






 本文详细解析Linux内核中的device_add()函数,探讨设备如何加入设备驱动模型,包括设置设备名字、私有数据,以及与父设备的关系。通过代码分析,揭示内核设计的精妙之处。
本文详细解析Linux内核中的device_add()函数,探讨设备如何加入设备驱动模型,包括设置设备名字、私有数据,以及与父设备的关系。通过代码分析,揭示内核设计的精妙之处。
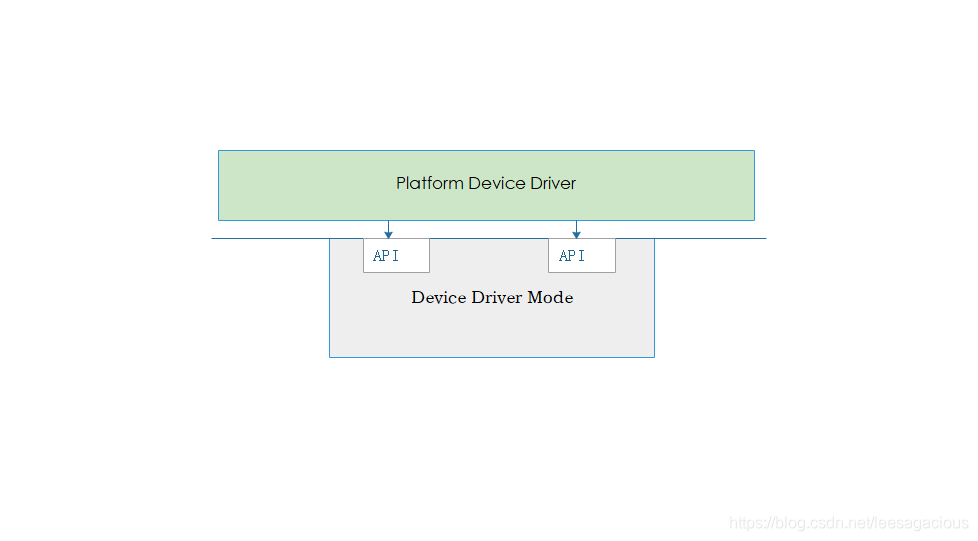
platform driver、device 对 device driver mode 封装的差强人意.
kernel 中几乎所有的platform driver 都不会在 /sys 下创建属性文件. 减少了与device 沟通的一种渠道, 内核黑客之所以这样架构是有深刻用意的,
设备驱动模型校验上层侵入的code是及其严格的, "免疫力"足够强大,看下面冰山一角.
看他们之间的交互通路
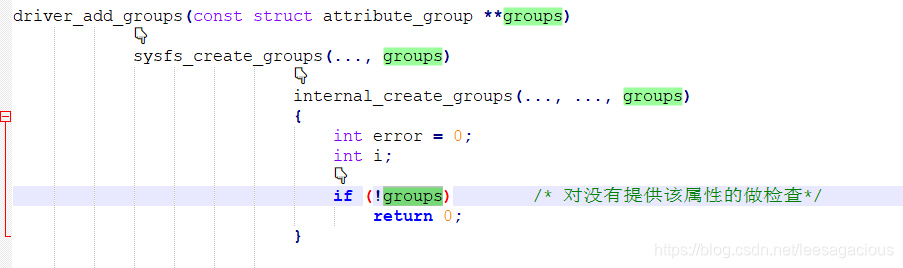
好,先看设备驱动模型暴露出来的第一个API, 先上一张图片,然后详细欣赏

/*
看参数,一个原生的struct device,
无论你是一个虚拟总线上挂载的设备还是物理总线上挂载的设备,
结构体中都必须包含该核心的struct device 结构体.
好,那么device driver mode 拿到了这个device
1: 做了哪些事情呢 ?
2: 又能做什么呢 ?
3: 为什么要做这些 ? 作者用意何在 ?
