



 本文探讨了在使用Flink进行Kafka连接时遇到的JobExecutionException,通过定位报错发现是由于Flink和Kafka版本不匹配引发的。解决方案是更新依赖到flink-connector-kafka_2.12的1.11.1版本,确保与Flink版本同步。
本文探讨了在使用Flink进行Kafka连接时遇到的JobExecutionException,通过定位报错发现是由于Flink和Kafka版本不匹配引发的。解决方案是更新依赖到flink-connector-kafka_2.12的1.11.1版本,确保与Flink版本同步。
报错如下
Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
at org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:119)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:602)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1962)
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:229)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1962)
at org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:996)
at akka.dispatch.OnComplete.internal(Future.scala:264)
at akka.dispatch.OnComplete.internal(Future.scala:261)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
at scala.concurrent.impl.CallbackRunnable.run$$$capture(Promise.scala:36)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala)
at org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252)
at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:572)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
at scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436)
at scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435)
at scala.concurrent.impl.CallbackRunnable.run$$$capture(Promise.scala:36)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91)
at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:90)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:40)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:44)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:116)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:78)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:224)
at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:217)
at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:208)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:610)
at org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:89)
at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:419)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:286)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:201)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:154)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at akka.actor.Actor$class.aroundReceive$$$capture(Actor.scala:517)
at akka.actor.Actor$class.aroundReceive(Actor.scala)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
... 4 more
Caused by: java.lang.NoSuchMethodError: org.apache.flink.api.common.state.OperatorStateStore.getSerializableListState(Ljava/lang/String;)Lorg/apache/flink/api/common/state/ListState;
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.initializeState(FlinkKafkaConsumerBase.java:858)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.tryRestoreFunction(StreamingFunctionUtils.java:185)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.restoreFunctionState(StreamingFunctionUtils.java:167)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.initializeState(AbstractUdfStreamOperator.java:96)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:107)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:264)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:400)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$2(StreamTask.java:507)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:92)
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:501)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:531)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:722)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:547)
at java.lang.Thread.run(Thread.java:748)
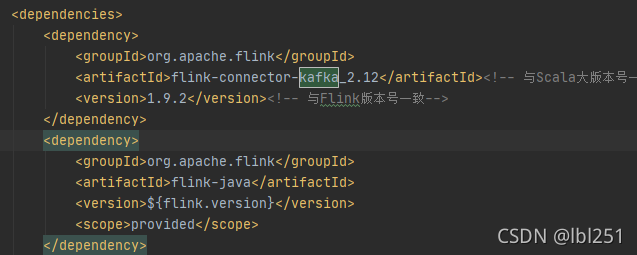
改成如下:问题解决,是版本的问题
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId><!-- 与Scala大版本号一致-->
<version>1.11.1</version><!-- 与Flink版本号一致-->
</dependency>

















 3658
3658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









