



 本文介绍了使用OpenCV进行人脸识别的第一步——数据收集和预处理。作者通过编写程序利用电脑摄像头自拍获取人脸照片,然后对照片进行预处理,包括人脸检测、ROI分割和调整尺寸,使其与ORL人脸数据库的图像大小一致,为后续的模型训练做好准备。
本文介绍了使用OpenCV进行人脸识别的第一步——数据收集和预处理。作者通过编写程序利用电脑摄像头自拍获取人脸照片,然后对照片进行预处理,包括人脸检测、ROI分割和调整尺寸,使其与ORL人脸数据库的图像大小一致,为后续的模型训练做好准备。
 3天密集学习 快速带你晋级
阅读全文
>
3天密集学习 快速带你晋级
阅读全文
>
本系列人脸识别文章用的是opencv2,最新版的opencv3.2的代码请参考文章:
《OpenCV之识别自己的脸——C++源码放送》;
《人脸识别源码运行指南》(小编附在文末)
前段时间对人脸检测进行了一些尝试:人脸检测(C++/Python)(http://www.jianshu.com/p/504c081d7397)但是检测和识别是不同的,检测解决的问题是图片中有没有人脸;而识别解决的问题是,如果一张图片中有人脸,这是谁的脸。人脸检测可以利用opencv自带的分类器,但是人脸识别就需要自己收集数据,自己训练分类器了。opencv给出的有人脸识别的教程:Face Recognition with OpenCV(https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial.html)。网上也可以找到中文版本的。
正所谓自己动手丰衣足食。站在巨人的肩膀上,参考前辈们的经验,终于能够识别出自己了。由于感觉内容较多,而且没有时间一次性写完,所以准备分阶段来写。每一篇博客是一个阶段的工作。初步设想分为数据收集和预处理、训练模型和人脸识别三个部分。今天先写第一部分。

本次用的数据集市opencv给出的教程里面的第一个数据集:The AT&T Facedatabase(http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html)。又称ORL人脸数据库,40个人,每人10张照片。照片在不同时间、不同光照、不同表情(睁眼闭眼、笑或者不笑)、不同人脸细节(戴眼镜或者不戴眼镜)下采集。所有的图像都在一个黑暗均匀的背景下采集的,正面竖直人脸(有些有有轻微旋转)。
下载下来之后是这样的:
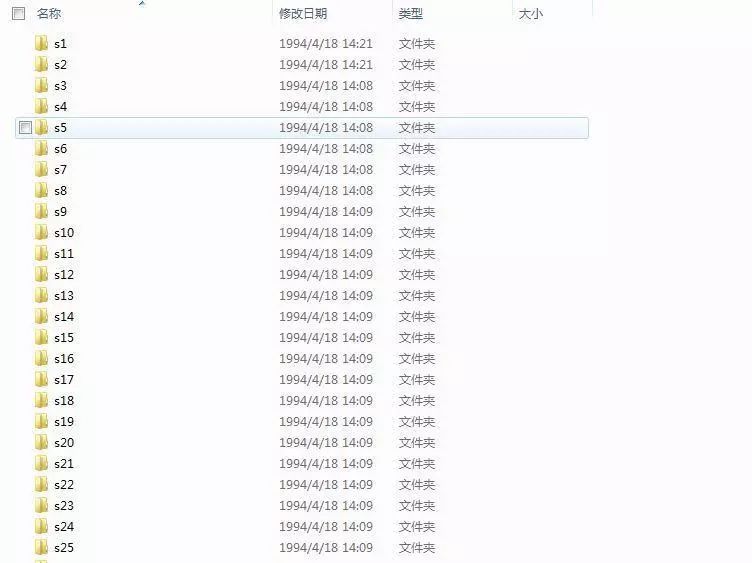
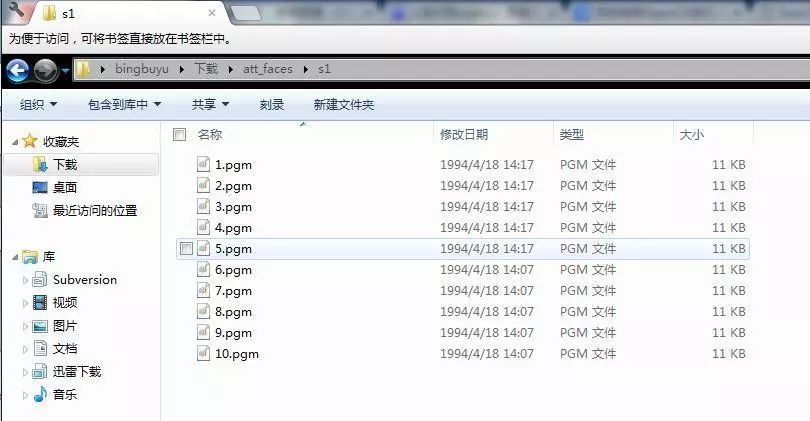
可以看到每个人一个文件夹,每个文件夹下是这个人的十张照片,但是不是我们熟悉的BMP或者是PNG或者是JPEG格式的,而是PGM格式的。windows7自带的照片查看器和画图软件都不能打开这种格式的图片。
不过好在我昨天刚对imread()函数研究过:使用imread()函数读取图片的六种正确姿势。所以记得opencv文档里有这样的描述:

imread()还是很强大的,所以写个程序看看那这些人是什么样吧。
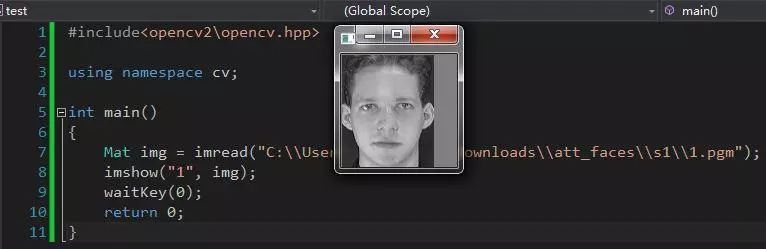
2、自己的人脸数据集
1、拍照程序
想要识别自己,单有别人的数据集还是不行的,还需要自己人脸的照片才行。这就需要我们收集自己的照片,然后和上面的那个数据集一起来训练模型。在拿着手机自拍的过程中我想到,问什么不写一个程序用电脑的摄像头自拍呢,随便还能研究下怎么用opencv实现拍照的功能。经过一番实验(其实还是费了好长时间),终于写了一个拍照程序。
