



安装软件
Linux:
sudo apt-get install geany
windows:
python -m pip install --user pygame-1.9.2a0-cp35-none-win32.whl
print函数
print("hello",end=',')结束符,不换行
print(“{:.2f}”.format(area))只输出两位小数
字符串
name = "ada lovelace"
name.title() = "Ada Lovelace" 临时
name.upper() = "ADA LOVELACE" 临时
name.lower() = "ada lovelace " 临时
favorite_language = ' python '
favorite_language.rstrip() = 'python ' 临时
favorite_language.lstrip() = ' python' 临时
favorite_language.strip() = 'python' 临时
字符串操作
str.capitalize() 首字母大写
str.casefold() 转换成小写字母
str.count(substr) 返回字符串str的子串sub出现的次数
str.encode(encoding=‘utf-8’) 返回字符串str经过经过encoding编码后的字节码
str.find(substr) 返回str的子字符串sub第一次出现的位置
str.replace(old, new) 替换字符串
str.split(substr) 分割字符串
列表
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
增加
bicycles.append('ducati') 永久
bicycles.insert(0, 'ducati') 永久
删除
del bicycles[0] 永久
last_owned = bicycles.pop(0) 默认最后一个元素 永久
bicycles.remove('trek') 永久
bicycles.clear() 删除所有元素
排序
bicycles.sort() 从小到大 永久
bicycles.sort(reverse=True) 从大到小 永久
sorted(bicycles) 从小到大 临时
sorted(bicycles, reverse = True) 从大到小 临时
反转
ls.reverse()
长度
len(bicycles)
数值列表
range(1,5) 是1,2,3,4
list(range(1,5) 是[1, 2, 3, 4 ]
range(2,11,2) 指定步子长度为2
列表统计
digits = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
min(digits)
0
max(digits)
9
sum(digits)
45
列表解析
squares = [value**2 for value in range(1,11)]
列表切片
players = ['charles', 'martina', 'michael', 'florence', 'eli']
print(players[1:4]) 默认开头和结尾 临时
复制列表
my_foods = ['pizza', 'falafel', 'carrot cake']
friend_foods = my_foods[:] 复制
friend_foods = my_foods 引用
ls.copy()生成一个新列表,复制ls中所有元素
元祖
dimensions = (200, 50) 不可修改元祖元素
dimensions = (400, 100) 但是可以重新定义变量
布尔表达式
game_active = True
can_edit = False
Python语言中,任何非零的数值、非空的数据类型都等价于True,0或空类型等价于False
字典
alien_0 = {'color': 'green', 'points': 5}
print(alien_0['color'])操作alien_0[a] = "b"新增del alien_0['points']删除for key, value in alien_0.items():遍历for name in alien_0.keys():遍历keysfor name in alien_0.values():遍历valuesfor name in set(alien_0.values()):set剔除重复项
输入
name = input("Please enter your name: ")
函数参数
def make_pizza(*toppings):
print(toppings)
make_pizza('pepperoni')
make_pizza('mushrooms', 'green peppers', 'extra cheese')
def build_profile(first, last, **user_info):`
profile = {}
profile['first_name'] = first
profile['last_name'] = last
for key, value in user_info.items():
profile[key] = value
return profile
user_profile = build_profile('albert', 'einstein', location='princeton',field='physics')
print(user_profile)
导入
-
import pizza -
from pizza import make_pizza -
from pizza import make_pizza as mp -
import pizza as p -
from pizza import *
继承
class ElectricCar(Car):
def __init__(self, make, model, year):
super().__init__(make, model, year)
文件操作
目录结构
- windows:\ \反斜杠
- macos和linux: / 斜杠
读
with open('text_files/pi_digits.txt') as file_object:
contents = file_object.read()
with open(filename) as file_object:
for line in file_object:
with open(filename) as file_object:
lines = file_object.readlines()
for line in lines:
写
with open(filename, 'w') as file_object:
file_object.write("I love programming.")
- 读取模式 (‘r’ )
- 写入模式 (‘w’ )
- 附加模式 (‘a’ )
- 读取和写入文件的模式(‘r+’ )
异常
try:
print(5/0)
except ZeroDivisionError:
print("You can't divide by zero!")
try:
with open(filename) as f_obj:
contents = f_obj.read()
except FileNotFoundError:
msg = "Sorry, the file " + filename + " does not exist."
