










 本文提供了MySQL性能优化的全面指南,包括存储引擎选择、字段优化、索引优化、SQL语句优化等多个方面,还介绍了锁、死锁和事务控制优化的方法,并分享了线上慢SQL优化的实际案例。
本文提供了MySQL性能优化的全面指南,包括存储引擎选择、字段优化、索引优化、SQL语句优化等多个方面,还介绍了锁、死锁和事务控制优化的方法,并分享了线上慢SQL优化的实际案例。
目录
- MySQL 存储引擎选择
- 字段类优化
- 索引优化
- SQL优化
- 锁,死锁和事务控制优化
- MySQL 开发规范
- 应用层优化
- 高可用架构方案优化
1 存储引擎(表类型)选择
存储引擎就是指表的类型,数据库的存储引擎决定了表在计算机中的存储方式。
MySQL常见的存储引擎:
• InnoDB
• MyISAM
• MEMORY
• MERGE
• NDB
2 字段优化
如何优化表大小?
•表设计:
减少磁盘空间
降低I/O
降低内存
•表列:
使用最小数据类型
尽量避免null,如果可能声明列为not null
•索引:
表的主键应尽可能短
减数据量
提高查询速度
•标准化:
尽量保持所有数据非冗余(适度范式和反范式)
示例1:
CREATE TABLE `appgrp_0101` (
`id` bigint(10) NOT NULL AUTO_INCREMENT,
`accountid` int(10) NOT NULL,
`cpcgrpid` bigint(10) NOT NULL,
`appid` bigint(10) NOT NULL,
`ispause` smallint(2) NOT NULL DEFAULT '0' COMMENT 'xxxxxxx',
`os_type` smallint(2) NOT NULL DEFAULT '0' COMMENT '0:android, 1: ios',
……
`style_type` smallint(2) NOT NULL DEFAULT '1' COMMENT 'xxxxxxxx',
PRIMARY KEY (`id`),
………示例2:
CREATE TABLE `xxxxxxxx_xxxxxx_0101` (
`keyid` bigint(10) NOT NULL COMMENT 'xxxxx',
`ideaid` int(10) NOT NULL COMMENT 'xxxxx',
`audittype` smallint(2) NOT NULL COMMENT 'xxxxxxx……..
`refusecode` varchar(30) DEFAULT NULL COMMENT 'xxxxx,',
`gmod` smallint(2) NOT NULL COMMENT 'xxxxxx',
`optype` smallint(2) NOT NULL COMMENT 'xxxxxxxxxx',
PRIMARY KEY (`keyid`,`ideaid`,`audittype`),
KEY `ix_gmod_cs` (`gmod`,`checkstatus`),
KEY `ix_iid` (`ideaid`),
KEY `ix_aid_cs_kp_ip` (`accountid`,`checkstatus`,`keypass`,`ideapass`)
) ENGINE=InnoDBDEFAULT CHARSET=utf8 COMMENT='xxxxxxxxxx'数值字段类型
三类数值类型:
TINYINT(1Byte)
SMALLINT(2B)
MEDIUMINT(3B)
INT(4B)、BIGINT(8B)
FLOAT(4B)、DOUBLE(8B)
DECIMAL(M,D)
BADCASE:
INT(1)VSINT(11)
DECIMAL(18,0)
举例:11位手机号码,最好用什么数据类型存储?
INT 、UNSIGNED INT
BIGINT、UNSIGNED BIGINT
VARCHAR(11) 、CHAR(11)
日期和时间类型
日期时间类型:
Date(3Byte)
DateTime(8Byte)
Time(3Byte)
Timestamp(4Byte)
Year (1Byte)
对于timestamp,5.5版本以前一个表只允许一个字段拥有自动插入时间和自动更新时间,5.6版本以后可以多个。MYSQL5.7中多个timestamp中的第一个会被强制转换成自动更新
字符串类型
字符串类型:
Char 固定长度
Varchar可变长度
BADCASE:
Varchar(32)中32 ?
Varchar(255) vs varchar(256)
varchar(5)VS varchar(500)
TEXT/BLOB类型
TEXT类型处理性能远低于VARCHAR
强制生成硬盘临时表
浪费更多空间
VARCHAR(65535)==>64K(注意UTF-8)
•尽量不用TEXT/BLOB数据类型
•若必须使用则拆分到单独的表
•举例:
CREATETABLEt1(
idINTNOTNULLAUTO_INCREMENT,
datatextNOTNULL,
PRIMARYKEY(id)
)ENGINE=InnoDB;将字符转化为数字
将数字型VS字符串型索引
更高效
查询更快
占用空间更小
•举例:用无符号INT存储IP,而非CHAR(15)
INTUNSIGNED
INET_ATON()
INET_NTOA()字符转化为数字
避免使用NULL字段
避免使用NULL字段
很难进行查询优化
NULL列加索引,需要额外空间
含NULL复合索引无效
•举例
`a`char(32)DEFAULTNULL
`b` int(10)NOTNULL
`c` int(10)NOTNULLDEFAULT03 索引优化
谨慎合理添加索引
•谨慎合理添加索引
改善查询
减慢更新
索引不是赹多赹好
•能不加的索引尽量不加
综合评估数据密度和数据分布
最好不超过字段数20%
•结合核心SQL优先考虑覆盖索引
•举例
不要给“性别”列创建索引
不在索引列做运算
不在索引列进行数学运算或凼数运算
无法使用索引
导致全表扫描
•举例
mysql> select * from plan_0101 where planid +1=265;
`1 row in set (0.15 sec)`
mysql> select * from plan_0101 where planid =265-1;
`1 row in set (0.00 sec)`
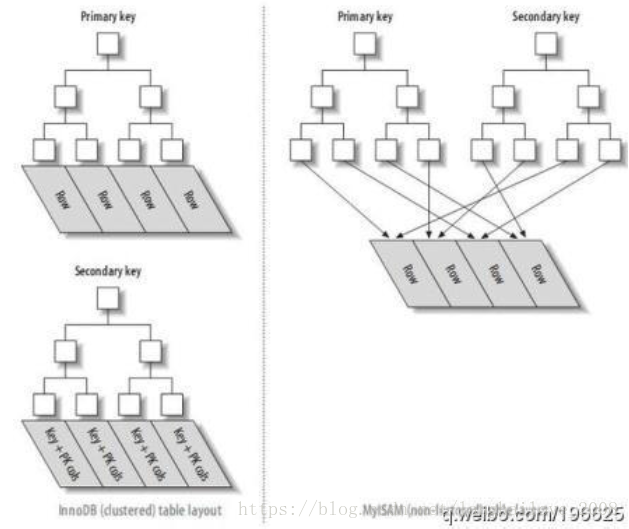
`BAD:select* fromtableWHERE to_days(current_date)–to_days(date_col)<=10GOOD:select*fromtableWHEREdate_col>=DATE_SUB('2018-03-22',INTERVAL10DAY);`自增列或全局ID做INNODB主键
•对主键建立聚簇索引
•二级索引存储主键值
•主键不应更新修改
•按自增顺序插入值
•忌用字符串做主键
•聚簇索引分裂
•推荐用独立于业务的AUTO_INCREMENT列或全局ID生成器做代理主键
•若不指定主键,InnoDB会用唯一且非空值索引代替
尽量不用外键
•线上OLTP系统
外键可节省开发量
有额外开销
逐行操作
可‘到达’其它表,意味着锁
高开发时容易死锁
•由程序保证约束
4 SQL优化
SQL语句尽可能简单
•大SQLVS多个简单SQL
传统设计思想
BUTMySQLNOT
一条SQL只能在一个CPU运算
5000+QPS的高开发中,1秒大SQL意味着?
