




说明一下,内容是根据李宏毅课程的四张图片,利用AI生成的,包括标题
你有没有过这种“崩溃时刻”:模型在训练数据上表现完美,Loss低到像开了挂,结果一放到测试数据里,直接从“学霸”变“学渣”?
别怀疑人生,这不是你代码写得烂——机器学习里的“坑”,早就被这几张图扒得明明白白了。今天咱们就用这几张图,把模型训练的“玄学”拆成能看懂的“科学”。
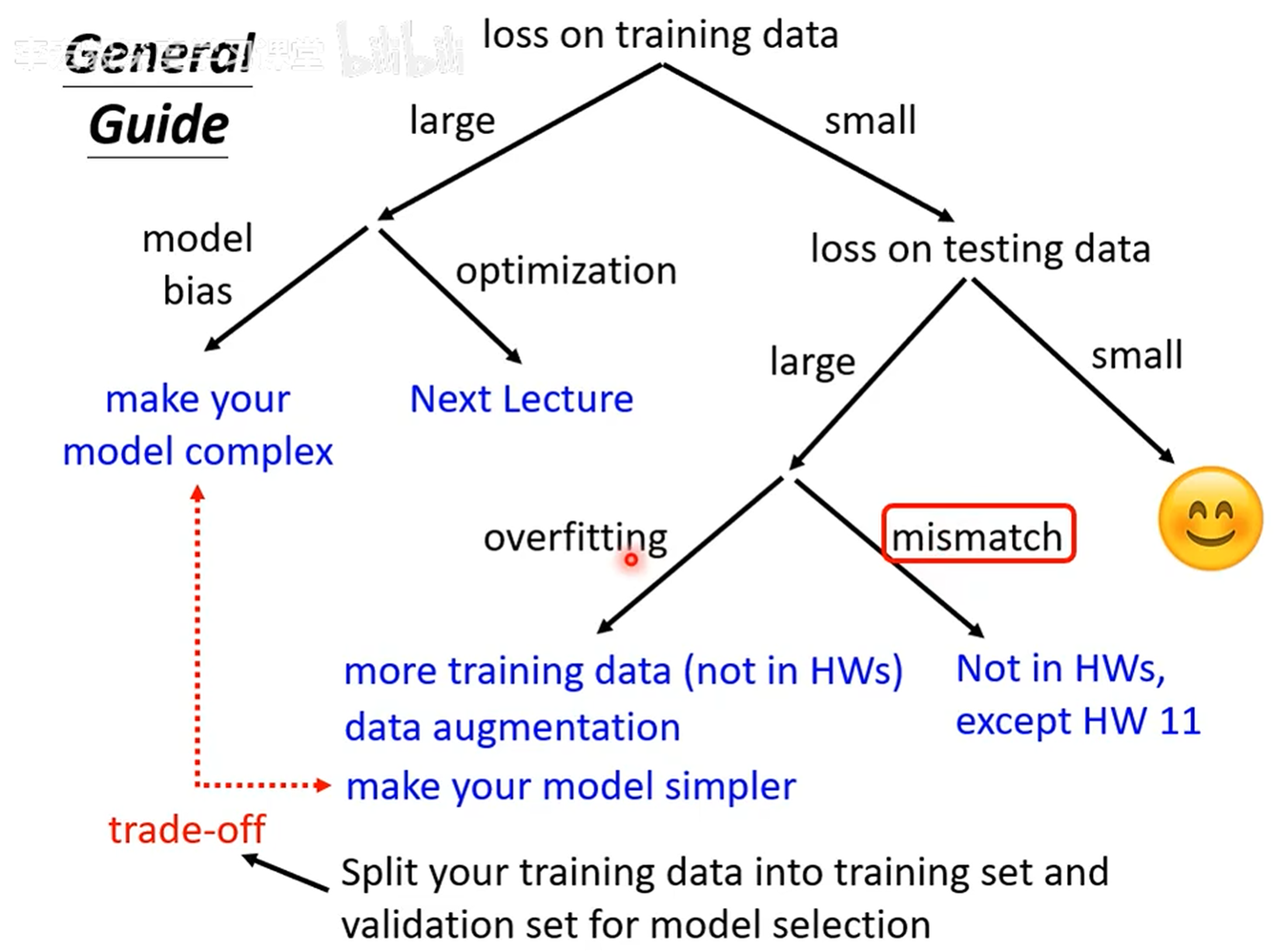
一、先看“排障流程图”:你的模型到底哪里坏了?