print(msg)
else:
try:
except FileNotFoundError:
pass #什么都不做
else:
存储数据
import json
numbers = [2, 3, 5, 7, 11, 13]
filename = 'numbers.json'
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
import json
filename = 'numbers.json'
with open(filename) as f_obj:
numbers = json.load(f_obj)
print(numbers)
成员属性
_men私有
men公有
退出
python的程序有两种退出方式:os._exit(), sys.exit()。
os._exit()会直接将python程序终止,之后的所有代码都不会继续执行。即直接退出, 不抛异常, 不执行相关清理工作。
sys.exit(n)会引发一个异常:SystemExit,可以捕获异常执行些清理工作。此处用于捕获模块执行结果,如果这个异常没有被捕获,那么python解释器将会退出。如果有捕获此异常的代码,那么这些代码还是会执行。0为正常退出,其他数值(1-127)为不正常,可抛异常事件供捕获。
一般来说os._exit() 用于在线程中退出,sys.exit() 用于在主线程中退出。
try:
os._exit(0)
except:
print("die")
不会打印“die”
try:
sys.exit(0)
except:
print(‘die‘)
finally:
print(‘cleanup‘)
输出:
die
cleanup
一般情况下使用sys.exit()即可,一般在fork出来的子进程中使用os._exit()。
此外,还有exit()/quit() ,exit()跟 C 语言等其他语言的 exit() 应该是一样的,抛出SystemExit异常。一般在交互式shell中退出时使用。
在很多类型的操作系统里,exit(0) 可以中断某个程序,而其中的数字参数则用来表示程序是否是碰到错误而中断。exit(1) 表示发生了错误,而 exit(0) 则表示程序是正常退出。
yield
返回函数的中间结果,但是函数继续执行
eval()
返回表达式的结果,去掉引号
input()
无论输入什么,都返回字符串
计算
round(x,d) 四舍五入函数,d是保留小数位数,无d表示到整数位
pow(x,y) x的y次方
max(a,b,c…) 最大值
min(a,b,c…) 最小值
time
import time
time.perf_counter() 当前时间
time.ctime() 当前时间
#!/usr/bin/env python
我们经常会在别人的脚本或者项目的入口文件里看到第一行是下面这样
#!/usr/bin/python
或者这样
#!/usr/bin/env python
那么他们有什么用呢?
要理解它,得把这一行语句拆成两部分。
第一部分是 #!
第二部分是 /usr/bin/python 或者
关于 #! 这个符号,其实它是有名字的,叫做 Shebang 或者Sha-bang ,有的翻译组将它译作 释伴,即“解释伴随行”的简称,同时又是Shebang的音译。
Shebang通常出现在类Unix系统的脚本中第一行,作为前两个字符。在Shebang之后,可以有一个或数个空白字符,后接解释器的绝对路径,用于指明执行这个脚本文件的解释器。
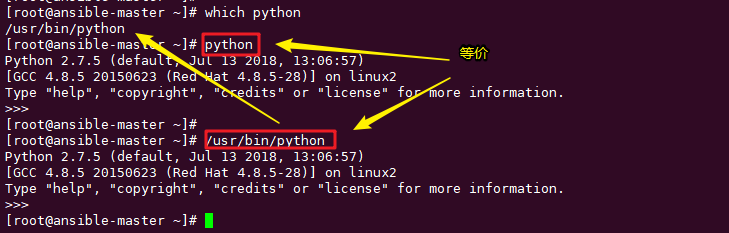
那么加和不加有什么区别呢?
如果不加 #! 的话,你每次执行这个脚本时,都得这样 python xx.py ,
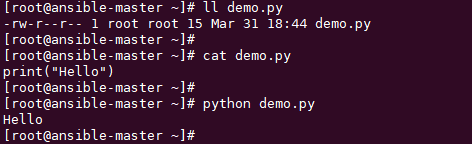
有没有一种方式?可以省去每次都加 python 呢?
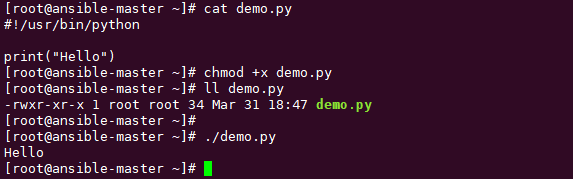
当然有,你可以文件头里加上#!/usr/bin/python ,那么当这个文件有可执行权限 时,只直接写这个脚本文件,就像下面这样。
明白了这个后,再来看看 #!/usr/bin/env python 这个 又是什么意思 ?
当我执行 env python 时,自动进入了 python console 的模式。
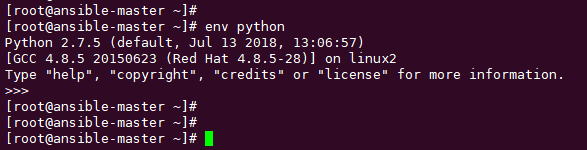
这是为什么?和 直接执行 python 好像没什么区别呀
当你执行 env python 时,它其实会去 env | grep PATH 里(也就是 /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin )这几个路径里去依次查找名为python的可执行文件。
找到一个就直接执行,上面我们的 python 路径是在 /usr/bin/python 里,在 PATH 列表里倒数第二个目录下,所以当我在 /usr/local/sbin 下创建一个名字也为 python 的可执行文件时,就会执行 /usr/bin/python 了。
具体演示过程,你可以看下面。
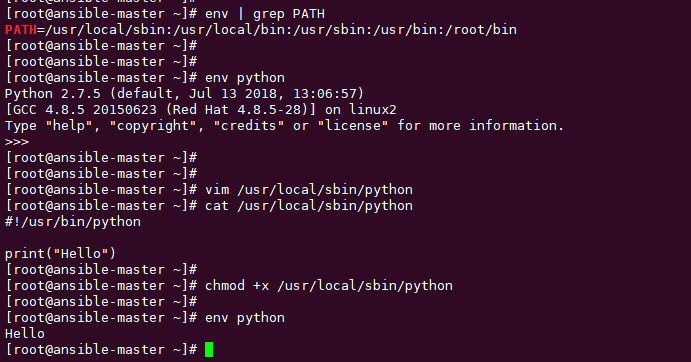
那么对于这两者,我们应该使用哪个呢?