*/
int device_add(struct device *dev)
{
/*
该设备的父设备. 通常是该设备相连接的 Controller、BUS,
比如 i2c_adapter对应i2c controller,
ARM上 它挂载在 amba的apb总线上
那么,拿到该设备的parent 是想:
1 : 在该parent对应的sys目录下创建目录
2 : 挂接到该parent维护的klist_children 链表上去
3 : 父设备的运行时电源管理计数 + 1
好,既然是这样,那么如果该parent 为 NULL,会怎么办 ?
别急,哈哈,老鼠拉木箱,大的在后头...., 下面就有欣赏
*/
struct device *parent;
/*
嘿嘿🤭内核对象, 代表sys下的一个目录,真的很重要!
这个就不多说了,地球人都知道
正是由于该对象的存在,sys下才建立起层次关系, device driver mode中的核心所在!
*/
struct kobject *kobj;
/*
它提供了两个回调函数 add_dev 、remove_dev
提供这两个Callback 有什么作用呢? 没有硬性规定,看你的需求,
device driver mode 实现的灵活性可见一斑. 下面有个实验来验证这个特性.
再说一下这个class帮助你理解,class是班级的意思,好吧,按照作者的意思 该class下的
相同功能的设备就应该是班级里的学生了.
在device_add()函数的最后 会有下面的行为 :
遍历该 dev->class->p->interfaces 链表,具体该链表挂接的是什么、为什么要在最后来遍历
它 执行上述的Callback函数,下面再分析,这里仅仅只是声明一个指针. 暂不作深入讨论.
*/
struct class_interface *class_intf;
/*
返回值,
返回 0 表示该设备已经加入到 device driver mode中了.
结果比过程要重要,除非你是去旅游,
除非能有像弗莱明一样探索过程可以发现青霉素. 否则华而不实
*/
int error = -EINVAL;
/*
它的实现:
return dev->kobj.parent;
在正常的注册过程中该值是没有任何意义,其价值在于注册失败后该怎么做.
到时再分析吧,这里作者预先铺垫了注册失败后该怎么办.
*/
struct kobject *glue_dir = NULL;
/*
好了, 一个参数 、五个局部变量都定义好了,看下面code的执行逻辑了
材米油盐都给你准备好了,看你怎么做饭了,
*/
/*
增加设备的引用计数.
如果传入的参数是 NULL, 那么该函数返回 NULL
在该函数的最后 当该设备已经加入到 device driver mode 中了,还会将该设备的引用计数减1
调用了这个函数: put_device(dev);
看整个注册过程是在 该设备的引用计数 > 0 的情况下完成的.
难道设备的引用计数为 0 就不可以进行注册了吗 ? 好,下面详细说
对称性:
这里的对称性我想到了一个: try_to_wake_up() 去唤醒一个 Task的时候
是在 preempt_disable() 禁用内核抢占环境下执行的,完成后 preempt_enable()又开启抢占
这种对称性在 kernel中真是太多了....
*/
dev = get_device(dev);
if (!dev)
goto done;
/*
还是在校验传入的参数.