第一张图直接给了个 “模型急诊指南” ,把训练中的问题分成了两类:
-
如果训练集Loss很大:
要么是模型太简单(“模型偏差”),得给模型“加装备”——比如增加参数、补充特征;
要么是优化没做好(比如学习率太高/太低),这得调优化器(下次讲)。 -
如果训练集Loss小,但测试集Loss大:
这是最常见的“坑”,分两种情况:
① 过拟合:模型把训练集的“噪声”当“规律”学了(比如训练集里有个错别字,模型连这个错别字都记住了);
② 数据不匹配:训练集和测试集的分布差太远(比如训练用“宠物猫图片”,测试给“野生老虎图片”)。
二、过拟合:模型太努力,反而学“傻”了
第二张图完美解释了“过拟合”——模型太想“讨好”训练数据,连噪声都学进去了:
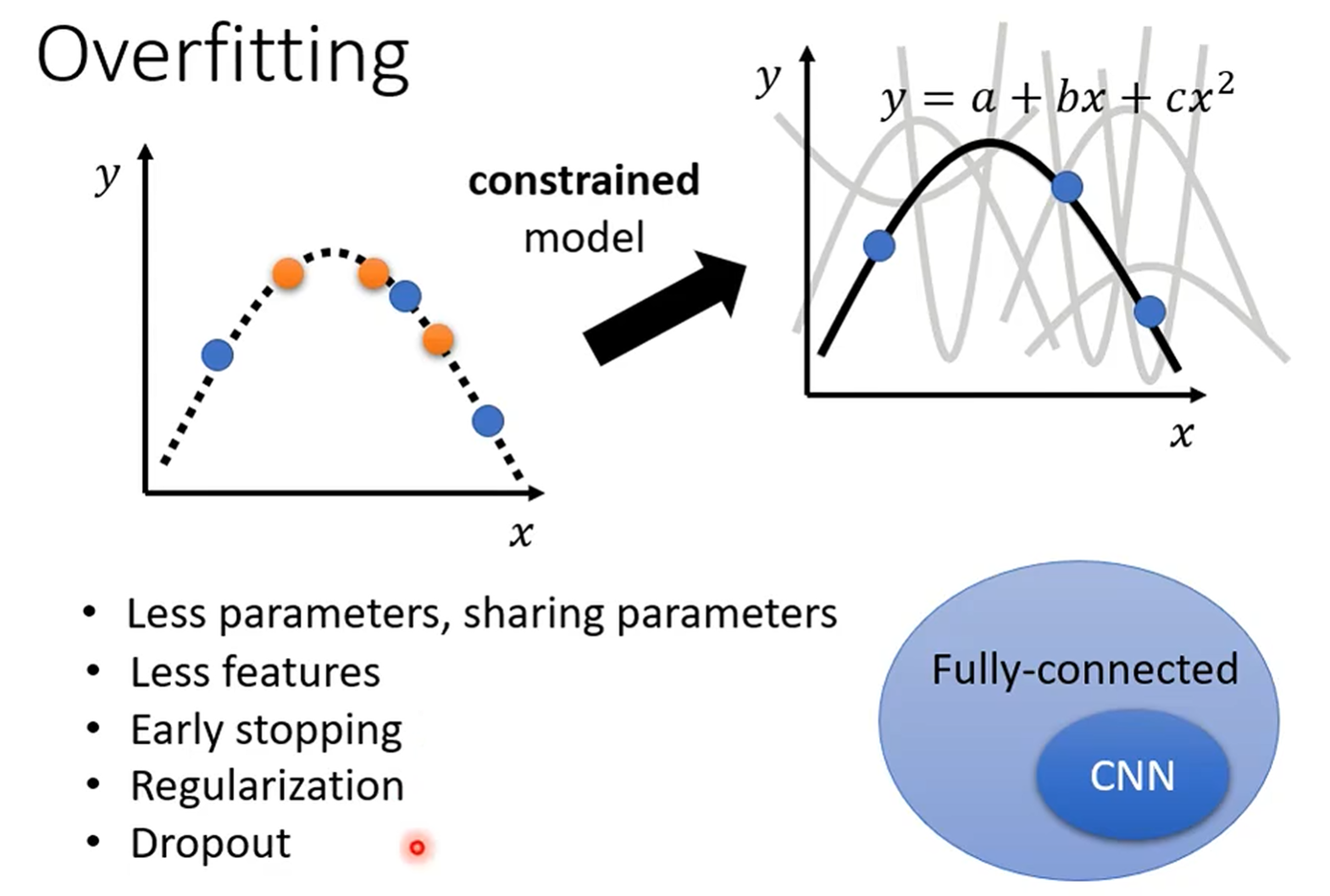
