户端/服务器交互模式中,通常是客户端发起主动关闭。然而,在HTTP和FTP等协议的服务器端,往往是服务器来执行这一操作。因此,触发对等端进入TIME_WAIT状态的具体事件序列可以是多样的,既可能是客户端,也可能是服务器。
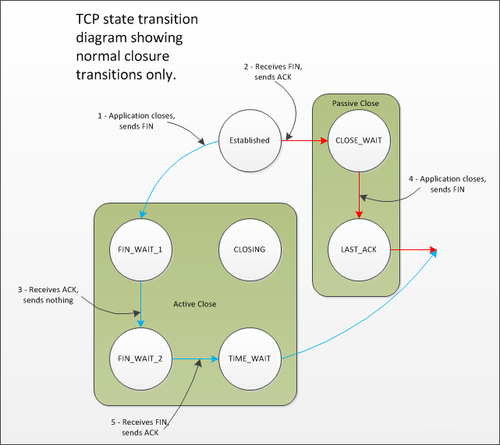
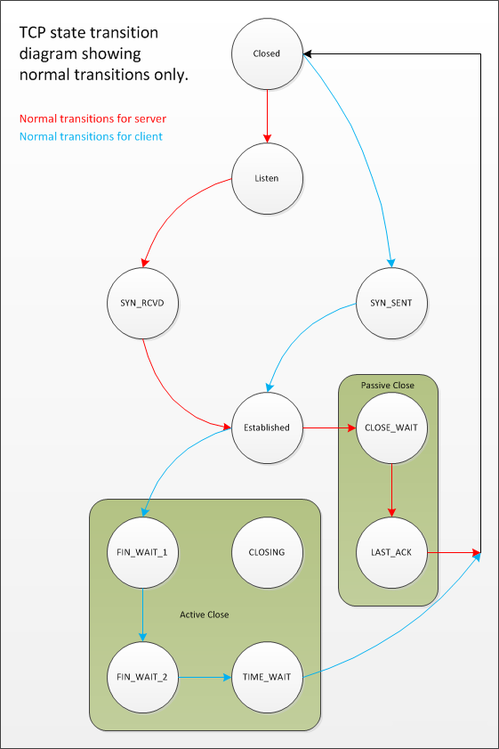
状态转换图上虽然将TIME_WAIT标识为客户端的最终状态,但这并不意味着只有客户端会进入这一状态。实际上,任何发起“主动关闭”的对等端,无论是客户端还是服务器,都可能最终进入TIME_WAIT状态。那么,何谓“主动关闭”呢?
当TCP对等方首先调用Close()来关闭连接时,它就被认为是发起了“主动关闭”。在多数协议和客户端/服务器模型中,通常是客户端执行这一操作。然而,在HTTP和FTP等协议的服务端,往往是服务器来执行主动关闭。了解套接字如何进入TIME_WAIT状态后,我们再来探讨这个状态存在的原因及其可能带来的问题。
TIME_WAIT常被称作2MSL等待状态,这是因为套接字在这个状态下的持续时间是最大段寿命(MSL)的两倍。MSL指的是一个TCP段在网络中保持有效状态的最大时间,这个时间限制通常由IP数据报中的TTL字段决定。
不同的TCP实现会选择不同的MSL值,常见的设定为30秒、1分钟或2分钟。根据RFC 793的规定,MSL的默认值为2分钟,Windows系统默认采用这个值,但可以通过修改TcpTimedWaitDelay注册表设置来调整。
TIME_WAIT可能会影响系统的可伸缩性,因为一个完全关闭的TCP套接字将保持在TIME_WAIT状态大约4分钟。如果连接频繁地打开和关闭,系统中TIME_WAIT状态的套接字数量可能会不断累积;您可以通过netstat命令来查看这些套接字。由于本地端口的数量有限,这会限制可以建立的套接字连接数量。
如果过多的套接字处于TIME_WAIT状态,您可能会发现难以建立新的出站连接,因为缺少可用的本地端口。那么,为什么需要TIME_WAIT状态呢?存在两个主要原因。
首先,TIME_WAIT用于防止一个连接的延迟段被错误地认为是后续连接的一部分。在连接处于2MSL等待状态期间,任何到达的段都会被丢弃。
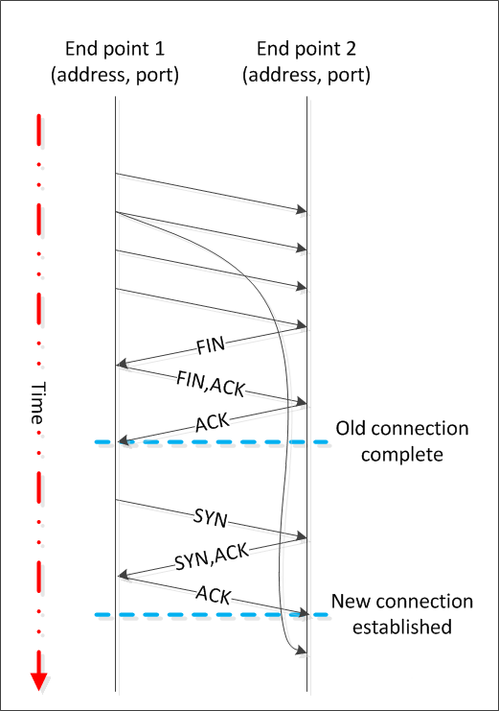
在讨论TCP连接的终止时,我们注意到TIME_WAIT状态对于防止数据混淆至关重要。在上图中,我们看到了两个从端点1到端点2的连接,它们的地址和端口在每次连接中都是相同的。第一个连接是由端点2发起的主动关闭来终止的。如果端点2没有维持足够的TIME_WAIT状态以确保所有来自前一个连接的延迟段已经过期,那么这些延迟段可能会被错误地认为是第二个连接的一部分。
虽然这种情况发生的可能性较低,但仍需注意。首先,两个端点的地址和端口必须相同,这在实际操作中并不常见,因为操作系统通常会为客户端分配一个临时端口,从而在连接间产生变化。其次,延迟段的序列号必须在新连接中有效,这也是不太可能的情况。然而,如果这两个条件同时满足,TIME_WAIT状态就能防止新连接的数据被破坏。
