




 本文介绍了如何使用 ORPO(几率比优化)技术对 Llama 3 大型语言模型进行微调,该技术将指令微调和偏好校准结合,减少了训练时间和资源。通过 ORPO,模型可以同时学习任务和人类偏好,提高了性能。文章展示了微调过程和初步的积极结果。
本文介绍了如何使用 ORPO(几率比优化)技术对 Llama 3 大型语言模型进行微调,该技术将指令微调和偏好校准结合,减少了训练时间和资源。通过 ORPO,模型可以同时学习任务和人类偏好,提高了性能。文章展示了微调过程和初步的积极结果。
原文地址:https://towardsdatascience.com/fine-tune-llama-3-with-orpo-56cfab2f9ada
更便宜、更快的统一微调技术
2024 年 4 月 19 日
ORPO 是一种新的令人兴奋的微调技术,它将传统的监督微调和偏好校准阶段合并为一个过程。这减少了训练所需的计算资源和时间。此外,经验结果表明,在各种模型大小和基准上,ORPO 都优于其他配准方法。
在本文中,我们将使用 ORPO 和 TRL 库对新的 Llama 3 8B 模型进行微调。
ORPO
指令调整和偏好对齐是使大型语言模型(LLM)适应特定任务的基本技术。传统上,这涉及一个多阶段过程:1/ 对指令进行监督微调 (SFT),使模型适应目标领域;2/偏好调整方法,如人工反馈强化学习 (RLHF) 或直接偏好优化 (DPO),以提高生成首选响应而非拒绝响应的可能性。
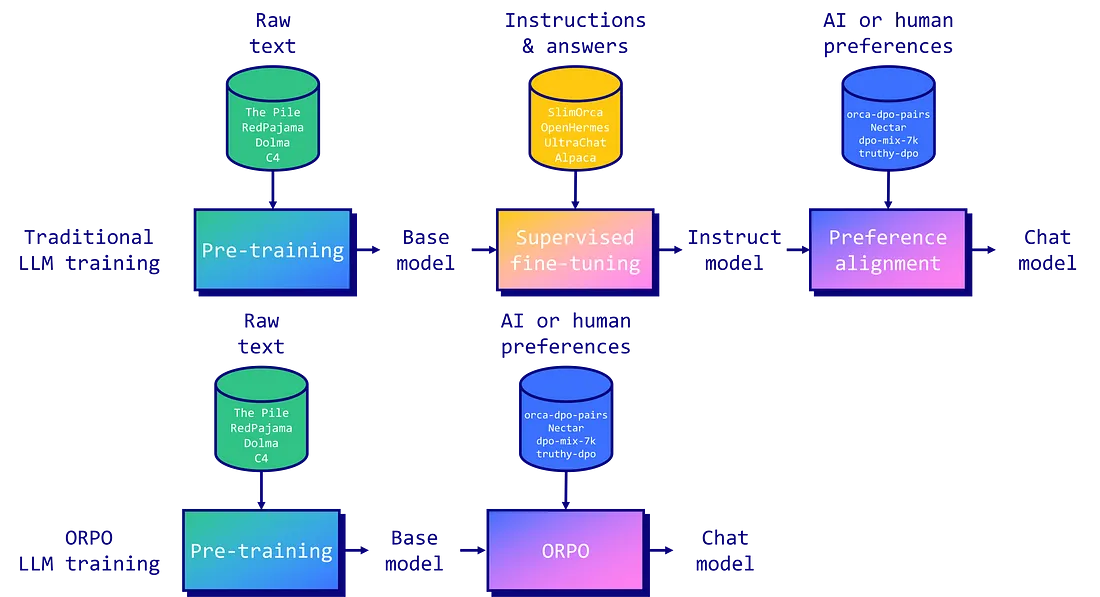
不过,研究人员也发现了这种方法的局限性。虽然 SFT 能有效地使模型适应所需的领域,但却无意中增加了在生成首选答案的同时生成不想要的答案的概率。这就是为什么有必要进行偏好调整阶段,以拉大首选输出和拒绝输出的可能性之间的差距。
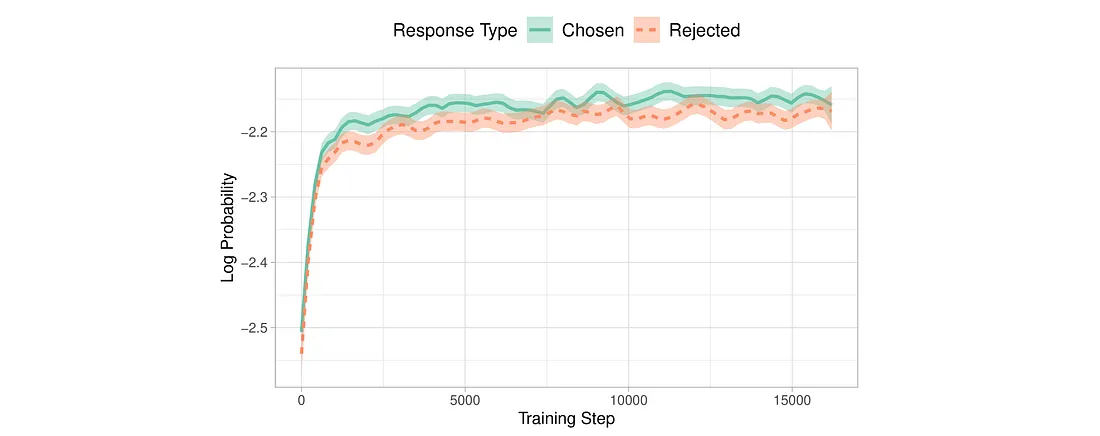
由 Hong 和 Lee(2024 年)提出的 ORPO 将指令调整和偏好调整结合到一个单一的、整体的训练过程中,为这一问题提供了一个优雅的解决方案。ORPO 修改了标准语言建模目标,将负对数似然损失与几率比(OR)项相结合。这种赔率损失会对被拒绝的反应进行弱惩罚,同时对偏好的反应进行强奖励,从而使模型能够同时学习目标任务并与人类偏好保持一致。
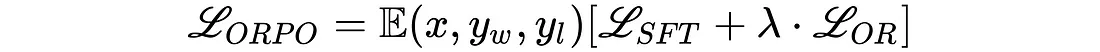
使用 ORPO 微调 Llama 3
Llama 3 是 Meta 开发的最新 LLM 系列。这些模型是在一个包含 15 万亿个词库(相比之下,Llama 2 包含 2T 个词库)的广泛数据集上训练的。目前已发布两种规
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1562
1562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









