




 本文详细介绍了Elasticsearch,一款基于Lucene的分布式全文搜索引擎,提供了实时搜索、高可用性和扩展性。涵盖基本概念如索引、文档和字段,以及倒排索引的工作原理。同时,介绍了Elasticsearch的安装、配置和Java API操作示例。
本文详细介绍了Elasticsearch,一款基于Lucene的分布式全文搜索引擎,提供了实时搜索、高可用性和扩展性。涵盖基本概念如索引、文档和字段,以及倒排索引的工作原理。同时,介绍了Elasticsearch的安装、配置和Java API操作示例。
Es 简介
Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜
索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款
下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,
稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困
难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜
索模式,我们希望能够简单地使用 JSON 通过 HTTP 来索引数据,我们希望我们的搜索服务
器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多
租户,我们希望建立一个云的解决方案。因此我们利用 Elasticsearch 来解决所有这些问题及
可能出现的更多其它问题
常用功能
- 全文搜索
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理 PB 级别的结构化或非结构化数据
基本概念
文件存储
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档,用 JSON 作为文档序列
化的格式,比如下面这条用户数据:
{
"productId": 131,
"salePrice": 1214.2,
"productName": "Apple iPhone XS",
"subTitle": "Apple iPhone XS [works exclusively with Simple Mobile]",
"productImageBig":
"http://172.16.23.195:7777/img/35eaf1865f214621ad84b2a627ab708e.jpg",
"categoryName": "Phone",
"cid": 1427
}
Elasticsearch 和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。
这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。
Elasticsearch 的交互,可以使用 Java API,也可以直接使用 HTTP 的 Restful API 方式,比如
我们打算插入一条记录,可以简单发送一个 HTTP 的请求:
PUT /item/itemList/131
{
"productId": 131,
"salePrice": 1214.2,
"productName": "Apple iPhone XS",
"subTitle": "Apple iPhone XS[works exclusively with Simple Mobile]",
"productImageBig":
"http://172.16.23.195:7777/img/35eaf1865f214621ad84b2a627ab708e.jpg",
"categoryName": "Phone",
"cid": 1427
}
索引
Elasticsearch 最关键的就是提供强大的索引能力了,为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往 Elasticsearch 里插入一条记录,其实就是直接 PUT 一个 json 的对象,这个对象有多个 fields,比如上面例子中的 productName, subTitle,那么在插入这些数据到Elasticsearch 的同时,Elasticsearch 还默默 131 的为这些字段建立索引–倒排索引,因为Elasticsearch 最核心功能是搜索。
关系型数据库索引:B-Tree 二叉树索引
效率是 logN,插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插