TIME_WAIT存在的第二个原因是确保TCP连接能够可靠地实现全双工终止。如果从端点2发出的ACK被丢弃,端点1将重新发送FIN。如果此时端点2已经进入CLOSED状态,它唯一能做的响应就是发送一个RST,因为重传的FIN会被视为意外的。这会导致端点1收到错误信号,即使所有数据都已正确传输。
不幸的是,一些操作系统在实现TIME_WAIT时过于简单化。它们只允许与处于TIME_WAIT状态的连接完全匹配的套接字建立连接。这意味着,只有当客户端地址、客户端端口、服务器地址和服务器端口完全相同时,TIME_WAIT才会阻止新的出站连接。某些操作系统甚至更加严格,阻止任何包含TIME_WAIT状态的本地端口号被重新使用。如果太多的套接字进入TIME_WAIT状态,新的出站连接可能无法建立,因为没有可用的本地端口。
Windows系统的处理方式更为灵活,只阻止与TIME_WAIT状态中的连接完全匹配的出站连接。入站连接受到的影响较小,因为服务器监听的众所周知端口不会因TIME_WAIT状态而阻止新的入站连接。
尽管服务器主动关闭的连接与客户端连接在TIME_WAIT状态上是一样的,但服务器监听的本地端口不会阻止它接受新的入站连接。在Windows上,只要新连接的序列号大于当前连接的最终序列号,服务器就可以接受新的入站连接,即使该本地端口当前正处于TIME_WAIT状态。
然而,服务器上累积的TIME_WAIT连接可能会影响性能和资源使用,因为直到TIME_WAIT状态结束,这些连接仍会占用服务器资源。
为了避免因本地端口号耗尽而影响出站连接的建立,您可以确保使用了足够的临时端口范围。在Windows上,这可以通过调整MaxUserPort注册表设置来实现。
缩短套接字在TIME_WAIT状态下的时间通常不是一个好主意,因为这可能会导致更多的问题。如果您的系统在短时间内建立和关闭大量连接,调整2MSL等待周期可能会导致更多的问题,而不是解决问题。
更改2MSL延迟通常是全局性的配置更改。使用SO_REUSEADDR套接字选项可以在套接字级别解决问题,但这可能会带来安全风险,如拒绝服务攻击或数据窃取。在Windows平台上,SO_EXCLUSIVEADDRUSE套接字选项可以帮助防止这些问题,但最佳的做法是设计系统以避免TIME_WAIT成为问题。
另一种终止TCP连接的方法是通过发送RST而不是FIN来中止连接,这通常通过将SO_LINGER套接字选项设置为0来实现。这种方法会丢弃挂起的数据,并且不会进入TIME_WAIT状态,但可能会导致数据丢失。
为了避免TIME_WAIT成为问题,您可以采取以下措施:
- 对于不建立出站连接的服务器,除了维护连接的性能和资源意义外,不必过分担心TIME_WAIT。
- 对于建立出站连接并接受入站连接的服务器,最佳做法是确保TIME_WAIT状态发生在客户端而不是服务器上。这可以通过永不从服务器发起主动关闭来实现,而是在出现错误时中止连接。
- 在客户端,虽然TIME_WAIT状态最终会在客户端结束,但这也是有优势的。如果客户端因TIME_WAIT积累而导致连接问题,其他客户端不会受到影响。此外,设计持久连接的协议比频繁打开和关闭连接更为高效。