程序的功能就是打开电脑摄像头,当P键按下(P是拍照的首字母?还是Photo的首字母?还是Picture的首字母?)的时候,保存当前帧的图像。简单到没朋友(竟然耗费了那么久!)。
while (1)
{
char key = waitKey(100);
cap >> frame;
imshow("frame", frame);
string filename = format("D:\\pic\\pic%d.jpg", i);
switch (key)
{
case'p':
i++;
imwrite(filename, frame);
imshow("photo", frame);
waitKey(500);
destroyWindow("photo");
break;
default:
break;
}
}
然后我们就可以运行程序,不停地按下p键对自己一通狂拍了。
2、预处理
在得到自己的人脸照片之后,还需要对这些照片进行一些预处理才能拿去训练模型。所谓预处理,其实就是检测并分割出人脸,并改变人脸的大小与下载的数据集中图片大小一致。
人脸检测在之前的博客中已经做了介绍,这里就不再赘述。详情参考:OpenCV人脸检测(C++/Python)(http://www.jianshu.com/p/504c081d7397)。用ROI分割即可。
检测出人脸之后改变大小使之与ORL人脸数据库人脸大小一致。通过加断点在Locals里面或者是ImageWatch可以看到ORL人脸数据库人脸的大小是92 x 112。
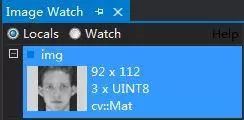
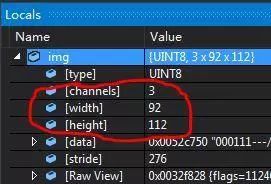
这里只需要对检测后得到的ROI做一次resize即可。
这两步的代码如下:
std::vector<Rect> faces;
Mat img_gray;
cvtColor(img, img_gray, COLOR_BGR2GRAY);
equalizeHist(img_gray, img_gray);
//-- Detect faces
face_cascade.detectMultiScale(img_gray, faces, 1.1, 3, CV_HAAR_DO_ROUGH_SEARCH, Size(50, 50));
for (size_t j = 0; j < faces.size(); j++)
{
Mat faceROI = img(faces[j]);
Mat MyFace;
if (faceROI.cols > 100)
{
resize(faceROI, MyFace, Size(92, 112));
string str = format("D:\\MyFaces\\MyFcae%d.jpg", i);
imwrite(str, MyFace);
imshow("ii", MyFace);
}
waitKey(10);
}
至此,我们就得到和ORL人脸数据库人脸大小一致的自己的人脸数据集。然后我们把自己的作为第41个人,在我们下载的人脸文件夹下建立一个s41的子文件夹,把自己的人脸数据放进去。就成了这样下面这样,最后一个文件夹里面是我自己的头像照片:
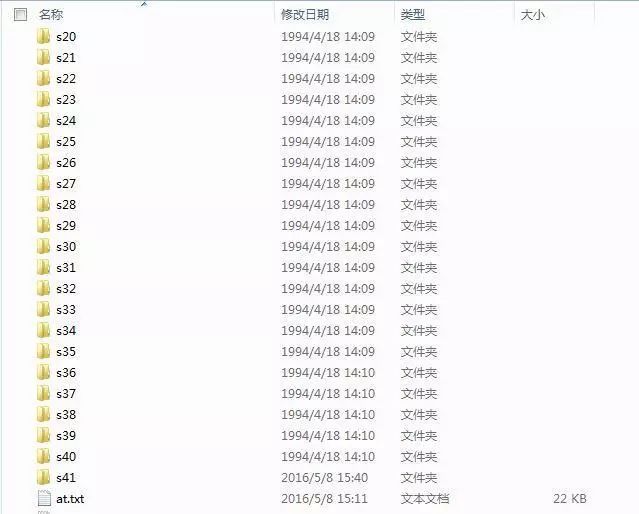
最后那个at.txt放到下一次再说,训练模型就靠它了。
这里有一点值得注意:我这里保存的图像格式是.jpg的,而不是跟原数据集一样是.pgm的。经测试仍然可以训练出可以正确识别我自己人脸的模型来。但是如果大小不一致会报错。
