






1、搭建演练环境
postgresql及wal2json插件安装:https://blog.youkuaiyun.com/li281037846/article/details/128411222
kafka及kafka-connect安装,略
//添加debezium connector
curl -i -X POST -H "Content-Type:application/json" -H "Accepted:application/json" http://172.19.102.150:8083/connectors -d '{"name":"debezium-pg-connector","config":{"connector.class":"io.debezium.connector.postgresql.PostgresConnector","database.hostname":"172.19.103.5","database.port":"5432","database.user":"dev","database.password":"123456","database.dbname":"postgres","database.server.name":"debezium-pg-test","table.include.list":"public.table1_with_pk","slot.name":"debezium_pg_test","plugin.name":"wal2json","value.converter": "org.apache.kafka.connect.json.JsonConverter","value.converter.schemas.enable":"false","tombstones.on.delete": "true"}}'
//查看connector
curl 172.19.102.150:8083/connectors/debezium-pg-connector/status
//重启connnector
curl -i -X POST http://172.19.102.150:8083/connectors/debezium-pg-connector/restart?includeTasks=true&onlyFailed=true
//消费topic
bin/kafka-console-consumer.sh --bootstrap-server 172.19.102.150:9092 --topic debezium-pg-test.public.table1_with_pk --group group-tianzy-test
debezium connector会监听table1_with_pk表的wal日志,发到kafka
flink程序:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tianzy.flink.test</groupId>
<artifactId>flink-test</artifactId>
<version>0.1</version>
<packaging>jar</packaging>
<name>Flink Walkthrough DataStream Java</name>
<url>https://flink.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.14.4</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>central</id>
<url>https://maven.aliyun.com/repository/central</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.3.4</version>
</dependency>
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${target.java.version}</source>
<target>${target.java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.tianzy.test.DebeziumTaskSync</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
public class DebeziumTaskSync {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE topic_table1_with_pk (\n" +
" -- schema 与 MySQL 的 products 表完全相同\n" +
" a int NOT NULL,\n" +
" b STRING,\n" +
" c timestamp(6) NOT NULL\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'debezium-pg-test.public.table1_with_pk',\n" +
" 'properties.bootstrap.servers' = '172.19.102.150:9092',\n" +
" 'properties.group.id' = 'group-tianzy-test',\n" +
" -- 使用 'debezium-json' format 来解析 Debezium 的 JSON 消息\n" +
" -- 如果 Debezium 用 Avro 编码消息,请使用 'debezium-avro-confluent'\n" +
" 'format' = 'debezium-json', -- 如果 Debezium 用 Avro 编码消息,请使用 'debezium-avro-confluent'\n" +
" 'debezium-json.schema-include' = 'true'\n" +
")");
tEnv.executeSql("CREATE TABLE sync_table1_with_pk (\n" +
" a int NOT NULL,\n" +
" b STRING,\n" +
" c timestamp(6) NOT NULL,\n" +
" PRIMARY KEY (a, c) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:postgresql://172.19.103.5:5432/postgres',\n" +
" 'table-name' = 'sync_table1_with_pk2',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx'\n" +
")");
Table transactions = tEnv.from("topic_table1_with_pk");
transactions.executeInsert("sync_table1_with_pk");
}
}
启动flink程序,会消费debezium发到kafka的消息,并将数据同步到sync_table1_with_pk2表
2、故障演练
正常情况,增删改source表数据,sink表数据会实时同步数据
1.部署单台kafka-connect,直接kill进程
此时修改pg表source表数据,sink表不会正常同步数据,kafka对应topic也不会产生消息
重新启动kafka-conenct进程,connector task也会自动启动继续开始工作。sink表会同步刚才所做的修改
2.通过rest接口暂停connector
暂停:curl -X PUT 172.19.102.150:8083/connectors/debezium-pg-connector/pause
此时修改pg表source表数据,sink表不会正常同步数据,kafka对应topic也不会产生消息
恢复:curl -X PUT 172.19.102.150:8083/connectors/debezium-pg-connector/resume
恢复后sink表立马同步数据
3.通过rest接口删除connector
删除:curl -X DELETE 172.19.102.150:8083/connectors/debezium-pg-connector
此时修改pg表source表数据,sink表不会正常同步数据,kafka对应topic也不会产生消息
重新添加:curl -i -X POST -H “Content-Type:application/json” -H “Accepted:application/json” http://172.19.102.150:8083/connectors -d ‘{“name”:“debezium-pg-connector”,“config”:{“connector.class”:“io.debezium.connector.postgresql.PostgresConnector”,“database.hostname”:“172.19.103.5”,“database.port”:“5432”,“database.user”:“dev”,“database.password”:“123456”,“database.dbname”:“postgres”,“database.server.name”:“debezium-pg-test”,“table.include.list”:“public.table1_with_pk”,“slot.name”:“debezium_pg_test”,“plugin.name”:“wal2json”,“value.converter”: “org.apache.kafka.connect.json.JsonConverter”,“value.converter.schemas.enable”:“false”,“tombstones.on.delete”: “true”}}’
重新添加后sink表立马同步数据
4.部署多台kafka-connect,kill其中一个
在172.19.103.5上部署多一个kafka-conenct(直接从172.19.102.150复制kafka目录,然后执行kafka-connect启动脚本即可)
查看connector状态:curl 172.19.103.5:8083/connectors/debezium-pg-connector/status