总之,TIME_WAIT状态的存在有其重要原因,通过缩短2MSL周期或使用SO_REUSEADDR来解决TIME_WAIT问题并不总是最佳做法。如果您能够设计协议以避免TIME_WAIT问题,那么通常可以完全避免这个问题。
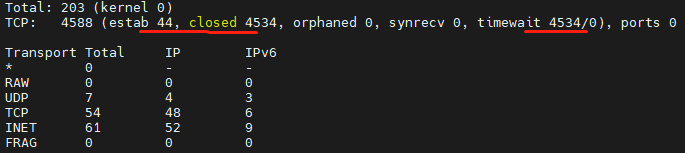
TIME_WAIT的4种查询方式
1、netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'

2、ss -s
3、netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
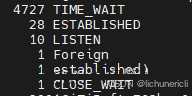
4、 统计 TIME_WAIT 连接的本地地址
netstat -an | grep TIME_WAIT | awk '{print $4}' | sort | uniq -c | sort -n -k1
尝试抓取 tcp 包
tcpdump tcp -i any -nn port 8080 | grep "172.11.11.11"
系统参数优化
处理方法:需要修改内核参数开启重启:
net.ipv4.tcp_tw_reuse = 1,开启快速回收
net.ipv4.tcp_tw_recycle = 1 (在NAT网络中不建议开启,要设置为0),并且开启net.ipv4.tcp_timestamps = 1以上两个参数才生产。
具体操作方法如下:
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf;
echo "net.ipv4.tcp_tw_recycle = 1" >> /etc/sysctl.conf;
echo "net.ipv4.tcp_timestamps = 1" >> /etc/sysctl.conf;
sysctl -p;
nginx 配置优化
当使用nginx作为反向代理时,为了支持长连接,需要做到两点:
-
从client到nginx的连接是长连接
-
从nginx到server的连接是长连接
保持和client的长连接:
http {
keepalive_timeout 120s 120s;
keepalive_requests 1000;
}
keepalive_timeout设置
语法
keepalive_timeout timeout [header_timeout];
第一个参数:设置keep-alive客户端(浏览器)连接在服务器端(nginx端)保持开启的超时值(默认75s);值为0会禁用keep-alive客户端连接;
第二个参数:可选、在响应的header域中设置一个值“Keep-Alive: timeout=time”;通常可以不用设置;
这个keepalive_timeout针对的是浏览器和nginx建立的一个tcp通道,没有数据传输时最长等待该时候后就关闭.
