






#AI相亲分析#
2025年,我国单身男女总人数已突破2.4亿,在所有单身男女中,通过相亲结识并步入婚姻的人群比例约占30%,而通过自由恋爱进入婚姻的比例则达到50%,剩余的20%则选择保持单身或暂时不考虑婚姻。

另外有数据显示:2025年已有超过40%的相亲用户使用了类似DeepSeek的人工智能工具,其中,使用这些工具成功脱单的比例高达65%,显著高于传统相亲方式的成功率(约为35%)。

接下来,我将使用实际例子,通过人工智能机器学习算法,模拟AI是如何预测相亲成功率的。
一:采集数据
首先,我们需要准备一份相亲成功率的数据,类似deepseek这样的大模型也是根据网上的数据进行总结之后,才能得出预测结果。
下面我将30年来我的相亲记录给大家奉献出来。数据如下:
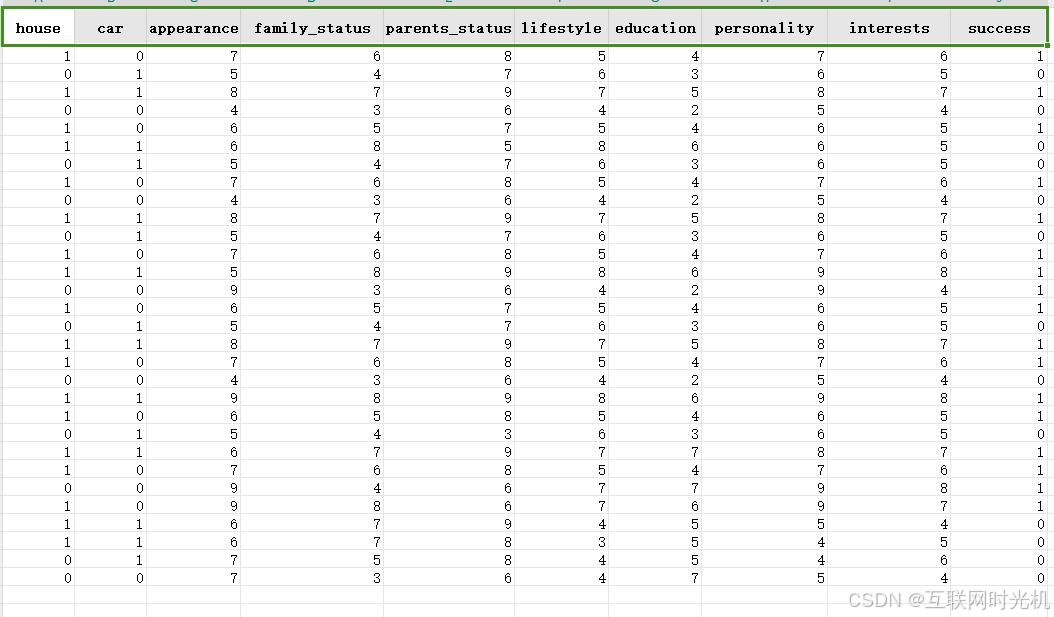
这张图片的主要要素有:
('house', '是否有房(0/1)'),
('car', '是否有车(0/1)'),
('appearance', '长相(1-10)'),
('family_status', '家庭情况(1-10)'),
('parents_status', '父母情况(1-10)'),
('lifestyle', '生活习惯(1-10)'),
('education', '教育程度(1-6)'),
('personality', '性格(1-10)'),
('interests', '兴趣(1-10)')
最终得到的结果是成功为1,失败为0.
举个例子,我相亲的第一次数据,大家看第一行。
房子:有
车子:无
长相:7分
家庭条件:6分
父母健康状态:8分
生活习惯:5分
教育程度:大学
性格:7分
兴趣爱好:6分
是否成功:成功
OK,数据准备完毕,这份数据比较完整,可以直接进行训练。
二,建立模型
接下来就需要选择模型和算法了。我问deepseek,他说根据这份数据的特点,使用随机森林比较合适。
开始写代码:
首先是加载数据:
# 读取数据
data = pd.read_csv('data.csv')
# print(data)
# 数据预处理
data.fillna(data.mean(),inplace=True)
第二步:划分训练集
# 划分训练数据和测试数据
x = data.drop('success',axis=1)
y = data['success']
# 开始划分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)
第三步:选择合适的模型进行训练
# 使用随机森林训练
rf = RandomForestClassifier(n_estimators=100,random_state=42)
rf.fit(x_train,y_train)
第四步:测试结果集
# 使用测试数据进行预测
y_pred = rf.predict(x_test)
# 将预测的数据进行对比,得到准确率
y_res = accuracy_score(y_test,y_pred)
print('准确率为:',y_res)
y_rep = classification_report(y_test,y_pred)
print('详细报告\n',y_rep)
第五步:使用自身的结果进行预测:
# 使用自身实际数据进行预测
my_data = pd.DataFrame({
'house':[0], # 是否有房0无,1有
'car':[0], # 是否有车0无,1有
'appearance':[8], # 颜值,1-10分
'family_status':[2], # 家庭情况1-10分
'parents_status':[2], # 父母情况1-10分
'lifestyle':[2], # 生活习惯1-10分
'education':[4], # 教育情况1-6 ,1 小学 6 博士
'personality':[6] , # 性格 1-10
'interests':[2] # 兴趣 1-10
})
print('=====================预测结果=========================')
# 预测结果
result = rf.predict(my_data)
if result[0]==1:
print('恭喜,牵手成功')
else:
print('下次再遇见更好的')
经过训练和测试,模型基本正确
通过对以上数据的分析,我发现性格的权重非常大,只要性格为8分,车和房子都可以不需要也可以相亲成功,你觉得是不是这样呢?