可能一条大SQL就把整个数据库堵死
•拒绝大SQL,拆解成多条简单SQL
简单SQL缓存命中率更高
减少锁表时间,特别是MyISAM
用上多CPU尽量不用SELECT*
•用SELECT*时
•更多消耗CPU、内存、IO、网络带宽
•先向数据库请求所有列,然后丢掉不需要列
•尽量不用SELECT*,只取需要数据列
•更安全的设计:减少表变化带来的影响
•为使用coveringindex提供可能性
•Select/JOIN减少硬盘临时表生成,特别是有TEXT/BLOB时
•举例
SELECT * FROM tag WHERE id = 999184
->
SELECT keyword FROM tag WHERE id = 999184尽量不用子查询
•MySQL子查询
大部分情况优化较差
特别WHERE中使用INid的子查询
一般可用JOIN改写
•举例:
MySQL>select*fromtable1whereidin (**select id from table2**);
Mysql> SELECT table1* FROM table1 **LEFT JOIN** table2 ON table1.id = table2.id WHERE table2.id IS NULL;尽可能避免使用SP/TRIG/FUNC
•线上OLTP系统(线下库另论)
尽可能少用存储过程
尽可能少用触发器
减少使用MySQL凼数对结果进行处理
•由客户端程序负责Loaddata导入数据
•批量数据快导入:
成批装载比单行装载更快,不需要每次刷新缓存
无索引时装载比索引装载更快
Insertvalues,values,values减少索引刷新
Loaddata比insert快约20倍
•提高导入效率
数据按主键顺序排列
关闭唯一性校验和自动提交Is null优化
MySQL 可以对col_nameIS NULL执行和col_name=constant_value相同的优化。
举例,MySQL可以为IS null使用索引和范围扫描。
SELECT * FROM tbl_nameWHERE key_colIS NULL;
MySQL可以优化组合查询col_name=exprORcol_nameIS NULL,这是在解析的子查询中常见的一种形式。优化类型显示ref_or_null。
如果where条件包含col_nameIS NULL,但是col_name被定义为非空,这时,就不会优化。
优化只能处理一个IS NULL。
举例:SELECT * FROM t1, t2 WHERE (t1.a=t2.a AND t2.a IS NULL)
OR (t1.b=t2.b AND t2.b IS NULL);
MySQL仅对表达式(t1.a=t2.a AND t2.a IS NULL)使用索引查找,不能使用索引b
Not in 子查询优化
•尽量避免子查询
•更多消耗数据库资源,效率低下
•时间成本高
•使用JOIN取而代之
•举例
select * from customer where customer_idnot in ( select customer_idfrom payment);
select * from customer left join payment on customer.customer_id= payment.customer_idwhere payment.customer_idis null;同一字段改写OR为IN()
•同一字段,将or改写为in()
•OR效率:O(n)
•IN效率:O(Logn)
•当n很大时,OR会慢很多
•注意控制IN的个数,建议n小于200
•举例
Select* fromoppWHEREphone=‘12347856'or
phone=‘42242233'\G
Select* fromoppWHEREphonein('12347856','42242233')不同字段改写OR为UNION
•不同字段,将or改为union
•减少对不同字段进行"or"查询
•如果有足够信心:setglobal optimizer_switch='index_merge=off';
•举例
Select* fromoppWHEREphone='010-88886666'or cellPhone='13800138000';
Select *fromoppWHEREphone='010-88886666'union
Select* fromoppWHEREcellPhone='13800138000';避免负向查询和%前缀模糊查询
•避免负向查询
NOT、!=、<>、!<、!>、NOTEXISTS、NOTIN、NOTLIKE等
•避免%前缀模糊查询
B+Tree
使用不了索引
导致全表扫描
•举例
MySQL>select*fromtable WHEREnamelike'%lin%';
572rowsin set (3.27sec)
通过覆盖索引来优化
Mysql>select id fromtableWHEREnamelike'%lin%';COUNT()优化
•性能对比
- 不带WHERECOUNT()
- 带WHERECOUNT()
•优先使用select count(*)
- 任何情况下SELECT COUNT(*) FROM
tablename是最优选择;
- 尽量减少SELECT COUNT(*) FROM
tablenameWHERE COL =‘value‘这种查询
- 杜绝SELECT COUNT(COL) FROM tablename
WHERE COL2 = ‘value’ 的出现COUNT()的几个例子
`id`int(10)NOTNULL AUTO_INCREMENT
COMMENT'公司的id',
`sale_id`int(10)
unsignedDEFAULTNULL,•几个有趣的例子:
COUNT(COL)VSCOUNT(*)
COUNT(*)VSCOUNT(1)
COUNT(1)VSCOUNT(0)VSCOUNT(100)
•示例
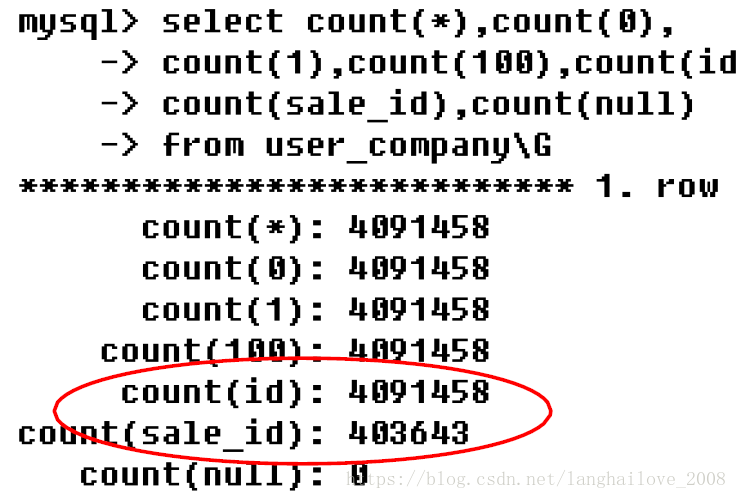
•结论
COUNT(*)=count(1)
COUNT(0)=count(1)
COUNT(1)=count(100)
COUNT(*)!=count(col)
WHY?