nginx和upstream中的keepalive_timeout则受到tomcat连接器的控制,tomcat中也有一个类似的keepalive_timeout参数
keepalive_requests理解设置
keepalive_requests指令用于设置一个keep-alive连接上可以服务的请求的最大数量,当最大请求数量达到时,连接被关闭。默认是100。
这个参数的真实含义,是指一个keep alive建立之后,nginx就会为这个连接设置一个计数器,记录这个keep alive的长连接上已经接收并处理的客户端请求的数量。如果达到这个参数设置的最大值时,则nginx会强行关闭这个长连接,逼迫客户端不得不重新建立新的长连接。
保持和server的长连接
为了让nginx和后端server(nginx称为upstream)之间保持长连接,典型设置如下:(默认nginx访问后端都是用的短连接(HTTP1.0),一个请求来了,Nginx 新开一个端口和后端建立连接,后端执行完毕后主动关闭该链接)
location / {
proxy_http_version 1.1;
proxy_set_header Connection keep-alive;
proxy_pass http://httpurl;
}
HTTP协议中对长连接的支持是从1.1版本之后才有的,因此最好通过proxy_http_version指令设置为”1.1”;
从client过来的http header,因为即使是client和nginx之间是短连接,nginx和upstream之间也是可以开启长连接的。
keepalive理解设置
此处keepalive的含义不是开启、关闭长连接的开关;也不是用来设置超时的timeout;更不是设置长连接池最大连接数。官方解释:
-
The connections parameter sets the maximum number of idle keepalive connections to upstream servers connections(设置到upstream服务器的空闲keepalive连接的最大数量)
-
When this number is exceeded, the least recently used connections are closed. (当这个数量被突破时,最近使用最少的连接将被关闭)
-
It should be particularly noted that the keepalive directive does not limit the total number of connections to upstream servers that an nginx worker process can open.(特别提醒:keepalive指令不会限制一个nginx worker进程到upstream服务器连接的总数量)
总结:
在使用keepalive参数时,务必要谨慎配置,尤其是在处理高QPS的场景下。建议先进行一些基本的计算,根据QPS和平均响应时间,可以大致估算出所需的长连接数量。
例如,如果您的系统面临10000 QPS和100毫秒的平均响应时间,那么所需的长连接数量大约是1000个。在此基础上,可以将keepalive参数设置为长连接数量的10%到30%。如果您想要简化配置,可以直接将keepalive设置为1000左右,通常这样的设置是足够的。
以下是导致出现大量TIME_WAIT情况的原因分析:
-
在nginx端出现大量TIME_WAIT的情况主要有两种:
- 如果keepalive_requests设置得太小,在高并发情况下,一旦超过这个值,nginx就会强制关闭与客户端的keepalive长连接,这会导致nginx端出现TIME_WAIT状态。
- 如果keepalive设置得太小(即空闲连接数不足),在高并发环境下,nginx可能会频繁地关闭和重新打开与后端服务器保持的keepalive长连接,造成连接数的波动。
-
导致后端服务器端出现大量TIME_WAIT的情况:
- 如果nginx没有启用与后端服务器的长连接,即没有设置
proxy_http_version 1.1;和proxy_set_header Connection "";,这会导致后端服务器在每次关闭连接时都处于高并发状态,从而在后端服务器端产生大量的TIME_WAIT状态。
- 如果nginx没有启用与后端服务器的长连接,即没有设置

















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









