






一、效果
要解决的问题:根据后台错误日志,分析潜在错误及推荐的解决方案。
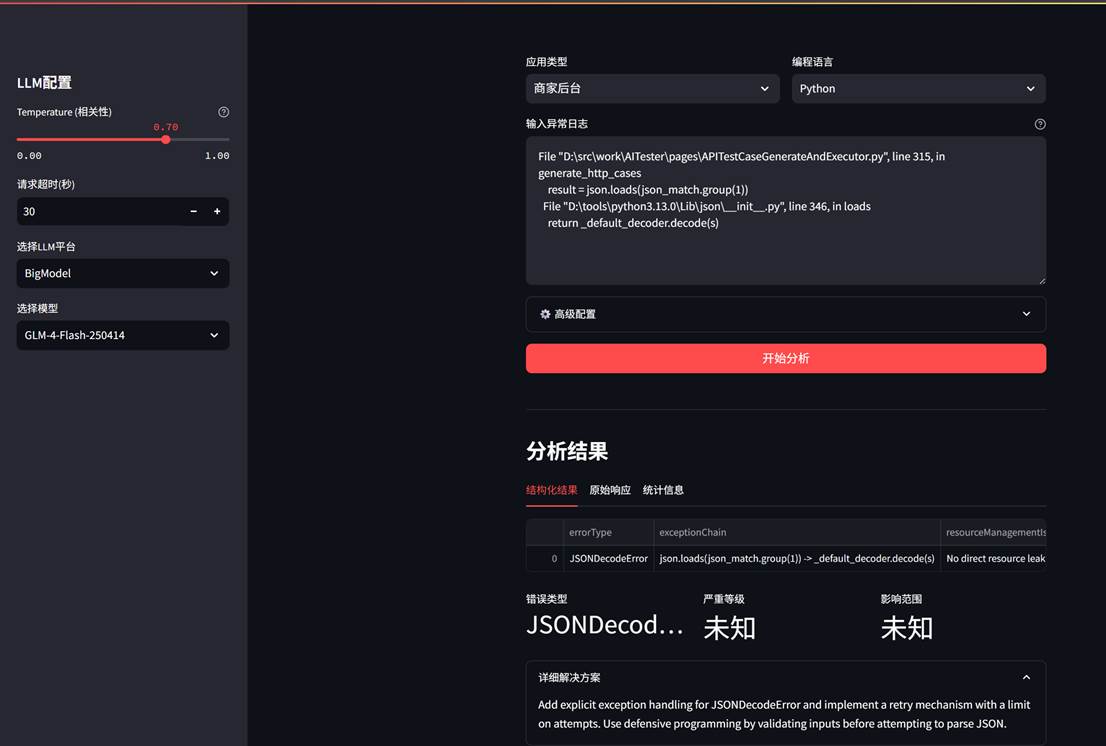
左侧选择LLM及模型;
右侧主页面选择编程语言(java/python…)、输入错误日志,可以调整默认提示词,点击分析可获取结构化的分析结果,以及修复建议。
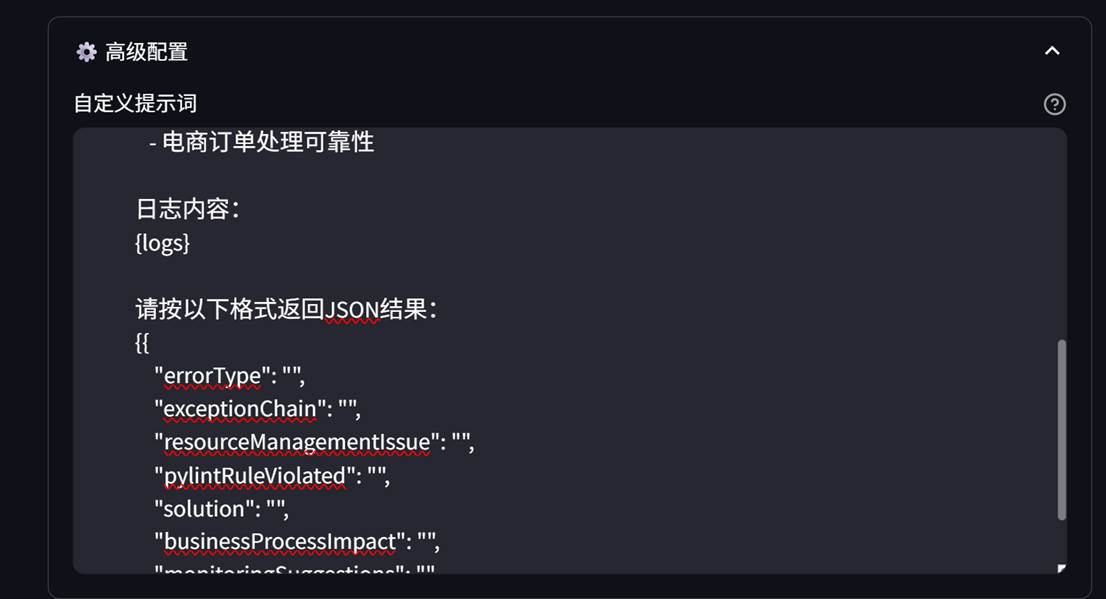
默认的提示词可以修改:
二、关键要点分析
2.1、提示词:
templates = {
"Java": """
作为资深Java工程师,请分析以下电商系统异常日志,结合SonarQube规则、FindBugs模式和常见电商业务场景:
1. 首先识别异常类型和严重等级
2. 分析堆栈跟踪,定位问题代码位置
3. 检查是否违反以下常见问题:
- 并发问题(竞态条件、死锁)
- 事务管理不当
- 缓存穿透/雪崩
- 数据库连接泄漏
- 空指针异常
- 集合越界
4. 提供修复方案,考虑:
- 防御性编程
- 重试机制
- 熔断降级
- 性能优化
5. 针对电商场景的特殊建议
日志内容:
{logs}
请按以下格式返回JSON结果:
{{
"errorType": "",
"severity": "",
"rootCause": "",
"codeLocation": "",
"sonarRuleViolated": "",
"solution": "",
"ecommerceImpact": "",
"preventionTips": ""
}}
"""
}
2.2 日志分析过程
Stream模式分析日志。
def analyze_logs(
self,
provider: str,
model: str,
prompt: str,
temperature: float = 0.7,
timeout: int = 30
) -> Tuple[Optional[str], Optional[Dict]]:
"""阻塞方式调用LLM分析日志"""
try:
if provider not in self.providers:
raise ValueError(f"不支持的提供者: {provider}")
config = self.providers[provider]
client = openai.OpenAI(
api_key=config["api_key"],
base_url=config["base_url"],
timeout=timeout
)
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
max_tokens=config["max_tokens"],
stream=False
)
elapsed = time.time() - start_time
content = response.choices[0].message.content
logger.info(
f"LLM请求成功 | 平台: {provider} | 模型: {model} | "
f"耗时: {elapsed:.2f}s | 使用token: {response.usage.total_tokens}"
)
return content, {
"provider": provider,
"model": model,
"usage": {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
},
"timing": {
"response_time": elapsed
}
}
except Exception as e:
logger.error(f"LLM请求失败: {str(e)}", exc_info=True)
return None, {"error": str(e)}
2.3 更多
https://t.zsxq.com/kLBNP 获取源代码。加v: liangjianzhao2020加入高质量测试效能群


















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