可以看到此时task运行在172.19.102.150上
kill 172.19.102.150这台机器的kafka-connect进程
再查看connector状态:

可以看到任务自动转移到了172.19.103.5这台机器
修改pg表source表数据,sink表立马同步数据
3、结论
kafkfa-connect进程被kill,或者debezium connector task终止再恢复,并不会影响debezium数据同步的最终一致性
如果部署了多台kafka-conenct,debezium任务会自动故障转移,其中一台挂掉,不会影响服务的可用性
4、问题记录&注意事项
1、kafka消息不要开启scheme
connector 配置:
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
flink kafka ddl配置:
'debezium-json.schema-include' = 'false'
开启scheme,除了消息中会有大量的冗余数据
还会导致flink无法识别kafka墓碑消息(不开启schema,墓碑消息为null;开启后为{“schema”:null,“payload”:null}),导致空指针异常
2、debezium发到kafka的消息中,before中的字段值为null问题
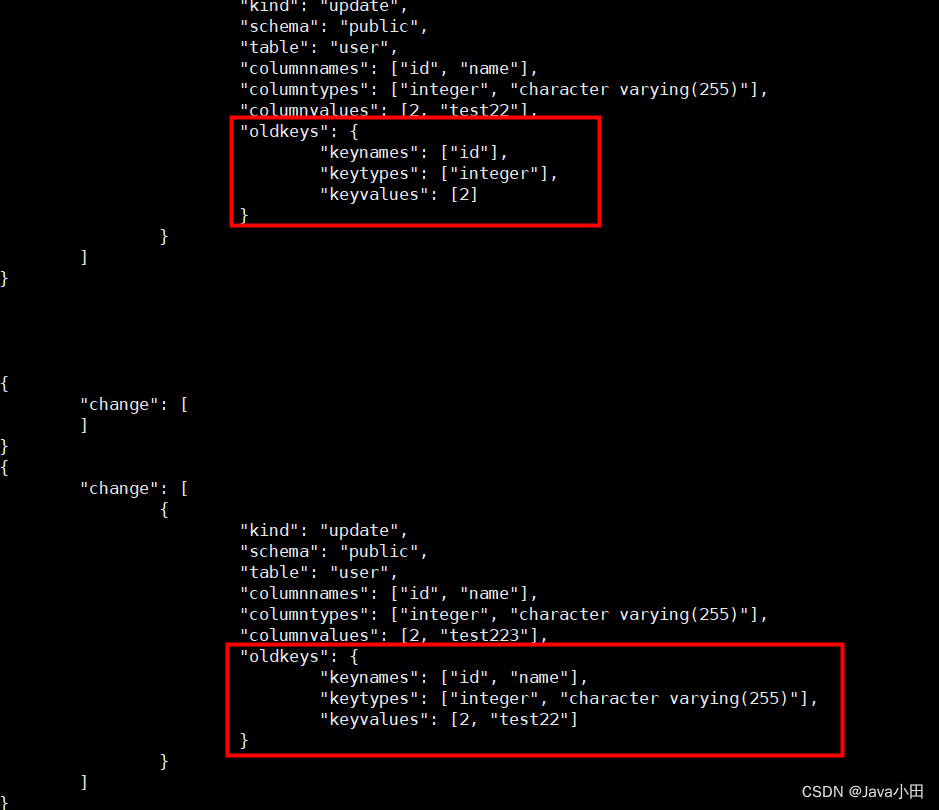
pg执行ALTER TABLE “public”.“table1_with_pk” REPLICA IDENTITY FULL;

默认情况下, REPLICA IDENTITY 为DEFAULT,修改前的值只有主键,没有其他字段
如下图,可以通过对比REPLICA IDENTITY为DEFAULT和FULL的情况,上面的oldKeys只有id,下面的oldKeys除了id还有name
flink ddl中设置’debezium-json.ignore-parse-errors’='true’表面可以解决报错问题,但是其实只是掩盖问题,不推荐这样做

















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