Count(distinct)优化
•MySql优化器不能直接的对count(distinct column)做优化,通过改写sql来达到loose index scan
原始:
Mysql>explain select count(distinct income) from bill; 全索引,重复扫描,
+—-+————-+——————————+——-+—————+—————————-+———+——+–
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——————————+——-+—————+—————————-+———+——+–
| 1 | SIMPLE | bill | index | NULL | idx_income | 156| NULL | **19546123| Using index |**
+—-+————-+——————————+——-+————–+—————————-+———+——+–
改写后:
mysql >explain select count(*) from ( select distinct(income) from bill ;
+—-+————-+——————————+——-+—————+———————————+———+—–
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——————————+——-+—————+———————————+———+—–
| 1 | SIMPLE | bill | range | NULL |idx_income | 45| NULL | **2124695| Using index for group-by |**
+—-+————-+——————————+——-+—————+———————————+———+—–GROUP BY去除排序
•GROUPBY实现
分组
自动排序
•无需排序:OrderbyNULL
•特定排序:GroupbyDESC/ASC
•举例
MySQL> select phone,count(*) from post group by phone limit 1;
1rowinset(**2.19sec**)
MySQL> select phone,count(*) from post group by phone order by null limit 1;
1rowinset(**2.02sec**)Order by 、GROUP BY优化
减少Using filiesort使用index排序,遵循最左前缀原则
多个字段排序,顺序要一致
•举例

LIMIT分页优化
•传统分页:
Select* fromtablelimitorder by id 10000,10;
•LIMIT原理:
Limit10000,10
偏移量越大则越慢
•<100页基本分页方式,>100页子查询分页方式
•分页方式一:
Select*fromtableWHEREid>=10000 order by idlimit10;
•分页方式二:
SELECT*FROMtableINNERJOIN(SELECTidFROMtableLIMIT10000,10)USING(id);用UNIONALL而非UNION
•若无需对结果进行去重,则用UNIONALL
UNION有去重开销
•举例
MySQL>SELECT* FROMdetail20091128UNIONALL SELECT* FROMdetail20110427UNIONALL SELECT* FROMdetail20110426UNIONALLSELECT* FROMdetail20110425UNIONALL SELECT* FROMdetail20110424UNIONALL SELECT* FROM detail20110423;同数据类型的列值比较
•原则:数字对数字,字符对字符
•数值列与字符类型比较
同时转换为双精度
进行比对
•字符列与数值类型比较
字符列整列转数值
不会使用索引查询
•举例:字符列与数值类型比较
字段:`remark` varchar(50)NOTNULLCOMMENT'备注,
默认为空',
MySQL>SELECT`id`, `gift_code`FROMgift WHERE
`deal_id`= 640ANDremark=115127;
1 row in set(0.14 sec)
MySQL>SELECT`id`, `gift_code`FROMpool_giftWHERE
`deal_id`= 640ANDremark='115127';
1 row in set(0.005 sec)打散批量更新
•大批量更新凌晨操作,避开高峰
•凌晨不限制
•白天上限默认为100条/秒(特殊除外)
•举例:
updatepostsettag=1WHEREsleep 0.01;
idin(1,2,3);
updatepostset tag=1WHEREid in(4,5,6);
sleep 0.01;
……SQL常用优化工具
SHOWPROFILE
MySQLsla
MySQLdumpslow
EXPLAIN
ShowSlowLog
ShowProcesslist
SHOWQUERY_RESPONSE_TIME(Percona)
trace
线上慢SQL优化示例1
1.现象:观察旭日审核慢日志,发现如下语句很多:
select m.mid, m.cid, m.msgtype, m.grpid, m.accountid, a.agentidas
agentidfrom audit_msgm, account_infoa where m.accountid=
a.accountidand m.handled= 0
order by m.grpid, m.create_datelimit 10000\G
2.解决:
优化前
ix_han_cre` (`HANDLED`,`CREATE_DATE`)
优化后:ix_han_grp_cre` (`HANDLED`,`GRPID`,`CREATE_DATE`)
查询响应时间提升10倍,执行时间由1.5秒提升到0.2秒。线上慢SQL优化示例2
select tmp.cust_id, tc.agent_id, tc.second_agent_id, tmp.hour, tmp.xr_pay, tmp.xr_pc_pay, tmp.xr_mo_pay…….., tmp.big_cpc_payfrom
(select t.cust_id, t.hour, sum(t.xr_pay) xr_pay, sum(t.xr_pc_pay) xr_pc_pay, sum(t.xr_mo_pay) xr_mo_pay, sum(t.device_xr_pc_pay) device_xr_pc_pay, sum(t.device_xr_mo_pay) device_xr_mo_pay, sum(t.cx_pay) ………+ sum(t.hy_pay) big_yh_pay, sum(t.xr_pay)+sum(t.cx_pay) + sum(t.yh_pay)+ sum(t.hy_pay) big_cpc_payfrom