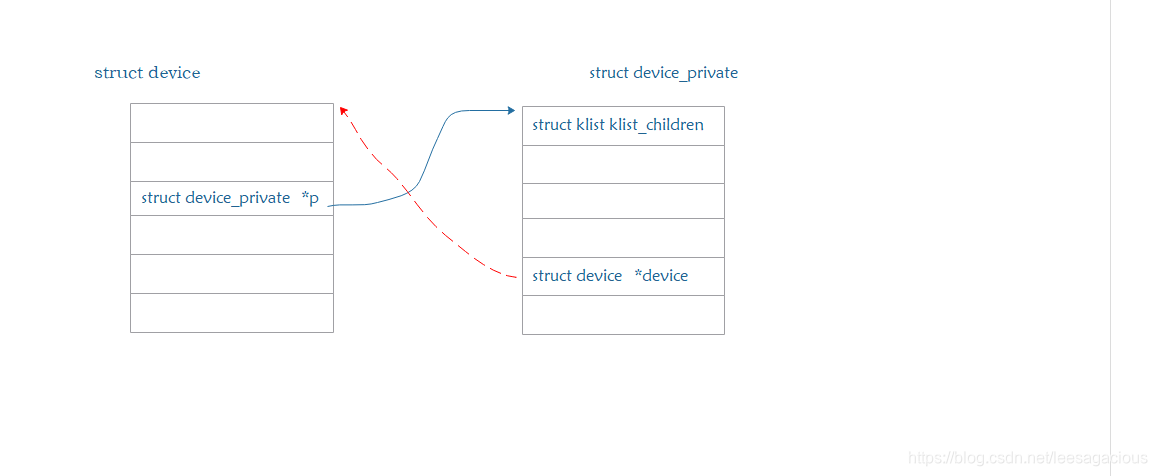
要注册的device 是否设置了设备的私有数据.
这个私有数据存在的意义之一: 提供该设备的子设备挂接的链表,
也就是说: 子设备挂载到了父设备维护的链表上的.
struct device_private {
struct klist klist_children;
}
*/
if (!dev->p) {
/*
如果你不设置device_private,那么kernel帮你设置一个,
也就是说无论如何 注册的每一个设备都必须有自己的私有数据 device_private
好,😄,下面画一个图来呈现这个核心的数据结构. bus_type 中也有类似的架构设计
*/
error = device_private_init(dev);
if (error)
goto done;
}
/*
设置device的名字.
注意了,在后面遍历klist链表的过程中,匹配driver的时候,有可能会使用到这里设置的名字
platform device driver 可以参见 platform_bus_type 提供的 platform_match()函数.
好,如果不提供init_name呢, 也好办,下面就会有设置.
*/
if (dev->init_name) {
dev_set_name(dev, "%s", dev->init_name);
dev->init_name = NULL;
}
/*
还是在设置名字,在注册device的时候设置好名字,可以帮组kernel减轻很多工作
好,即使你注册device的时候没有名字,也行,但是设备所属的总线必须有名字
不然,下面一个判断就会注册该device失败,
*/
if (!dev_name(dev) && dev->bus && dev->bus->dev_name)
dev_set_name(dev, "%s%u", dev->bus->dev_name, dev->id);
/*
一个婴儿刚出生加入到人类社会中来,得起个名吧. 即使像朱重八、朱初一之类得,
感慨那些带有父母姓氏得孩子得名字,也许是女性地位在家庭中的提升的表现吧.
*/
if (!dev_name(dev)) {
error = -EINVAL;
goto name_error;
}
/*
kernel也会给你一个温馨得提示,哈哈😄
不过这个需要开启 CONFIG_DYNAMIC_DEBUG 配置才行.
好,到这里终于是吧名字给搞定了.
看,为了一个name, kernel 竟然用了三个if来判断, 真TMD啰嗦 !!
不过既然这样来架构,也说明device 名字得重要性.
*/
pr_debug("device: '%s': %s\n", dev_name(dev), __func__);
/*
看,上面的code只做了两件事:
1 : 设置设备的名字
2 : 设置设备的私有数据结构.
好, 待把整个函数都分析完了,再从整体上看device driver mode 为什么要这么做.
有没有更优秀的方法.
*/
}
/*
父设备引用计数 +1
好了,如果要卸载这个设备,那么父设备的引用计数 就要 -1
device_unregister() {
👇
device_del() {
......
......
👇
put_device(parent);
}
}
生下来在户主户口簿上人数加 1, 死去 -1, 空空的来,如也的走,不带走一片云彩,
哈哈 😄,
什么样的设备没有父设备 ? 什么样的设备不挂载到总线上 ?
下面就有说明.
*/
parent = get_device(dev->parent);

















 2654
2654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









