




 本文详细介绍了Redis List类型的基本用法,包括添加、删除、索引访问、长度获取、修剪等操作,同时深入剖析了其3.0链表和3.0之后quicklist的底层结构,优缺点及应用场景。
本文详细介绍了Redis List类型的基本用法,包括添加、删除、索引访问、长度获取、修剪等操作,同时深入剖析了其3.0链表和3.0之后quicklist的底层结构,优缺点及应用场景。
其他几种数据类型:
【String类型使用及底层结构】
【hash类型使用及底层结构】
【set类型使用及底层结构】
【Zset类型使用及底层结构】
一、基本用法
List,也就是列表,其中的元素可以重复。
- 所有的list命令都是用l开头的
##添加元素 lpush rpush
127.0.0.1:6379> lpush list one two three #将一个值或者多个值,插入到列表头部(左)
(integer) 3
127.0.0.1:6379> lrange list 0 -1 #通过区间获取list中的值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> rpush list four #将一个值或者多个值,插入到列表尾部(右)
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "four"
##删除元素 lpop rpop
127.0.0.1:6379> lpop list #从左边弹出元素
"three"
127.0.0.1:6379> rpop list #从右边弹出元素
"four"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
##通过下标获取list中的值 linde
127.0.0.1:6379> lindex list 1 #获取下标为1的值
"one"
##返回列表长度 llen
127.0.0.1:6379> llen list
(integer) 2
##移除指定的值 lrem
127.0.0.1:6379> lrange list 0 -1
1) "four"
2) "three"
3) "one"
127.0.0.1:6379> lrem list 1 one
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "four"
2) "three"
##修剪 ltrim
127.0.0.1:6379> lpush list1 hello hello1 hello2 hello3
(integer) 4
127.0.0.1:6379> ltrim list1 1 2 #只保留list1中区间1-2的数据,list1已经改变
OK
127.0.0.1:6379> lrange list1 0 -1
1) "hello2"
2) "hello1"
##先移除一个元素后把移除的元素添加到别的list rpoplpush
127.0.0.1:6379> lrange list1 0 -1
1) "hello4"
2) "hello3"
3) "hello2"
4) "hello1"
127.0.0.1:6379> rpoplpush list1 list2 #弹出list1右边第一个元素,把该元素push进list2
"hello1"
127.0.0.1:6379> lrange list1 0 -1
1) "hello4"
2) "hello3"
3) "hello2"
127.0.0.1:6379> lrange list2 0 -1
1) "hello1"
127.0.0.1:6379>
##设置对应下标的值 lset
127.0.0.1:6379> lrange list2 0 -1
1) "hello1"
127.0.0.1:6379> lset list2 0 hello
OK
127.0.0.1:6379> lrange list2 0 -1
1) "hello"
127.0.0.1:6379> lset list2 1 hi #不能对不存在的key进行设置
(error) ERR index out of range
127.0.0.1:6379>
#往某一个元素前面/后面插入值 linsert list before/after
