






kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
-
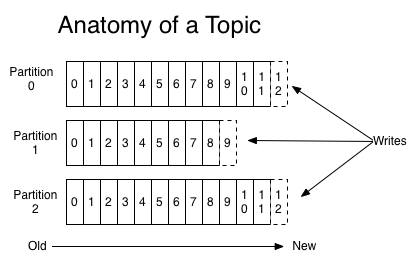
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
-
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
-
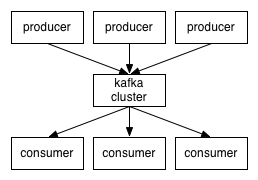
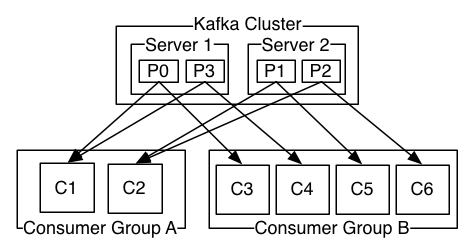
支持通过kafka服务器和消费机集群来分区消息。
-
支持Hadoop并行数据加载。
卡夫卡的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Git 地址:
http://git-wip-us.apache.org/repos/asf/kafka.git|
1
|

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