个人感觉应该优先使用 #!/usr/bin/env python,因为不是所有的机器的 python 解释器都是 /usr/bin/python 。
#!/usr/bin/env python这个是给Linux用的,不是给Python解释器(或者你说的“编译器”)用的,它代表如果这个文件当作一个可执行文件来执行的时候,要调用哪个脚本引擎,像一般Shell脚本就会写#!/bin/bash之类。如果直接用python执行,是不需要的。对Python来说这就是一行注释。
当Linux执行一个文件的时候,如果发现它是这样的格式,就会把!后面的内容提取出来拼在你的脚本文件或路径之前,当作实际执行的命令,对你这个脚本来说就是
/usr/bin/env python ./myscript.py
它代表调用/usr/bin/env,将后面两个值作为参数。env是个Linux命令,它会按照当前环境变量设置(主要是PATH变量),查找名为python的可执行文件,然后用后面的参数启动这个可执行文件,这就避免了将python写死到固定位置,导致python安装到其他可选位置(如/usr/local/bin/)下时脚本不可用的问题。
解决找不到python问题
vim file
:set ff=unix
:wq
编码格式问题
# -- coding: UTF-8 --
或者
#coding=utf-8
**(注:此语句一定要添加在源代码的第一行)
python os模块 常用命令
-
os.name——判断现在正在实用的平台,Windows 返回 ‘nt’; Linux 返回’posix’
-
os.getcwd()——得到当前工作的目录。
-
os.listdir(path)——指定所有目录下所有的文件和目录名。
-
os.remove(path)——删除path指定的文件
-
os.rmdir(path)——删除path指定的目录
-
os.mkdir(path)——创建path指定的目录,注意:这样只能建立一层,要想递归建立可用:os.makedirs()
-
os.path.isfile(path)——判断指定对象是否为文件。是返回True,否则False
-
os.path.isdir(path)——判断指定对象是否为目录。是True,否则False。
-
os.path.exists(path)——检验指定的对象是否存在。是True,否则False.
-
os.path.split(path)——返回路径的目录和文件名,即将目录和文件名分开,而不是一个整体。此处只是把前后两部分分开而已。就是找最后一个’/'。
-
os.system(cmd)——执行shell命令。返回值是脚本的退出状态码,0代表成功,1代表不成功,例:

-
os.chdir(path)——'change dir’改变目录到指定目录
-
os.path.getsize()——获得文件的大小,如果为目录,返回0
-
os.path.abspath()——获得绝对路径
-
os.path.join(path, name)—连接目录和文件名
-
os.path.basename(path)——返回文件名
-
os.path.dirname(path)——返回文件路径
python中os.walk的用法详解
python中os.walk是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
1.载入
要使用os.walk,首先要载入该函数
可以使用以下两种方法
- import os
- from os import walk
2.使用
os.walk的函数声明为:
walk(top, topdown=True, οnerrοr=None, followlinks=False)
参数
- top 是你所要便利的目录的地址
- topdown 为真,则优先遍历top目录,否则优先遍历top的子目录(默认为开启)
- onerror 需要一个 callable 对象,当walk需要异常时,会调用
- followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们需要不断的遍历它,来获得所有的内容。
每次遍历的对象都是返回的是一个三元组(root,dirs,files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
如果topdown 参数为真,walk 会遍历top文件夹,与top文件夹中每一个子目录。
把一个变量放到字符串里
a = input("输入world\n")
f"hellow (a)"
字符串前加 u
例:u"我是含有中文字符组成的字符串。"
作用:
后面字符串以 Unicode 格式进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
字符串前加 r
例:r"\n\n\n\n” # 表示一个普通的字符串 \n\n\n\n,而不表示换行了。
作用:
去掉反斜杠的转义机制。
(特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。 )
应用:
常用于正则表达式,对应着re模块。
字符串前加 b
例: response = b’
Hello World!
’ # b’ ’ 表示这是一个 bytes 对象作用:
b" "前缀表示:后面字符串是bytes 类型。
用处:
网络编程中,服务器和浏览器只认bytes 类型数据。
如:send 函数的参数和 recv 函数的返回值都是 bytes 类型
附:
在 Python3 中,bytes 和 str 的互相转换方式是
str.encode('utf-8')
bytes.decode('utf-8')
py2app打包
pip3 install py2apppy2applet --make-setup MyApplication.pypython3 setup.py py2app

















 46万+
46万+




 到【灌水乐园】发言
到【灌水乐园】发言







