




最近遇到内存和CPU不稳定情况,深究了下JVM有不少收获,总结如下:
堆内内存是java程序员在日常工作中解除比较多的, 可以在jvm参数中使用-Xms, -Xmx 等参数来设置堆的大小和最大值
堆内内存 = 年轻代 + 老年代 + 持久代
年轻代 (Young Generation)
存放的是新生成的对象,年轻代的目标是尽可能快速的收集掉那些生命周期短的对象。
Eden
大部分对象在Eden区中生成,当Eden区满时, 依然存活的对象将被复制到Survivor区, 当一个Survivor 区满时, 此区的存活对象将被复制到另外一个Survivor区
Survivor(通常2个)
当两个 Survivor 区 都满时, 从第一个Survivor 区 被复制过来 且 依旧存活的 对象会被复制到 老年区(Tenured)
Survivor 的两个区是对称的, 没有先后关系, 所有同一个区中可能同时存在从Eden复制过来的对象 和 从前一个 Survivor 复制过来的对象。Survivor 区可以根据需要配置多个, 从而增加对象在年轻代的存在时间, 减少被放到老年代的可能。
老年代 (Old Generation)
存放了在年轻代中经历了N次垃圾回收后仍存活的对象, 是一些生命周期较长的对象
持久代 (Permanent Generation)
存放静态文件, 如静态类和方法等。持久代对垃圾回收没有显著影响, 但是有些应用可能动态生成或者调用一些class, 比如Hibernate, Mybatis 等, 此时需要设置一个较大的持久代空间来存放这些运行过程中新增的类。
设置持久代大小参数: -XX:MaxPermSize= Perm => Permanent
垃圾回收(GC)
Scavenge GC
一般当新对象生成并且在Eden申请空间失败时就会触发Scavenger GC, 对Eden区域进行GC, 清除非存活对象, 并且把尚存或的对象移动到Survivor区, 然后整理两个Survivor区。
该方式的GC是对年轻代的Eden区进行,不会影响到年老代。
由于大部分对象是从Eden区开始的, 同时Eden区分配的内存不会很大, 所以Eden区的GC会很频繁。
Full GC
对整个堆进行整理, 包括Young, Tenured 和Permanent。所消耗的时间较长, 所以要尽量减少 Full GC 的次数,导致 Full GC 的可能原因:1、老年代(Tenured) 被写满 2、持久代(Permanent) 被写满
System.gc() 被显示调用
上一次GC之后Heap 的各域分配策略动态变化
常用垃圾回收算法
Reference Counting (引用计数算法)、Mark-Sweep (标记清除法)、Coping (复制法)、Mark-Compact (标记压缩法)、Generational Collecting (分代收集法)、Region (分区法)、GC Roots Tracing (可达性算法)、堆外内存(off-heap memory)
定义:堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存
java.nio.DirectByteBuffer:Java 开发者经常用 java.nio.DirectByteBuffer 对象进行堆外内存的管理和使用, 该类会在创建对象时就分配堆外内存。
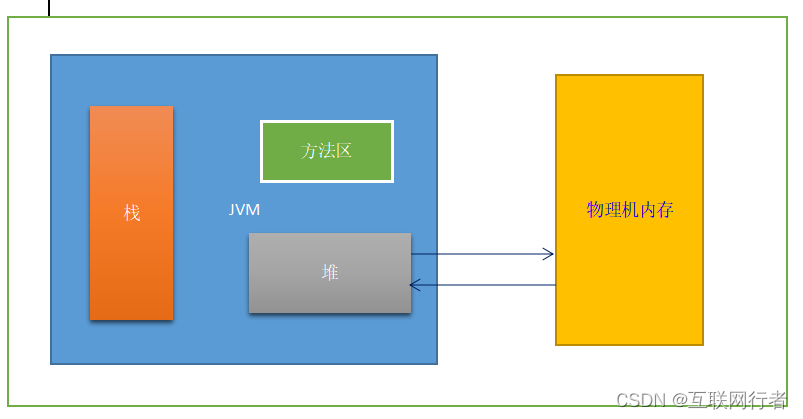
DK1.8 取消了方法区, 由MetaSpace(元空间)代替。-XX:MaxPermSize由 -XX:MetaspaceSize, -XX:MaxMetaspaceSize 等代替
使用堆外内存的优点
减少了垃圾回收机制(GC 会暂停其他的工作)
加快了复制的速度,堆内在flush到远程时, 会先复制到直接内存(非堆内存), 然后再发送。而堆外内存(本身就是物理机内存)几乎省略了该步骤
使用堆外内存的缺点
内存难以控制,使用了堆外内存就间接失去了JVM管理内存的可行性,改由自己来管理,当发生内存溢出时排查起来非常困难。

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