( SELECT xr.cust_id, xr.hour, SUM(xr.xr_pay) xr_pay, SUM(xr.xr_pc_pay) xr_pc_pay, SUM(xr.xr_mo_pay) xr_mo_pay, SUM(xr.device_xr_pc_pay) device_xr_pc_pay, SUM(xr.device_xr_mo_pay) device_xr_mo_pay, 0 cx_pay, 0 yh_pay, 0 hy_payfrom tmp_cost_xr_realtimexrwhere xr.date= 20180423 GROUP BY cust_id,hourUNION ALL SELECT cx.cust_id, cx.hour, 0 xr_pay, 0 xr_pc_pay, 0 xr_mo_pay, 0 device_xr_pc_pay, 0 device_xr_mo_pay, SUM(cx.cx_pay)cx_pay, 0 yh_pay, 0 hy_payfrom tmp_cost_cx_realtimecx where cx.date= 20180423 GROUP BY cust_id,hourUNION ALL SELECT yh.cust_id, yh.hour, 0 xr_pay, 0 xr_pc_pay, 0 xr_mo_pay, 0 device_xr_pc_pay, 0 device_xr_mo_pay, 0 cx_pay, SUM(yh_pay) yh_pay, 0 hy_payfrom tmp_cost_yh_realtimeyhwhere yh.date= 20180423 GROUP BY cust_id,hourUNION ALL SELECT hy.cust_id, hy.hour, 0 xr_pay, 0 xr_pc_pay, 0 xr_mo_pay, 0 device_xr_pc_pay, 0 device_xr_mo_pay, 0 cx_pay, 0 yh_pay, SUM(hy_pay) hy_payfrom tmp_cost_hy_realtimehywhere hy.date= 20180423 GROUP BY cust_id,hour)t GROUP BY cust_id,hour) tmpjoin tmp_realtime_cust_relationtcon tmp.cust_id=tc.cust_id;1、现象:该查询每日执行144次,平均执行时间35s
2、分析:
mysql> show create table tmp_cost_xr_realtime\G
*************************** 1. row ***************************
Table: tmp_cost_xr_realtime
Create Table: CREATE TABLE `tmp_cost_xr_realtime` (
`pk` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '单调自增主键ID',
`date` date NOT NULL COMMENT '计费日期',
`hour` int(11) NOT NULL COMMENT '计费小时',
`cust_id` int(11) NOT NULL COMMENT '账户ID',
`xr_pay` bigint(20) NOT NULL COMMENT '消耗',
`xr_pc_pay` bigint(20) DEFAULT NULL COMMENT 'pc消耗',
`xr_mo_pay` bigint(20) DEFAULT NULL COMMENT '无线消耗',
`device_xr_pc_pay` bigint(20) DEFAULT NULL COMMENT '旭日计算机消耗',
`device_xr_mo_pay` bigint(20) DEFAULT NULL COMMENT '旭日移动端消耗',
`t_minute` int(11) DEFAULT NULL,PRIMARY KEY (`pk`)
) ENGINE=InnoDBAUTO_INCREMENT=8355082361 DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='xr实时消耗临时表'
1 row in set (0.00 sec)
mysql> SELECT count(*) from tmp_cost_xr_realtime;
+----------+
| count(*) |
+----------+
| 3641957 |
+----------+3、优化方法
为每一个union all中的表添加索引alter table tmp_cost_xr_realtimeadd key(date,cust_id,HOUR,xr_pay,xr_pc_pay,xr_mo_pay,device_xr_pc_pay,device_xr_mo_pay);alter table tmp_cost_cx_realtimeadd key(date,cust_id,HOUR,cx_pay);alter table tmp_cost_yh_realtimeadd key(date,cust_id,HOUR,yh_pay);alter table tmp_cost_hy_realtimeadd key(date,cust_id,HOUR,hy_pay);4、优化效果
优化后执行时间6.5s
线上慢SQL优化示例3
SELECT
c.cust_idcustId,
ct.agent_user_iduserId,
0 custType,
0 followType
FROM
p_cust_communicationc
JOIN (
SELECT
max(cc.id) id
FROM
p_cust_communicationcc
GROUP BY
cc.cust_id
) t ON c.id = t.id
JOIN p_cust_tempctON c.cust_id= ct.cust_id
AND c.op_user_id= ct.agent_user_id
WHERE
c.next_follow_date= '20171122'
AND c.next_follow_plan= 1
GROUP BY
c.cust_id1、分析
CREATE TABLE `p_cust_communication` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增Id',
`cust_id` bigint(20) NOT NULL COMMENT '售前客户id',
`agent_id` int(10) NOT NULL COMMENT '代理商id',
`agent_user_id` int(10) DEFAULT NULL COMMENT '跟进记录提交人(-1为系统管理员,0为公路计划传过来的用户登录名出错)',
`contacter_name` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '联系人姓名',
`contacter_job` tinyint(4) DEFAULT NULL COMMENT '联系人角色',
`contacter_id` int(11) DEFAULT NULL COMMENT '联系人id(-2为选其他时候的id)',
`follow_type` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '跟进方式(逗号分隔)',
`other_type` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '其他跟进方式',
`next_follow_date` date DEFAULT NULL COMMENT '下一步跟进日期',
`next_follow_content` varchar(1024) COLLATE utf8_bin DEFAULT NULL COMMENT '下一步跟进内容',