127.0.0.1:6379> lrange list2 0 -1
1) "hello"
127.0.0.1:6379> linsert list2 after hello world #往hello元素的后面插入world值
(integer) 2
127.0.0.1:6379> lrange list2 0 -1
1) "hello"
2) "world"
127.0.0.1:6379>
二、底层结构
在redis3.0中,List的底层是通过双向链表和压缩列表来实现的,但是由于C 语言本身没有链表这个数据结构的,所以 Redis 自己设计了一个链表数据结构。在3.0之后,List是通过quicklist来实现的。(由于hash类型中也用到了压缩列表,所以压缩列表放到那一章中)
1.结构设计(3.0链表)
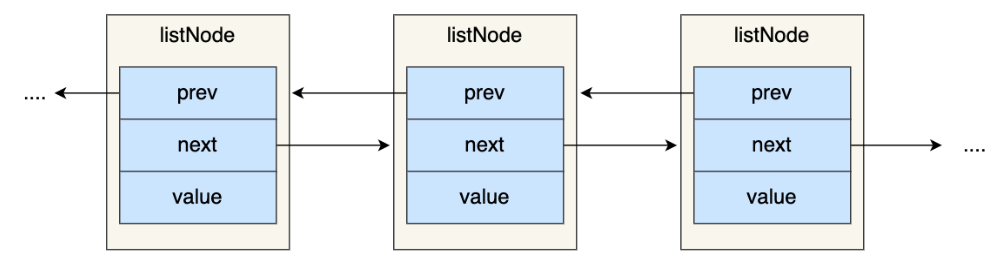
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
因为有前置节点和后置节点,所以可以看出这是一个双向链表。不过,Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,这样操作起来会更方便。
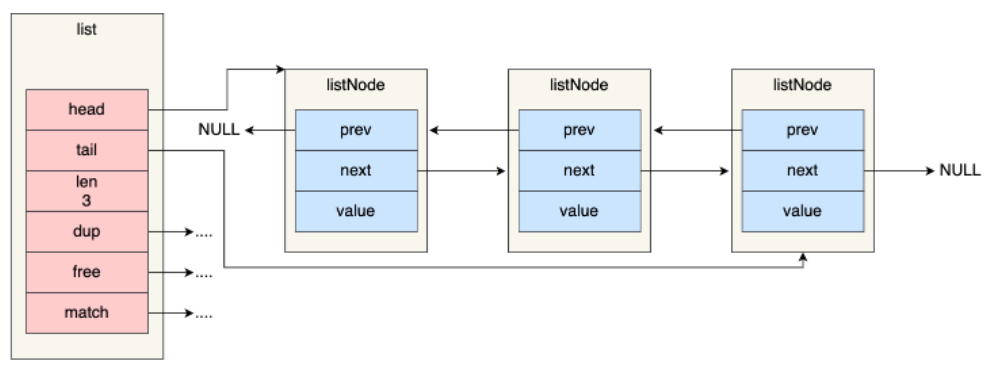
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
list中提供了链表的头节点、尾节点、链表数量以及一些可以自定义实现的函数。加了list之后的结构是这样的。
2.结构优缺点
优点:
-
获取一个节点的前置节点、后置节点,以及获取链表的头节点和尾节点的时间复杂度都是O(1)。
-
获取链表长度的时间复杂度是O(1)。
-
listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值
缺点:
- 链表节点之间的内存是不连续的,所以无法很好利用 CPU 缓存。
- 当数据比较少时,比如只有一个节点,也需要一个链表节点结构头(list)的分配,内存开销较大。因此,List 对象在数据量比较少的情况下,会采用压缩列表作为底层数据结构的实现。
3.结构设计(3.0之后quicklist)
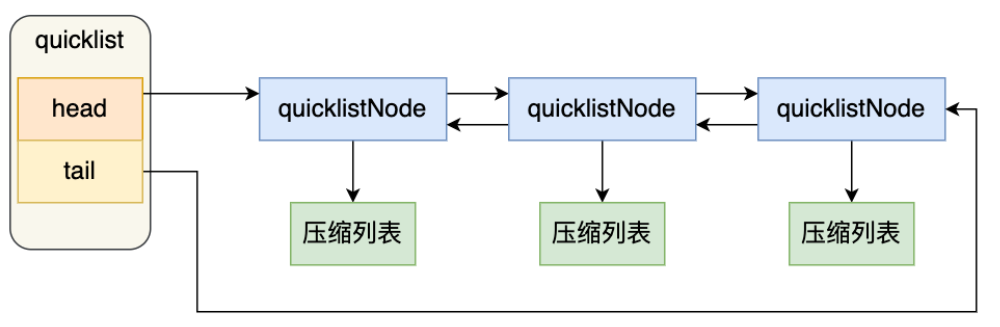
quicklist 的结构体跟链表的结构体类似,都包含了表头和表尾,区别在于 quicklist 的节点是 quicklistNode。
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head; //quicklist的链表头
//quicklist的链表头
quicklistNode *tail;
//所有压缩列表中的总元素个数
unsigned long count;
//quicklistNodes的个数
unsigned long len;
...
} quicklist;
quicklistNode 的结构定义:
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev; //前一个quicklistNode
//下一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
//quicklistNode指向的压缩列表
unsigned char *zl;
//压缩列表的的字节大小
unsigned int sz;
//压缩列表的元素个数
unsigned int count : 16; //ziplist中的元素个数
....
} quicklistNode;
在quicklistNode中,链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 zl。
在向 quicklist 添加一个元素的时候,不会像普通的链表那样直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
参考
[小林coding]
[redis设计与实现]

















 4603
4603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