OpenCV之识别自己的脸——C++源码放送
在将近一年之前,我在优快云专栏《OpenCV实践之路》中连续发了三篇博客,完整地描述了基于OpenCV进行人脸识别的全过程。三篇都将近一万的阅读量和大量的评论的表明,人脸识别果然是大家在学习OpenCV过程中最感兴趣的课题,之一。当然,也有可能是本科生毕设老师最感兴趣的课题之一。
由于当时写的时候是按照前后流程来的,所以源码比较分散。加之我想当然地认为,很多源码是之前博客中已经放出来的,可以一句带过。这导致了很多同学学习的时候很不方面。但是我由于重装系统,导致当初的源码遗失,也一直没有抽出时间去重新整理一下。这个清明节,没有出门,根据之前的博客基于当下最新的OpenCV3.2重新整理了一遍源码。现在放出来,以飨读者。
当然了,重新整理也不是简单的把源码收集到一起,如果真的那么简单,也就不用去整理了,大家自行收集即可。因为OpenCV3.2人脸识别的内容也是有些小变动。所以现在的代码跟原来的三篇博客仍然是统一的,但是有一些细节不同。
1、自动拍照
之前采集自己的图像的时候,程序设定是运行之后按’p’键拍照并保存图像,然后需要自己手动的去把图像大小转化为跟ORL人脸数据库中的图片大小一样。
现在一切自动,只需要运行即可拍照,变化尺寸,并保存。默认设定拍10张照片,与ORL人脸数据库一致。
2、Python脚本生成at.txt
当时写博客的时候还不会用Python,所以生成的at.txt并不是s1文件夹对应的label就是1,s2就对应2。而是比较混乱的。谁是谁需要自己去记忆。
经过修改后的Python脚本可以是文件夹可label完美对应起来了。
3、训练代码
训练人脸识别模型的代码部分有些改动,主要是因为OpenCV的变动。
头文件和命名空间需要各加一句:
#include<opencv2\face.hpp>
using namespace cv::face;
创建模型部分的改变,原来的代码是
Ptr<FaceRecognizer> model = createEigenFaceRecognizer();
Ptr<FaceRecognizer> model1 = createFisherFaceRecognizer();
Ptr<FaceRecognizer> model2 = createLBPHFaceRecognizer();
现在改为:
Ptr<BasicFaceRecognizer> model = createEigenFaceRecognizer();
Ptr<BasicFaceRecognizer> model1 = createFisherFaceRecognizer();
Ptr<LBPHFaceRecognizer> model2 = createLBPHFaceRecognizer();
其余部分没有太大变化。
源码已经分别上传到Github、百度网盘。其中github由于大小限制,不含我训练好的模型。
Github:`https://github.com/LiuXiaolong19920720/recognise-your-own-face
百度网盘:链接:http://pan.baidu.com/s/1nuPFthR 密码:slh8
还要再强调的一点是:人脸识别源码运行指南
人脸识别的源码放出来之后,不少小伙伴下载之后仍然不能运行成功。于是被逼无奈,把源代码改成了我认为最容易运行成功的版本。即使如此,我认为写下这个指南还是有必要的。因为反复回答相同的问题实在是太累人了。