三,制作相亲预测界面
接下来,考虑使用qt5制作一个相亲预测的界面,方便不熟悉写代码的朋友进行预测。
最终代码如下:
import sys
from PySide6.QtCore import QSize
from PySide6.QtWidgets import (QApplication, QWidget, QLabel, QLineEdit, QPushButton, QGridLayout, QMessageBox)
import pandas as pd
from PySide6.QtGui import QMovie
from sklearn.ensemble import RandomForestClassifier # 假设你使用的是随机森林模型
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class PredictionUI(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
# 创建网格布局
grid = QGridLayout()
self.setLayout(grid)
# 创建标签和输入框
self.inputs = {}
features = [
('house', '是否有房(0/1)'),
('car', '是否有车(0/1)'),
('appearance', '长相(1-10)'),
('family_status', '家庭情况(1-10)'),
('parents_status', '父母情况(1-10)'),
('lifestyle', '生活习惯(1-10)'),
('education', '教育程度(1-6)'),
('personality', '性格(1-10)'),
('interests', '兴趣(1-10)')
]
# 添加标签和输入框到网格布局
for i, (key, label_text) in enumerate(features):
label = QLabel(label_text)
input_field = QLineEdit()
self.inputs[key] = input_field
grid.addWidget(label, i, 0)
grid.addWidget(input_field, i, 1)
# 添加预测按钮
predict_btn = QPushButton('进行预测', self)
predict_btn.clicked.connect(self.predict)
grid.addWidget(predict_btn, len(features), 0, 1, 2)
# 添加结果标签
self.result_label = QLabel('')
grid.addWidget(self.result_label, len(features) + 1, 0, 1, 2)
# 设置窗口
self.setGeometry(300, 300, 400, 700)
self.setWindowTitle('婚恋匹配预测系统')
self.show()
def predict(self):
try:
# 创建特征名称的中文对照表
feature_names = {
'house': '是否有房',
'car': '是否有车',
'appearance': '长相',
'family_status': '家庭情况',
'parents_status': '父母情况',
'lifestyle': '生活习惯',
'education': '教育程度',
'personality': '性格',
'interests': '兴趣'
}
for feature, input_field in self.inputs.items():
value = input_field.text().strip()
if not value:
QMessageBox.warning(self, '警告', f'{feature_names[feature]} 不能为空!')
return
try:
float(value)
except ValueError:
QMessageBox.warning(self, '警告', f'{feature_names[feature]} 必须是数字!')
return
QMessageBox.information(self, '提示', '开始预测')
# 获取输入值
input_data = {}
for key, input_field in self.inputs.items():
value = float(input_field.text())
input_data[key] = [value] # 创建单值列表
# 创建DataFrame
df = pd.DataFrame(input_data)
# 调用训练好的模型
pre= xiangqinPredict(df)
if pre:
prediction = "匹配成功"
movie = QMovie("./img/heart.gif") # 确保gif文件在正确的路径下
else:
prediction = "匹配失败"
movie = QMovie("./img/fail.gif") # 确保gif文件在正确的路径下
print(prediction)
# 显示结果
# self.result_label.setText(f'预测结果: {prediction}')
# 设置gif大小(可选)
movie.setScaledSize(QSize(400, 400)) # 设置gif显示大小为100x100像素
# 在标签中显示gif
self.result_label.setMovie(movie)
movie.start() # 开始播放gif
except ValueError:
QMessageBox.warning(self, '错误', '请确保所有输入都是有效的数字!')