`abandon_reason` varchar(1024) COLLATE utf8_bin DEFAULT NULL COMMENT '放弃原因',
`interest_degree_before` tinyint(4) DEFAULT NULL COMMENT '跟进前意向程度(1-V类;2-W类;3-A类;4-B类;5-C类;6-D类)',
`op_user_id` int(11) DEFAULT NULL COMMENT '所属销售user id',
`follow_up_status` tinyint(4) DEFAULT NULL COMMENT '跟进阶段',
PRIMARY KEY (`id`),
KEY `Index_custId_agentId` (`cust_id`,`agent_id`),
KEY `idx_pccomt_nfdate` (`next_follow_date`,`next_follow_plan`),
KEY `idx_pccomt_cid_fr` (`cust_id`,`follow_result`(255))
) ENGINE=InnoDB AUTO_INCREMENT=3865134 DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='售前客户沟通记录表’2、问题
已经存在一个相对合适的索引,但是SQL逻辑做了很多无用的join,即select max(id)中有很多数据是无效的,因为只需要获取某一天的值。
3、优化方法
将时间限制添加到join里面
SELECT max(cc.id) id FROM p_cust_communication cc where cc.next_follow_date = '20171122’ GROUP BY cc.cust_id4、结果
执行时间从6s降至0.5s
线上慢SQL优化示例4
场景:
品牌brandstart库开发环境为MySQL5.7 1.35s ,测试环境为MySQL5.5 108s
SELECT o.`order_number` orderNumber, u.`unit_name` unitName,
o.`account_name` accountName, k.`keyword_value` keywordValue, SUM(sk.`pv`) pv, SUM(sk.`click`) click, o.`pz_type` pzType
FROM `t_pz_stat_keyword` sk,`t_pz_order` o,
(SELECT * FROM `t_pz_unit_keyword`
UNION ALL
SELECT * FROM `t_pz_unit_keyword_deleted`
) k,
(SELECT unit_id, unit_name, account_id, order_id FROM `t_pz_unit_child` WHERE account_id = 18615909
UNION ALL
SELECT unit_id, unit_name, account_id, order_id FROM `t_pz_unit_child_deleted` WHERE account_id =18615909
) u
WHERE sk.account_id = 18615909
AND sk.channel_type=4
AND sk.stat_date <= '2018-05-21' AND sk.stat_date >= '2018-04-01'
AND sk.`unit_id`= u.`unit_id` AND o.`order_id` = u.`order_id` AND sk.`keyword_id` = k.`keyword_id`
GROUP BY u.`unit_id`, sk.`keyword_id`
ORDER BY o.`order_number`, u.unit_id, k.`keyword_value`;该SQL在开发环境执行时间1.35s,在测试环境执行108s
优化步骤
1、添加索引
t_pz_stat_keyword这个表加个索引(account_id,channel_type,stat_date)
t_pz_unit_child和t_pz_unit_child_deleted这两个表添加account_id索引2、修改SQL
将join连接放到union all里面避免无用数据的关联
SELECT o.`order_number` orderNumber, u.`unit_name` unitName,
o.`account_name` accountName, sk.`keyword_value` keywordValue,
SUM(sk.`pv`) pv, SUM(sk.`click`) click,
o.`pz_type` pzType
FROM `t_pz_order` o,
(SELECT a.keyword_value,a.`order_id`,b.* FROM `t_pz_unit_keyword` a,`t_pz_stat_keyword` b WHERE a.keyword_id=b.`keyword_id` AND b.account_id = 18615909 AND b.channel_type=4 AND b.stat_date <= '2018-05-21' AND b.stat_date >= '2018-04-01'
UNION ALL
SELECT a.keyword_value,a.`order_id`,b.* FROM `t_pz_unit_keyword_deleted` a,`t_pz_stat_keyword` b WHERE a.keyword_id=b.`keyword_id` AND b.account_id = 18615909 AND b.channel_type=4 AND b.stat_date <= '2018-05-21' AND b.stat_date >= '2018-04-01'
) sk,
(SELECT unit_id, unit_name, account_id, order_id FROM `t_pz_unit_child` WHERE account_id = 18615909
UNION ALL
SELECT unit_id, unit_name, account_id, order_id FROM `t_pz_unit_child_deleted` WHERE account_id =18615909
) u
WHERE
sk.`unit_id`= u.`unit_id` AND o.`order_id` = u.`order_id`
GROUP BY u.`unit_id`, sk.`keyword_id`
ORDER BY o.`order_number`, u.unit_id, sk.`keyword_value`;同理,可以把o表和u表合并
SELECT u.`order_number` orderNumber, u.`unit_name` unitName,
u.`account_name` accountName, sk.`keyword_value` keywordValue,
SUM(sk.`pv`) pv, SUM(sk.`click`) click,
u.`pz_type` pzType
FROM
(SELECT a.keyword_value,a.`order_id`,b.* FROM `t_pz_unit_keyword` a,`t_pz_stat_keyword` b WHERE a.keyword_id=b.`keyword_id` AND b.account_id = 18615909 AND b.channel_type=4 AND b.stat_date <= '2018-05-21' AND b.stat_date >= '2018-04-01'
