



正文共1956张图,1张图,预计阅读时间8分钟。
推荐系统最有效的方法就是A/B test进行模型之间的对比,但是由于现实原因的局限,存在现实实时的困难性,所以,梳理了一些可以补充替代的指标如下,但是离线评估也存在相应的问题:
数据集的稀疏性限制了适用范围,用户之间的交集稀疏。
评价结果的客观性,由于用户的主观性,不管离线评测的结果如何,都不能得出用户是否喜欢某推荐系统的结论,只是一个近似的评估。
深度评估指标的缺失。(如点击深度、购买客单价、购买商品类别、购买偏好)之间的关联关系。
冷启动
Exploration 和 Exploitation问题
召回集测试
recall
命中skn个数/用户真实点击skn个数precision
命中skn个数/所有预测出来的skn总数F1-Measure
2/(1/recall+1/precison)交互熵
MAE
RMSE
相关性
常见的比如:Pearson、Spearman和Kendall’s Tau相关,其中Pearson是更具数值之间的相似度,Spearman是根据数值排序之间的相似度,Kendall’s Tau是加权下的数值排序之间的相似度。基尼系数
信息熵
排序部分测试
NDCG(Normalize DCG)
RBP(rank-biased precision)
RBP和NDCG指标的唯一不同点在于RBP把推荐列表中商品的浏览概率p按等比数列递减,而ND CG则是按照log调和级数形式。
离线模型与在线模型之间的评估
很多时候,我们需要确定离线模型的效果足够的健壮才能允许上线进行线上测试,那如何进行离线模型与线上模型的评估对比就是一个比较复杂的问题。
难点
缺乏公平的测试数据
实际处理过程中,我们发现,所有的已知点击都是来自线上模型推荐的结果,所以极端情况下,线上的recall是100%缺乏公认的衡量指标
在线下对比中,我们发现比如recall、precision、F1-Measure等指标都是大家约定俗成的,不存在很大的争议,而离线在线模型对比却没有一个准确公认的衡量指标
指标设计
online_offline_cover_rate&first_click_hit_rate
这一组指标是结合在一起看的,其中online_offline_cover_rate是指针对每一个用户计算理线模型推荐的商品与在线模型推荐的商品的重合个数/在线模型的推荐商品个数,online_offline_cover_rate越低代表离线模型相对在线模型越独立;first_click_hit_rate是指offline模型对用户每天第一次点击的命中率,也就是命中次数/总统计用户数。
结合这两个指标,我们可以得到在online_offline_cover_rate越低的情况下,却能覆盖线上用户真实点击的次数越多,代表offline模型的效果优于线上模型。
online_precision_rate/offline_precision_rate
离线模型的准确率和在线模型的准确率。
这边在实际计算的时候采取了一个技巧,针对某个推荐位计算在线模型准确率的时候,用的是从来没有浏览过这个推荐位的用户的浏览历史匹配这个用户这个推荐位的推荐结果。这样可以避免用户的点击结果受到推荐位推荐结果影响的问题。
举个例子:用户在推荐位A上没有浏览过,他的点击是不受推荐位A推荐的商品影响的,拿这个用户推荐位A我们给他线上推荐的结果作为线上模型的推荐结果去计算,这样才更加合理。
online_recall_rate/offline_recall_rate
离线模型的召回率和在线模型的召回率。
同上解释。
roi_reall/roi_precision
同上解释,只是把未来的点击作为match源更换成了加购物车、购买、收藏这些数据。
其他评估方向
覆盖率
推荐覆盖率越高, 系统给用户推荐的商品种类就越多 ,推荐多样新颖的可能性就越大。如果一个推荐算法总是推荐给用户流行的商品,那么它的覆盖率往往很低,通常也是多样性和新颖性都很低的推荐。
多样性
采用推荐列表间的相似度(hamming distance、Cosine Method),也就是用户的推荐列表间的重叠度来定义整体多样性。
新颖性
计算推荐列表中物品的平均流行度。
其他
用户满意度、用户问卷、信任度、鲁棒性、实时性。
评测维度
最后说一下评测维度分为如下3种,多角度评测:
用户维度
主要包括用户的人口统计学信息、活跃度以及是不是新用户等。物品维度
包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。时间维度
包括季节,是工作日还是周末,是白天还是晚上等。
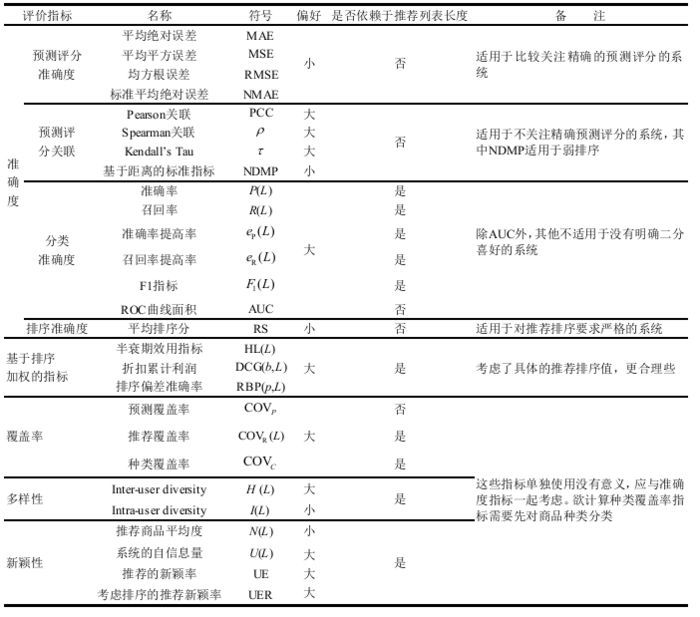
附常规评价指标的整理结果(来自论文Evaluation Metrics for Recommender Systems):
原文链接:https://www.jianshu.com/p/54182c5e1fb0
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看


















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