入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系
型数据库采用了 B-Tree/B+Tree 这样的数据结构
为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一
次寻道读取多个数据,同时也降低树的高度
Elasticsearch 使用倒排索引

每一个文档都对应一个 ID。倒排索引会按照指定语法对每一个文档进行分词,然后维护一
张表,列举所有文档中出现的 terms 以及它们出现的文档 ID 和出现频率。搜索时同样会对
关键词进行同样的分词分析,然后查表得到结果。
例如对于如下三个 document 中的 field
131
{
“productName”: “Apple iPhone X”
}
132
{
“productName”: “Oneplus 7”
}
133
{
“productName”: “Apple iPhone XS”
}
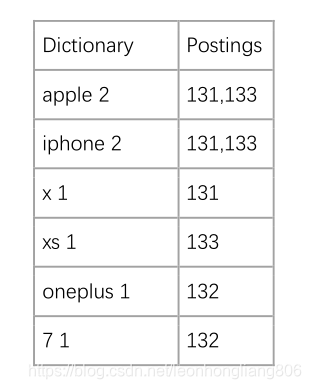
ES 对于 JSON 文档中的每一个 field 都会构建一个对应的倒排索引
节点( Node )
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同
cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。
ES 集群中的节点有三种不同的类型:
• 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除
节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性
node.master 进行设置。
• 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主
节点),可以通过 node.data 属性进行设置。
• 协调节点:如果 node.master 和 node.data 属性均为 false,则此节点称为协调节点,
用来响应客户请求,均衡每个节点的负载。
分片 ( Shard )
一个索引中的数据保存在多个分片中,相当于水平分表。一个分片就是一个完整的搜索引
擎。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交
互。
ES 实际上就是利用分片来实现分布式。分片是数据的容器,文档保存在分片内,分片又被
分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, ES 会自动的在各节点中
迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主
分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。 副
本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服
务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。默认情况下,
一个索引会有 5 个主分片,而其副本可以有任意数量。
主分片和副本分片的状态决定了集群的健康状态。每一个节点上都只会保存主分片或者其
对应的一个副本分片,相同的副本分片不会存在于同一个节点中。如果集群中只有一个节
点,则副本分片将不会被分配,此时集群健康状态为 yellow,存在丢失数据的风险。
安装(docker)
基于 dockers 的容器化搭建,前提主机安装 docker
搜索镜像
docker search elasticsearch
官方排名第一
下载镜像
docker pull elasticsearch
查看镜像
docker images
配置文件
宿主机新建一个 es 的配置文件 es.yml
单节点配置
#集群名
cluster.name: elasticsearch
#节点名
#node.name: node-111
#设置绑定的 ip 地址,可以是 ipv4 或 ipv6 的,默认为 0.0.0.0,
#指绑定这台机器的任何一个 ip
network.bind_host: 0.0.0.0
#设置其它节点和该节点交互的 ip 地址,如果不设置它会自动判断,
#值必须是个真实的 ip 地址
#network.publish_host: X.X.X.X
#设置对外服务的 http 端口,默认为 9200
http.port: 9200
#设置节点之间交互的 tcp 端口,默认是 9300
transport.tcp.port: 9300