UNION ALL
SELECT a.keyword_value,a.`order_id`,b.* FROM `t_pz_unit_keyword_deleted` a,`t_pz_stat_keyword` b WHERE a.keyword_id=b.`keyword_id` AND b.account_id = 18615909 AND b.channel_type=4 AND b.stat_date <= '2018-05-21' AND b.stat_date >= '2018-04-01'
) sk,
(SELECT c.unit_id, c.unit_name, c.account_id, c.order_id,d.order_number,d.account_name,d.pz_type FROM `t_pz_unit_child` c,t_pz_order d WHERE c.order_id=d.order_id and c.account_id = 18615909
UNION ALL
SELECT c.unit_id, c.unit_name, c.account_id, c.order_id,d.order_number,d.account_name,d.pz_type FROM `t_pz_unit_child_deleted` c,t_pz_order d WHERE c.order_id=d.order_id and c.account_id =18615909
) u
WHERE
sk.`unit_id`= u.`unit_id`
GROUP BY u.`unit_id`, sk.`keyword_id`
ORDER BY u.`order_number`, u.unit_id, sk.`keyword_value`;这两条SQL执行时间一样,因为u表里面数据较少,看不出差异
优化后执行时间0.01s
5 锁、死锁、事务控制优化
Mysql事务及隔离级别
•事务的概念
原子性一致性
隔离性持久性
•MySQL的事务隔离级别
ロread uncommitted :未提交读,允许脏读,但不允许丢数据。最低级别
ロread committed : 读提交(oracle默认)不允许脏读,允许不可重复
读取。语句级。
ロrepeatable read :可重复读(mysql默认),禁止不可重复读和脏读,但
有时可能出现幻影数据。事务级。
ロserializble:可序列化,提供严格的事务隔离,最高级别,事务级
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序来说,可以优先考虑把数据库系统的隔离级别设置为read committed.它能够避免脏读取,也有较好的并发性能。
Mysql锁及特性
■表级锁:
开销小,加锁快;不会出现死锁;锁粒度大,发生冲
突的概率最高,并发度最低。MyISAM属于这类型。
■行级锁:
开销大,加锁慢,会出现死锁,锁粒度最小,发生冲
突的概率最低,并发度也最高。InnoDB属于这类型。
■页面锁:
开销和加锁时间界于表锁和行锁之间,会出现死锁;
锁粒度界于表锁和行锁之间,并发度一般.NDB属于这
类型。
获取InnoDB行锁争用情况
可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况:
mysql>show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name| Value |
+-------------------------------+-------+
| InnoDB_row_lock_current_waits| 0|
| InnoDB_row_lock_time| 0|
| InnoDB_row_lock_time_avg| 0|
| InnoDB_row_lock_time_max| 0|
| InnoDB_row_lock_waits| 0|
+-------------------------------+-------+
5 rows in set (0.01 sec)Innodb行锁模式及加锁方法
InnoDB实现了以下两种类型的行锁:
■共享锁(S):允许一个事务去读一行,阻止其他事务获得相同
数据集的排他锁。
■排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务
取得相同数据集的共享读锁和排他写锁。
两种内部意向锁(Intention Locks):
■意向共享锁(IS):事务打算给数据行加行共享锁,事务在给
一个数据行加共享锁前必须先取得该表的IS锁。
■意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一
个数据行加排他锁前必须先取得该表的IX锁。
事务可以通过以下语句显示给记录集加共享锁或排他锁:
共享锁(S):SELECT * FROM table_nameWHERE … LOCK IN SHARE MODE。
排他锁(X):SELECT * FROM table_nameWHERE … FOR UPDATE。
用SELECT … IN SHARE MODE获得共享锁,主要用在需要数据依存关系时来确认某行记录是否存在,并确保没有人对这个记录进行UPDATE或者DELETE操作。但是如果当前事务也需要对该记录进行更新操作,则很有可能造成死锁,对于锁定行记录后需要进行更新操作的应用,应该使用SELECT… FOR UPDATE方式获得排他锁。
InnoDB存储引擎的共享锁示例

InnoDB存储引擎的排他锁示例

Innodb行锁实现方式
InnoDB行锁通过给索引上索引项加锁来实现。没有索引,通过隐藏的聚簇索引来对记录加锁。
InnoDB行锁三种情形:
■Record lock: 对索引项加锁
■Gap lock: 对索引之间的“间隙”,第一条
记录之前的“间隙”或最后一条记
录后的“间隙”加锁。
■Next-key lock: 前两种的组合,对记录及其前
面的间隙加锁。
实现特点:不通过索引检索数据,对表所有记录加锁,和表锁一样。
InnoDB表在不使用索引时表锁例子
在不通过索引条件查询的时候,InnoDB确实使用的是表锁,而不是行锁。
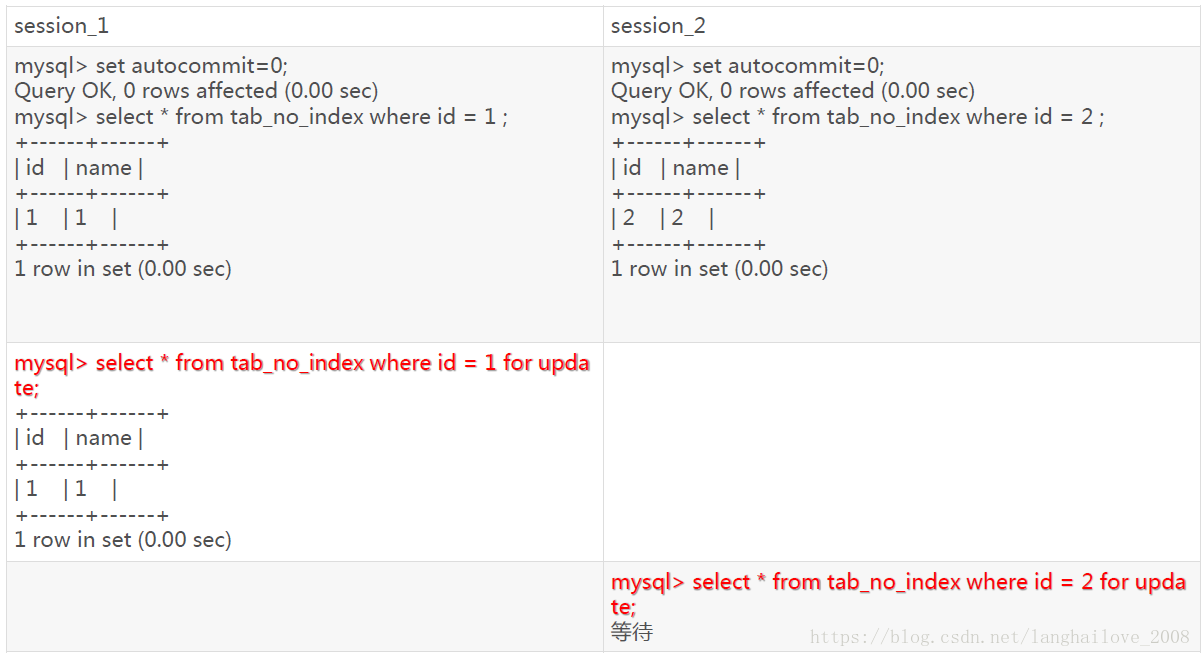
InnoDB使用相同索引键的阻塞示例
行锁是针对索引加的锁,不是针对记录加的锁
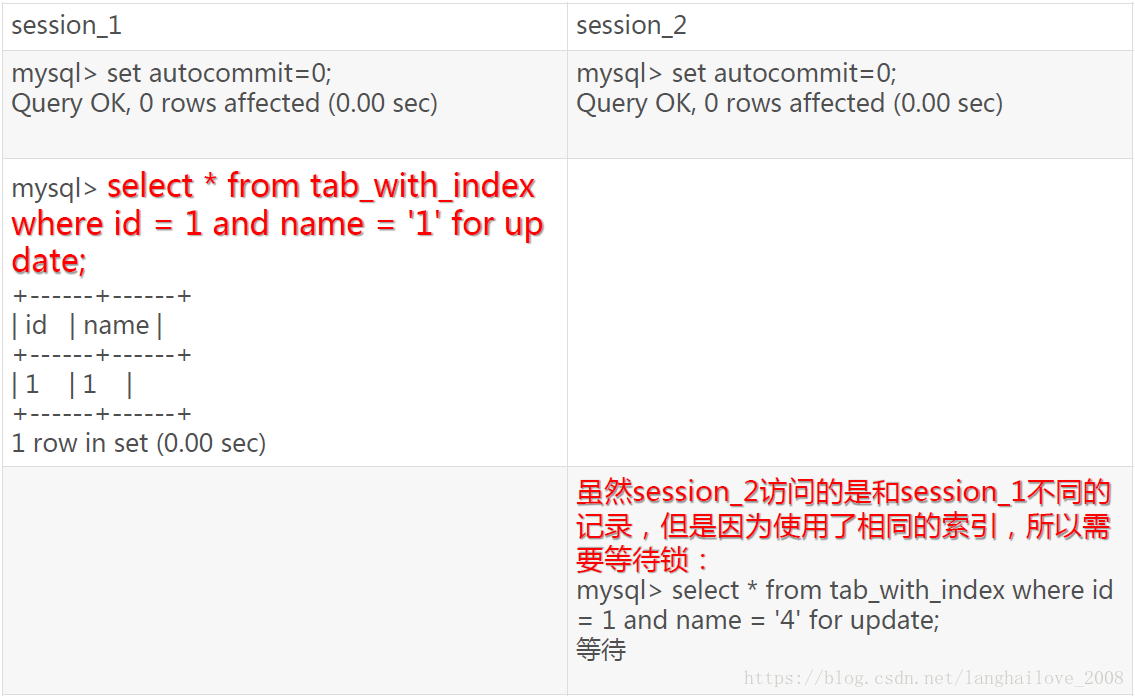
InnoDB使用不同索引键的阻塞示例
当表有多个索引的时,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
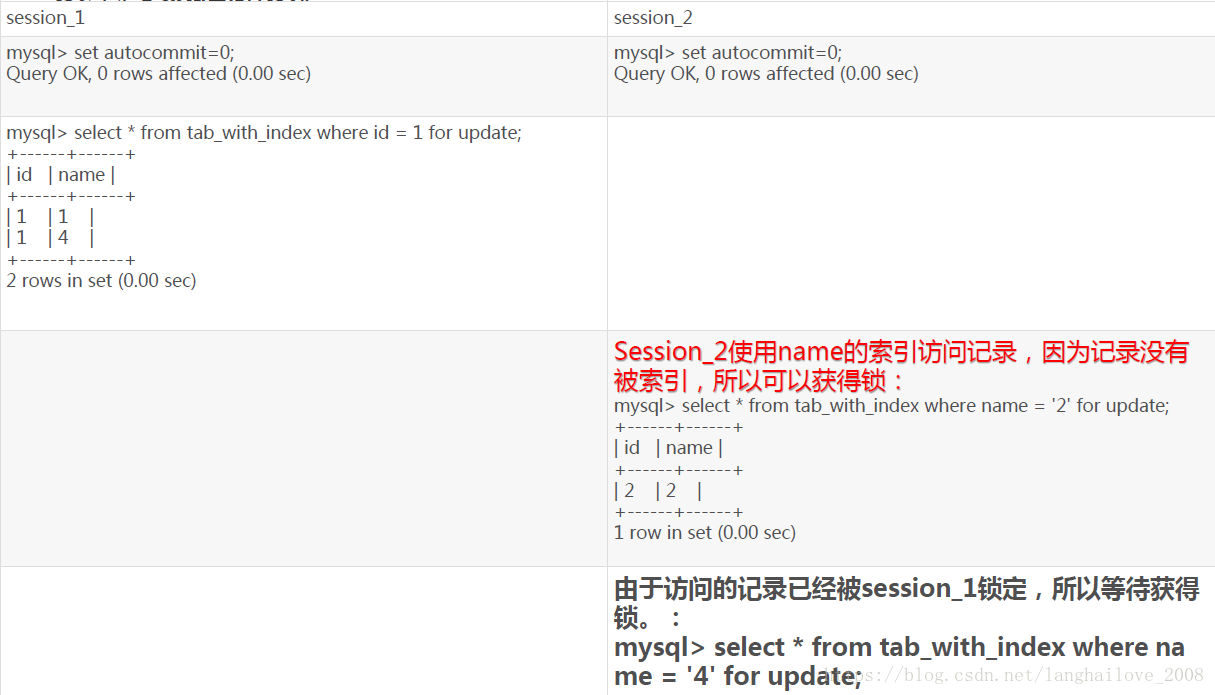
InnoDB使用表锁示例
即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。

InnoDB间隙锁
间隙(GAP):使用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录
间隙锁的目的:
一方面是为了防止幻读,以满足相关隔离级别的要求
另外一方面,是为了满足其恢复和复制的需要注意:InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!