重复一遍,本文环境为win7+vs2015+opencv3.2_with_contrib
网盘: http://pan.baidu.com/s/1b1J23O 密码:kv1e(谨记此网盘链接与密码,是该系列最新代码下载的地址)
首先还是说明几个问题,虽然都说过,但是还是有人问。以后再有人问就直接给他这篇文章。
找不到FaceRecognizer
FaceRecognizer在opencv的contrib模块里的face模块里面。而opencv官方下载的opencv默认是不带contrib的,要实现人脸识别需要用编译了contrib模块的opencv。一般来说需要自己编译。但是自己编译比较麻烦,网上有人分享了编译好的opencv3.2的版本,下载地址如下:
链接:http://pan.baidu.com/s/1qYx3v8S 密码:i0c0
csv文件(也即at.txt)难以自动生成。
源码中我已经写了一个名为add_label.py的python脚本,运行此脚本可以自动生成at.txt。
有时程序崩溃但是黑窗无报错信息。
一个可能的原因是,添加附加依赖项的时候,debug模式最好只添加*d.lib。而release模式最好只添加*.lib。
方便起见,下载的源码的文件夹下已经包含了需要用的ORL人脸数据库。在配置好opencv的情况下,需要以下几步。
1、首先用VS打开face-rec.sln。在解决方案管理器中的源文件下添加take_photos.cpp,如果源文件下还有其他cpp文件,请它们排除到项目之外。然后运行此拍照程序。如果拍照效果不好,请自动调整人脸与摄像头之间的距离,或者调节光照条件。拍好的照片会保存在att_faces\s41文件夹下。
2、生成csv文件。需要电脑上安装有Python2,如果是Python3的话需要把print语句注释掉,没有实际测试过。如果对python有了解,应该不难。在add_label.py所在文件夹下shift+右键然后选择在此处打开命令行窗口。在命令行输入命令:python add_label.py,Enter运行即可。
3、回到VS。把take_photos.cpp排除到项目之外,添加train.cpp到源文件,运行。最后输出3行类似下面的语句表示训练模型成功。此时打开工程文件夹可以看到生成的后缀为xml的模型文件。
Predicted class = 9 / Actual class = 9.
4、回到VS。把train.cpp排除到项目之外,添加rec-your-own-face.cpp到源文件,运行。此时应该会打开摄像头并识别自己的脸。
此人脸识别程序只能做学习研究,因为这个正确率略低。有更高要求的小伙伴请自行探究更好的方法,在这方面我能指点内容的有限。
原文链接:http://www.jianshu.com/p/c722d20944f2
优快云博客地址:http://blog.youkuaiyun.com/xingchenbingbuyu/article/details/73733490
作者公众号:公众号CVPy,旨在分享OpenCV和Python的实战内容,欢迎关注。
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络

点击“阅读原文”直接打开【北京站 | GPU CUDA 进阶课程】报名链接

















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