#是否允许跨域 REST 请求
http.cors.enabled: true
#允许 REST 请求来自何处
http.cors.allow-origin: “*”
#节点角色设置
node.master: true
node.data: true
#有成为主节点资格的节点列表
#discovery.zen.ping.unicast.hosts: [“X.X.X.X:9300”]
#集群中一直正常运行的,有成为 master 节点资格的最少节点数(默认为 1)
#(totalnumber of master-eligible nodes / 2 + 1)
#discovery.zen.minimum_master_nodes: 1
宿主机环境配置
修改虚拟内存最大映射数,否则会有报错
ERROR:[1] bootstrap checks failed [1]: maxvirtual memory areas vm.max_map_count
[65530] istoo low, increase to at least [262144]
vi /etc/sysctl.conf
vm.max_map_count=655300
生效
sysctl -p
启动容器
docker run --name es -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms512m -
Xmx512m" -v /root/data/es.yml:/usr/share/elasticsearch/config/elasticsearch.yml -d
elasticsearch:latest
映射端口 9200 9300
测试
ip:9200
如下为启动成功
{
"name" : "sfYH3wF",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "zCIqps8rTbygbtdfdvgt8g",
"version" : {
"number" : "5.6.12",
"build_hash" : "cfe3d9f",
"build_date" : "2018-09-10T20:12:43.732Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
Es 插件
elasticsearch-head, 第三方插件,在浏览器中方便的查看 es 的信息
GitHub 地址 https://github.com/mobz/elasticsearch-head
下载后
npm install
npm run start 运行
注意:es的跨域访问需要设置为true
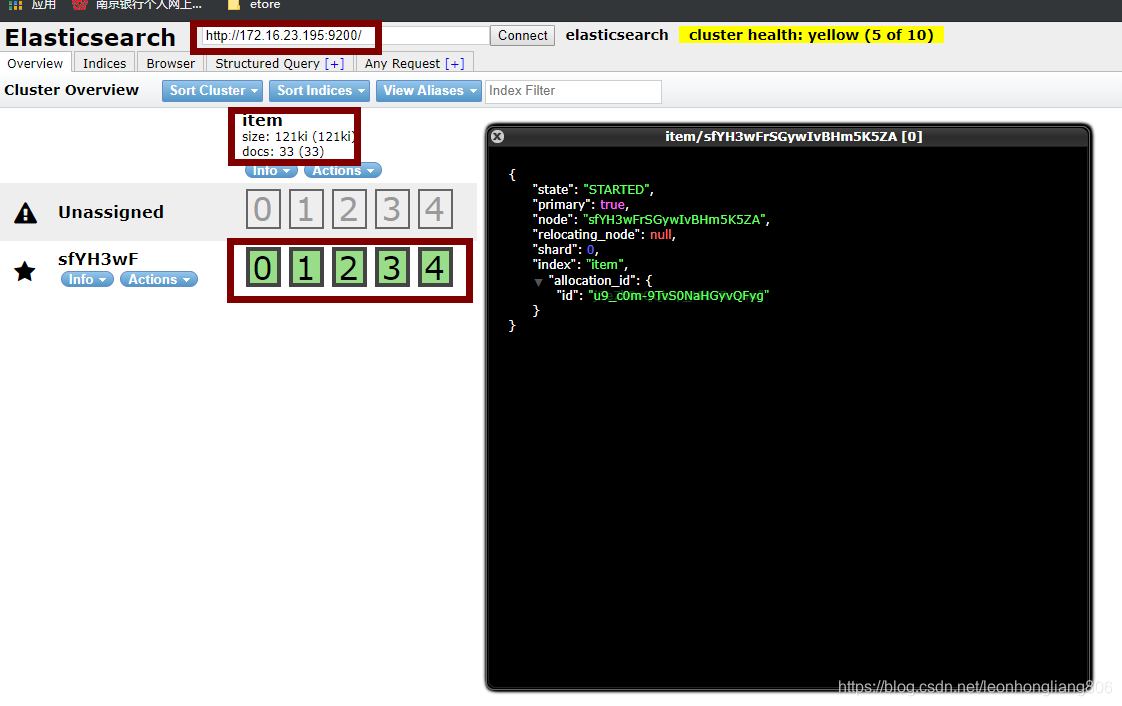
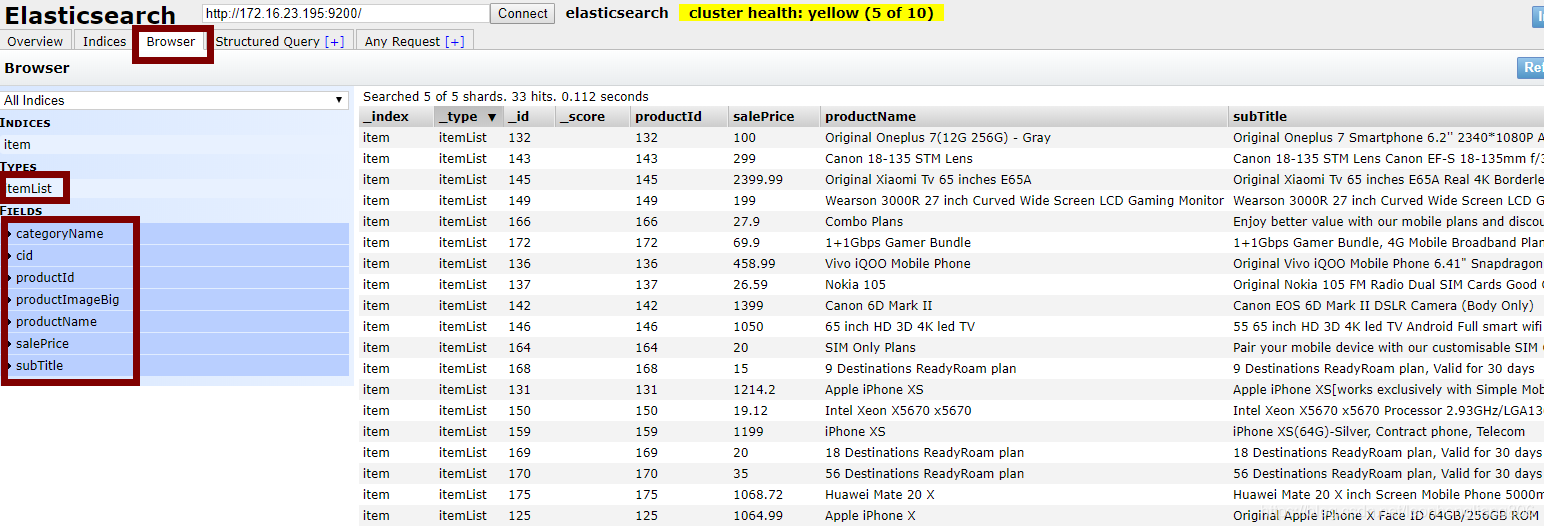
输入 ip:端口连接到 es 服务
可以看到主节点 sfYH3wF, 5 个分片,索引是 item,Types 是 itemList,右边是 documents 和 fields
JAVA API 操作
样例为 springboot 下整合 es,对某系统中商品信息的单个,批量新增,删除和快速查询的
操作
pom 依赖
<!-- Elasticsearch -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
</dependency>
application.yml 配置
#ES 连接 IP
ES_CONNECT_IP: 172.16.23.195
#节点客户端端口
ES_NODE_CLIENT_PORT: 9200
#ES 集群名
ES_CLUSTER_NAME: elasticsearch
#ES 商品索引(es 的索引和类型)
ITEM_INDEX: item
ITEM_TYPE: itemList
Java 代码
获取配置项
@Value("${ES_CONNECT_IP}")
private String ES_CONNECT_IP;
@Value("${ES_NODE_CLIENT_PORT}")
private String ES_NODE_CLIENT_PORT;
@Value("${ES_CLUSTER_NAME}")
private String ES_CLUSTER_NAME;
@Value("${ITEM_INDEX}")
private String ITEM_INDEX;
@Value("${ITEM_TYPE}")
private String ITEM_TYPE;
批量新增
Settings settings = Settings.builder().put("cluster.name", ES_CLUSTER_NAME).build();
TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new
TransportAddress(InetAddress.getByName(ES_CONNECT_IP), 9300));
//批量添加
BulkRequestBuilder bulkRequest = client.prepareBulk();
//查询商品列表
List<SearchItem> itemList = itemMapper.getItemList();
//遍历商品列表
for (SearchItem searchItem : itemList) {
String image=searchItem.getProductImageBig();
if (image != null && !"".equals(image)) {
String[] strings = image.split(",");
image=strings[0];
}else{
image="";
}
searchItem.setProductImageBig(image);
bulkRequest.add(client.prepareIndex(ITEM_INDEX, ITEM_TYPE,
String.valueOf(searchItem.getProductId())).setSource(jsonBuilder().startObject()
.field("productId", searchItem.getProductId())
.field("salePrice", searchItem.getSalePrice().doubleValue())
.field("productName", searchItem.getProductName())
.field("subTitle", searchItem.getSubTitle())
.field("productImageBig", searchItem.getProductImageBig())
.field("categoryName", searchItem.getCategoryName())
.field("cid", searchItem.getCid())
.endObject()
)
);
}
BulkResponse bulkResponse = bulkRequest.get();
log.info("更新索引成功");
client.close();
单个新增
IndexResponse indexResponse = client.prepareIndex(ITEM_INDEX, ITEM_TYPE,
String.valueOf(searchItem.getProductId())).setSource(jsonBuilder().startObject()
.field("productId", searchItem.getProductId())
.field("salePrice", searchItem.getSalePrice())
.field("productName", searchItem.getProductName())
.field("subTitle", searchItem.getSubTitle())
.field("productImageBig", searchItem.getProductImageBig())
.field("categoryName", searchItem.getCategoryName())
.field("cid", searchItem.getCid())
.endObject()
).get();
单个删除
DeleteResponse deleteResponse = client.prepareDelete(ITEM_INDEX, ITEM_TYPE,String.valueOf(itemId)).get();
查询
Restful api 快速查询
result = HttpUtil.sendGet("http://"+ES_CONNECT_IP+":"+ES_NODE_CLIENT_PORT+"/item/itemList/_search?q=productName:"+key);
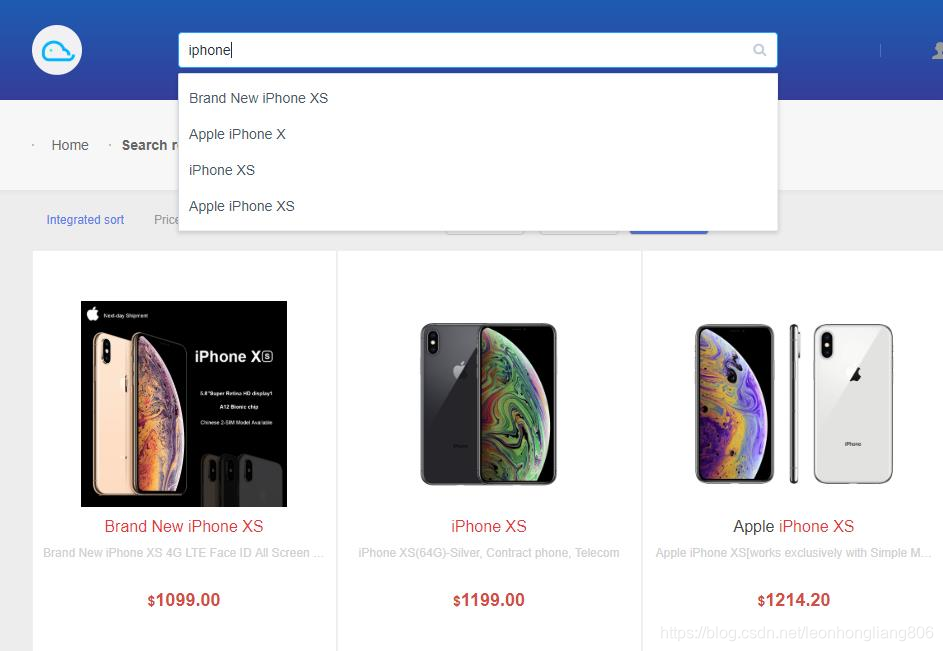
实现效果
界面输入 iphone,立即查询出词库里包含 iphone 的的 product name


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