间隙锁优化:
使用相等条件来访问更新数据,避免使用范围条件.
MySQL 死锁
死锁:两个事务都需要获得对方持有的排他锁才能继续
完成事务(循环锁等待)

MySQL 死锁优化示例1

MySQL 死锁SHOW INNODB STATUS输出的样例
死锁日志
2018-05-11 14:15:31 0x7f095d706700
*** (1) TRANSACTION:
TRANSACTION 31519, ACTIVE 18 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 10, OS thread handle 139678199613184, query id 67 localhost dba updatingdelete from student where id =2
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 1951 page no 3 n bits 72 index PRIMARY of table `test`.`student` trx id 31519 lock_mode X locks rec but not gap waiting
*** (2) TRANSACTION:
TRANSACTION 31520, ACTIVE 11 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 11, OS thread handle 139678199080704, query id 68 localhost dba updatingdelete from student where id=1
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 1951 page no 3 n bits 72 index PRIMARY of table `test`.`student` trx id 31520 lock_mode X locks rec but not gap
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 1951 page no 3 n bits 72 index PRIMARY of table `test`.`student` trx id 31520 lock_mode X locks rec but not gap waiting
*** WE ROLL BACK TRANSACTION (2)线上数据库死锁示例4
LATEST DETECTED DEADLOCK
2018-05-09 15:26:16 0x7f3294934700
*** (1) TRANSACTION:
TRANSACTION 5691598768, ACTIVE 0 sec fetching rows
mysql tables in use 1, locked 1
LOCK WAIT 211 lock struct(s), heap size 24784, 13572 row lock(s), undo log entries 200
MySQL thread id 175650, OS thread handle 139876721702656, query id 5460080291 10.144.75.147 cpcauditpart Searching rows for updateUPDATE cpcpartneraudit_0108 pa SET pa.checkstatus=least(pa.cpcpass, pa.noneaudit), pa.ideapass=1 WHERE pa.accountid = 429404 AND pa.checkstatus = 0 AND ((pa.backupideaid) IN (5075206071, 5075206072, 5075206073, 5075206074, 5075206075, 5075206076, 5075206328, 5075206584, 5075206586, 5075206839, 5075206840, 5075206841, 5075206842, 5075206843, 5075206844, 5075207100, 5075207350, 5075207351, 5075207354, 5075207356, 5075207607, 5075207609, 5075207611, 5075207862, 5075207863, 5075207864, 5075207865, 5075207866, 5075207867, 5075207868, 5075208120, 5075208122, 5075208124, 5075208376, 5075208378, 5075208630, 5075208631, 5075208632, 5075208633, 5075208634, 5075208635, 5075208636, 5075208886, 5075208887, 5075208888, 5075208889, 5075208890, 5075208891, 5075208892, 5075209398, 5075209399, 5075209401, 5075209403, 5075209404, 5075209654, 5075209655, 5075209656, 5075209657, 5075209658, 50752
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 106 page no 160321 n bits 552 index ix_aid_cs_na_cp_ideap of table `cpcauditpart01`.`cpcpartneraudit_0108` trx id 5691598768 lock_mode X waiting
*** (2) TRANSACTION:
TRANSACTION 5691598770, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
9 lock struct(s), heap size 1136, 74 row lock(s), undo log entries 72
MySQL thread id 176354, OS thread handle 139855217772288, query id 5460080876 10.149.34.158 cpcauditpart updatingDELETE FROM cpcpartneraudit_0108 WHERE keyid = 24290585387 AND ideaid = -5075212178
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 106 page no 160321 n bits 552 index ix_aid_cs_na_cp_ideap of table `cpcauditpart01`.`cpcpartneraudit_0108` trx id 5691598770 lock_mode X locks rec but not gap
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 106 page no 488280 n bits 176 index PRIMARY of table `cpcauditpart01`.`cpcpartneraudit_0108` trx id 5691598770 lock_mode X locks rec but not gap waiting
*** WE ROLL BACK TRANSACTION (2)尽量避免减少锁冲突和死锁
1、尽可能让所有的数据检索都通过索引来完成,从而避免Innodb 因为无法通过索引键加锁而升级为表级锁定;
2、合理设计索引,让Innodb 在索引键上面加锁的时候尽可能准确,尽可能的缩小锁定范围,避免造成不必要的锁定而影响其他Query 的执行;
3、尽可能减少基于范围的数据检索过滤条件,避免因为间隙锁带来的负面影响而锁定了不该锁定的记录;
4、尽量控制事务的大小,减少锁定的资源量和锁定时间长度;
5、尽量减少复杂query,将复杂query分散为小的query,减少锁定时间;
6、在业务环境允许的情况下,尽量使用较低级别的事务隔离,以减少MySQL 因为实现事务隔离级别所带来的附加成本;
7、不同程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,
尽可能以固定的顺序存取表中的行,这样可以大大减少死锁的机会。
■8、尽量用相等条件访问数据,这样可以避免next-key锁对并发插入的影响。
■9、对于一些特定的事务,可以使用表锁来处理速度或减少死锁的几率。
6 MySQL 开发规范
尽量不在数据库做运算
•让数据库多做它擅长的事:
尽量不在数据库做运算
复杂运算同到程序端CPU
尽可能简单应用MySQL
•举例:md5()/OrderbyRand()
控制单表数据量
•单表数据量预估
纯INT不超8000W
含CHAR不超5000W
•合理分表不超载
USERID
DATE
AREA
….