except Exception as e:
QMessageBox.warning(self, '错误', f'发生错误: {str(e)}')
# 根据数据进行预测
def xiangqinPredict(data):
# 使用pd读取data.csv文件
df = pd.read_csv('data.csv')
# 填充缺失值,使用各列平均值填充空值
df.fillna(df.mean(), inplace=True)
# 删除数据集中的'success'列
x=df.drop('success', axis=1)
y=df['success']
# 将数据集分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
print(x_train)
# 创建一个随机森林分类器rf
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练
rf.fit(x_train, y_train)
# 使用训练好的模型对测试集(X_test)进行预测
x_pre = rf.predict(x_test)
print(x_pre)
accuracy_ = accuracy_score(y_test, x_pre)
print('准确度', accuracy_)
simple_pred = rf.predict(data)
if simple_pred[0] == 1:
return True
else:
return False
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = PredictionUI()
sys.exit(app.exec())
界面如下:
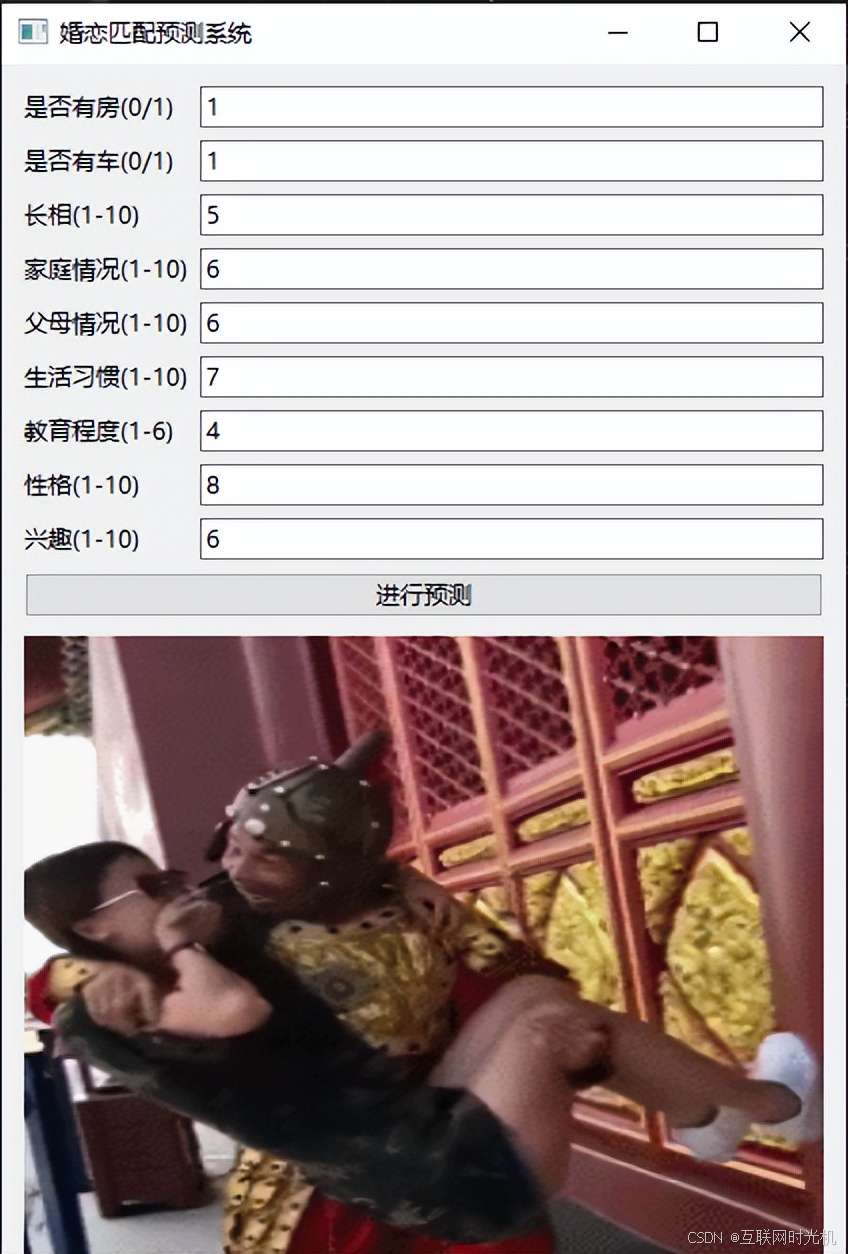
这是预测成功的界面。
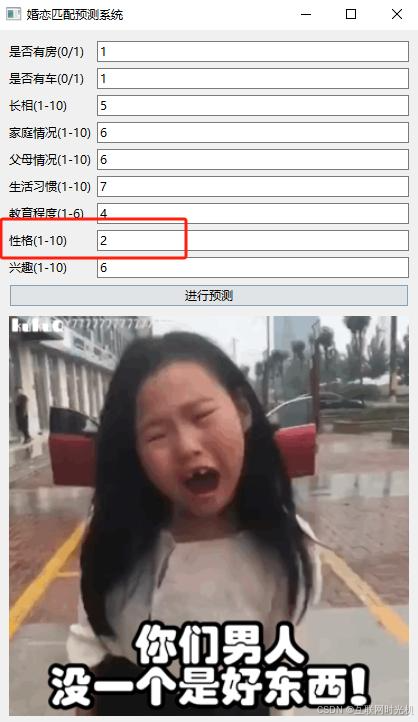
这是失败的界面,我只调整了性格,其他都没动。

四,总结
通过预测模型
反常识发现:
- 有房有车仅排第5位(12.1%)
- 兴趣匹配度重要性不足8%
- 个人性格占60%的比重,说明个人魅力太重要。
数据采集:
大模型可以采集很多人的数据,数据越真实,得到的结果越准确,以上是根据我的30次相亲经验进行训练,结果仅供参考。
以上,分享给需要的朋友!感谢支持!期待你的点赞关注。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