左边的虚线疯狂贴合训练点(连点的抖动都不放过),但这根本不是真实规律;右边把模型“约束”住(比如少点参数、加正则化),反而能抓住真正的趋势。
对付过拟合的“药方”也很直接:
- 简化模型:减少参数、砍掉冗余特征;
- 早停:训练到一半就喊“停”,别让模型学太细;
- 加“枷锁”:用正则化(L1/L2)、Dropout限制模型“乱学”;
- 喂更多数据:要么加训练样本,要么做数据增强(比如给图片加滤镜、裁边)。
三、偏差-复杂度权衡:模型不是“越复杂越好”
第三张图的“U型曲线”,是机器学习的核心规律之一:
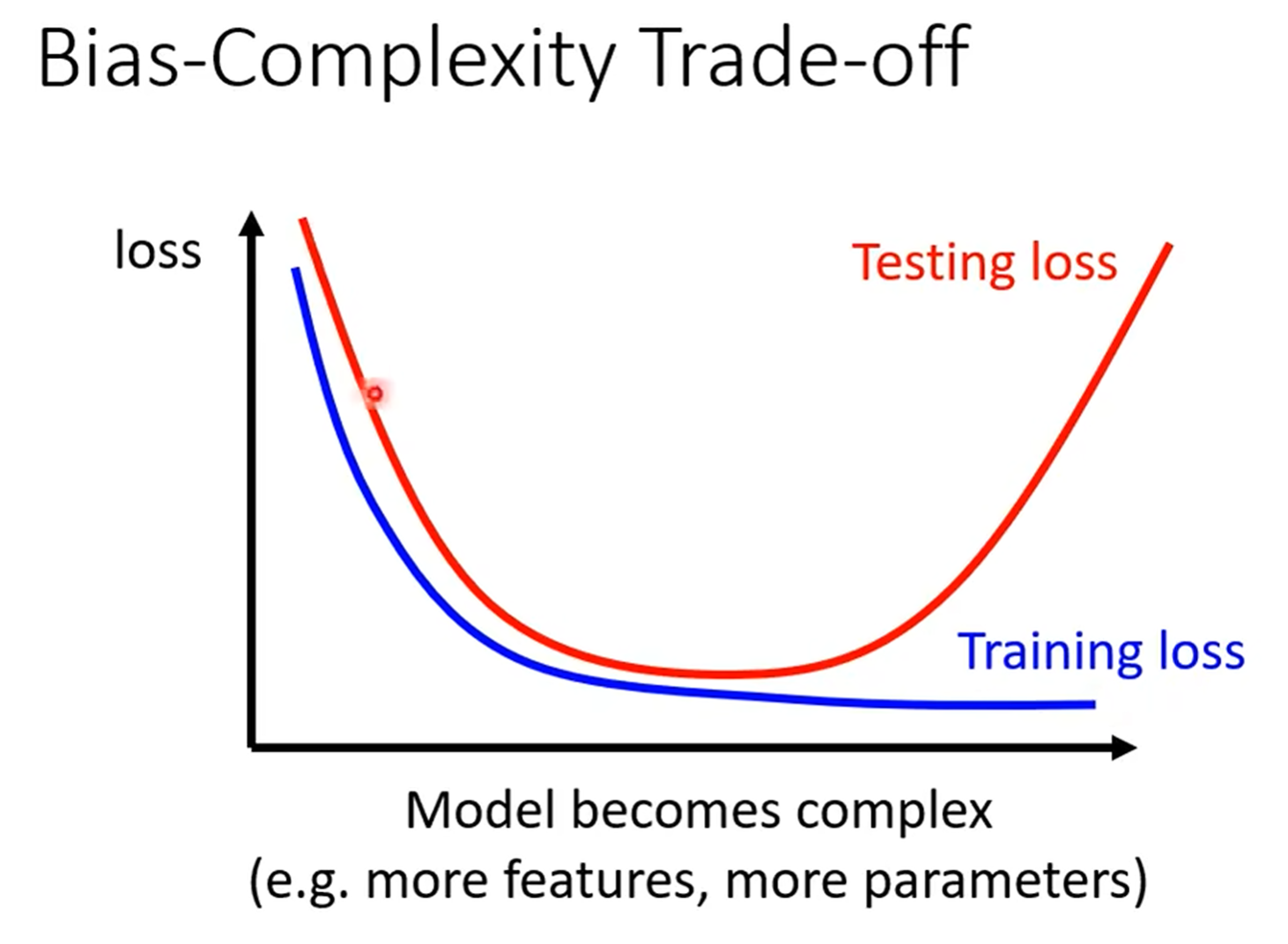
- 模型太简单时:训练和测试Loss都高(“欠拟合”),连训练集的基础规律都没学会;
- 模型变复杂时:训练Loss会持续下降,但测试Loss降到某个点就开始上升——这就是“过拟合”的信号。
关键是找“平衡点”:别让模型太“笨”,也别让它太“钻牛角尖”。
