




基本思路:
1.将pdf转换为word文档
2.利用poi解析word文档中的table
maven引用:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.1</version>
</dependency>
解析word核心代码
1.创建一个 XWPFDocument 获取到内容体迭代器

2.获取迭代器中的table数据,这是一个list
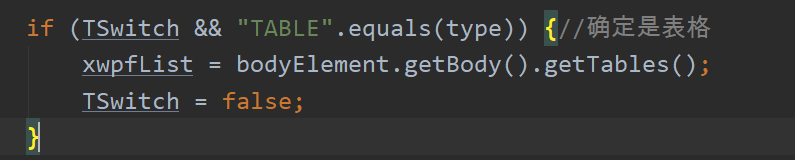
3.遍历list,获取到具体的一个table XWPFTable
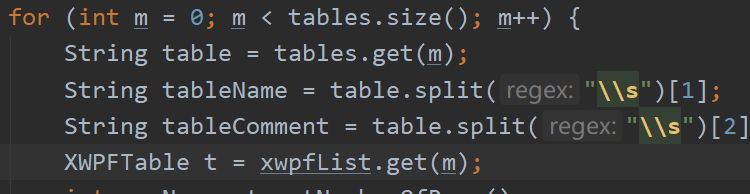
4.获取到table的某一行数据
![]()
5.获取到具体某一列的数据
![]()
到此解析过程结束。
疑惑: 为什么不直接解析pdf文件?
pdf也可以解析,但pdf的table没有明显的标志, word 解析可以精确到某一列。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