四、Kaggle选手的血泪:别信“公开测试集”的鬼话
第四张图是竞赛玩家的日常“翻车现场”:
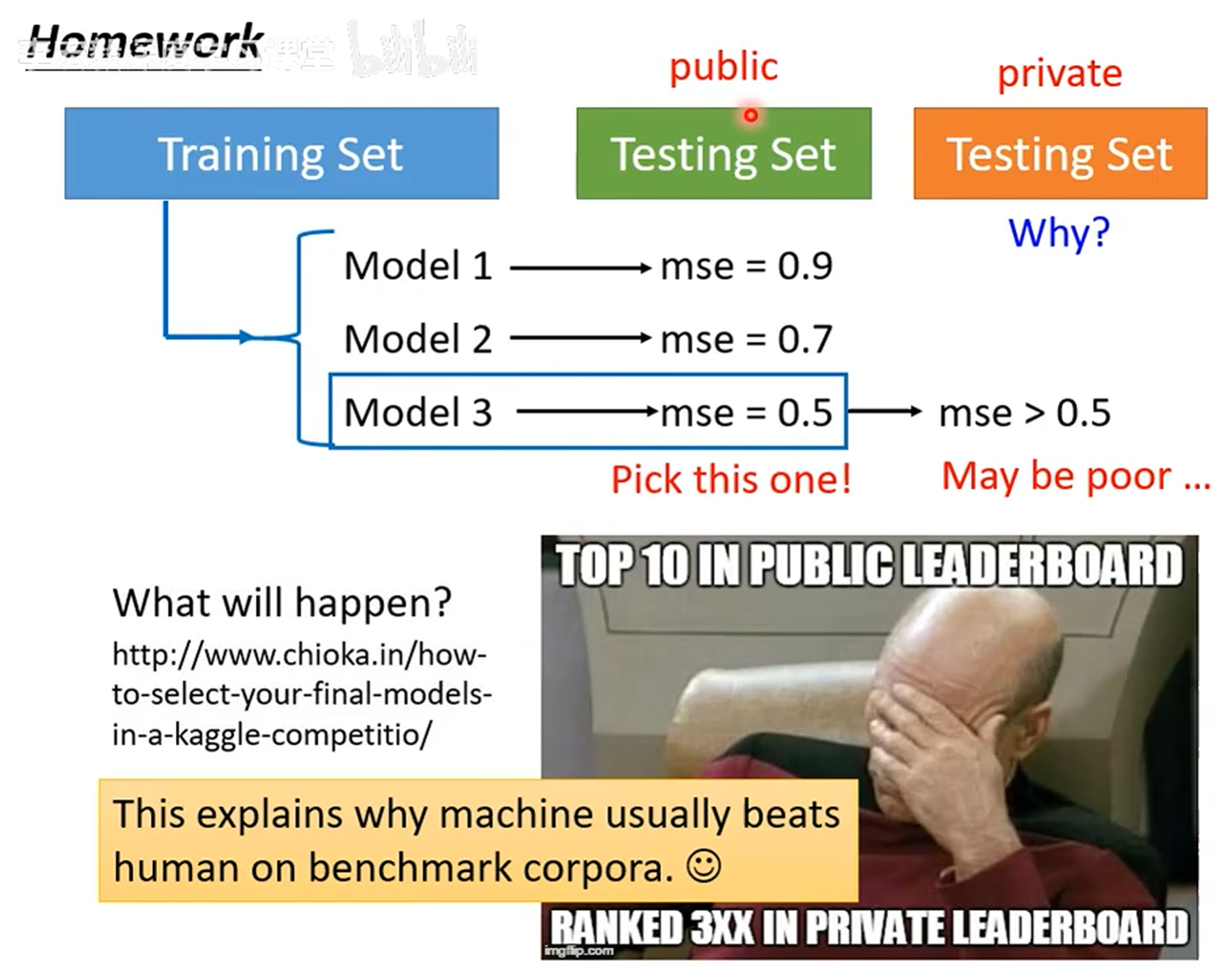
公开测试集上模型3的MSE只有0.5,结果私有测试集直接掉到300名——原因是:你对着公开测试集调模型,本质是“为公开集量身定制”,到了真正的测试数据(私有集),模型就“不认账”了。
正确操作:把训练集拆成“训练+验证集”,用验证集调模型——测试集是“期末考试”,别提前偷看!
最后:模型训练就是“走钢丝”
其实机器学习没那么玄,就是在“欠拟合”和“过拟合”之间找平衡。下次训模型卡壳,直接拿这几张图当“诊断表”:
- 训练Loss大 → 加模型复杂度;
- 测试Loss大 → 防过拟合。
模型问题速查卡片(也是AI生成)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