•建议单库不超过4000个表
保持表瘦身
•表字段数少而精
√ IO高效√全表遍历√表修复快
√提高开发√altertable快
•单表多少字段合适?
•单表1G体积500W行评估
顺序读1G文件需N秒
单行不超过200Byte
单表不超50个纯INT字段
单表不超20个CHAR(10)字段
•单表字段数上限控制在20~50个

拒绝3B
•拒绝3B
大SQL(BIGSQL)
大事务(BIGTransaction)
大批量(BIGBatch)
隔离线上线下
•构建数据库的生态环境
•开发无线上库操作权限
•原则:线上连线上,线下连线下
开发线上只读
开发线上只连从库
测试用qa库
开发用dev库
•案例:
永远不在程序端显式加锁
•永远不在程序端对数据库显式加锁
•外部锁对数据库不可控
•高开发时是灾难
•极难调试和排查
•涉及一致性问题的需求
•采用事务
•相对值修改
•Commit前二次较验冲突
统一字符集为UTF8
•统一字符集:5.5 5.6 版本UTF8
•统一字符集:5.7版本utf8mb4
•校对规则:utf8_general_ci
utf8mb4_general_ci
GTID限制
MySQL5.7默认开启GTID,以下操作受到限制
•无法使用CREATE TABLE … SELECT 语句
•不支持非事务性的表,如MyISAM表等。
•无法在事务中使用CREATE TEMPORARY TABLE、DROP TEMPORARY TABLE
•GTID复制不支持sql_slave_skip_counter参数
统一命名规范
•库表等名称统一用小写
LinuxVSWindows
MySQL库表大小写敏感
字段名的大小写不敏感
•索引命名默认为“ix_字段名,唯一索引uq_字段名”
•库名用缩写,尽量在2~7个字母
DataSharing==>ds
•注意避免用保留字命名
•……
7 应用层优化
•使用连接池
•减少对mysql的访问
避免对同一数据做重复检索
使用查询缓冲
在应用端加CACHE层
•负载均衡
利用MYSQL复制分流查询
采用分布式数据库架构
8 数据库高可用架构解决方案
大规模数据库环境升级到5.7版本
为什么要升级到5.7版本
1、Mysql5.7性能提升,在支持多处理器和高并发CPU线程的系统上,提供更持续的线性性能和
扩展性。5.7QPS接近100万,比5.5和5.6性能高3-4倍。
2、安全提升。
3、InnoDB存储引擎提升,更改索引名,在线DDL修改varchar字段属性不锁表,支持全文索引
4、主从复制采用多线程并行复制特性
5、Mysql5.7提供多源复制,无损的半同步复制。
6、JSON格式的支持,支持函数索引
7、功能提升,支持杀死慢的SQL语句,支持一张表有多个INSERT/DELETE/UPDATA触发器。提供
审计功能,支持explain update.
8、优化器改进,针对子查询select采用半连接优化,优化排序limit,优化IN条件表达式,优化
UNIONALL查询,支持hash join索引优化。
9、Mysql5.7对短连接优化
10、提供Bulk Load方式创建索引,在对10000000的表中执行create index性能5.7版本对比5.5
版本提升55%。
11、Mysql5.7对锁进行了优化,
12、Mysql5.7对InnoDB存储引擎改进,完全使用MDL锁来实现。改善了数据库的读写负载性能。
添加了更灵活性和更加优化的全文搜索。
13、性能模式提供更好的视角。增加了许多新的监控功能,以减少空间和过载,使用新的SYS模式显著提高易用性。
14、空间索引,使用Boost.Geometry,同时提高完整性和标准符合性。
Mysql5.5 VS Mysql5.7

传统复制和半同步复制

Mysqlgroup replication复制架构
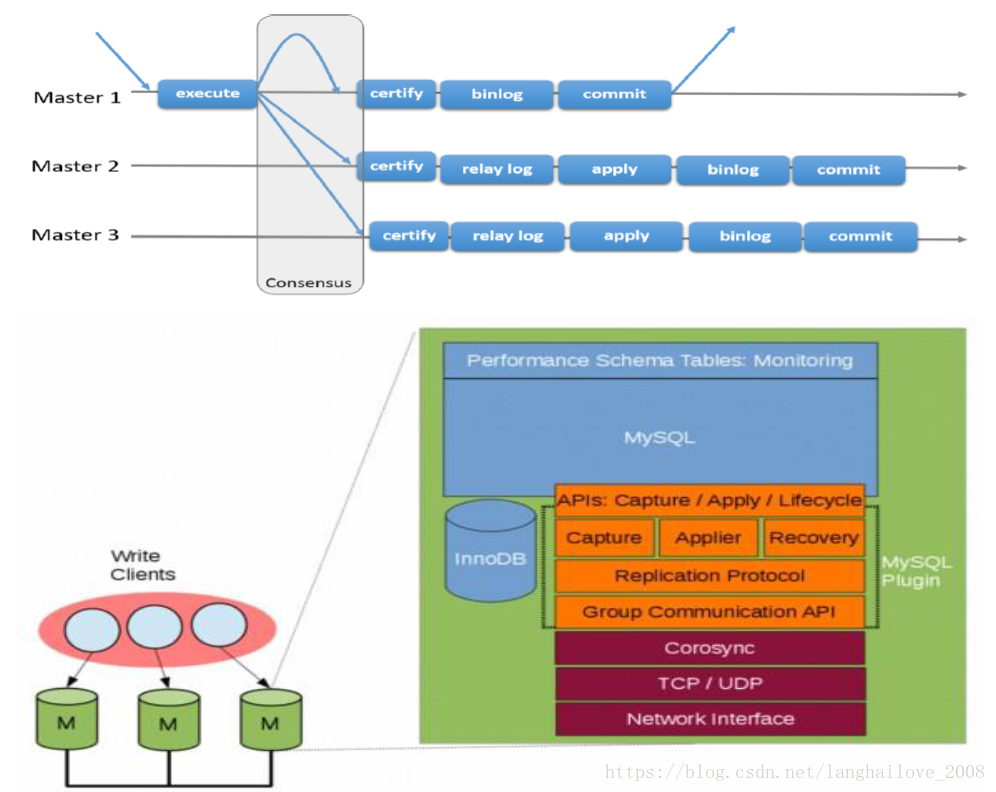
Mysqlgroup replication特性
•无共用实质同步数据库系统
–任何一个服务器都可以更新的多主
–可侦测冲突且解决之(事务转回)
–Optimistic State Machine Replication
•自动组成员管理和故障侦测
–不需服务器故障移转
–弹性横向扩张和收缩
–无单点故障
–自动重构
•完整整合
–InnoDB
–GTID-based replication
–PERFORMANCE_SCHEMA
•通过Paxos协议提供数据库集群节点数据强一致保证
• 自动实现failover
• 高扩展性,最多支持9个节点
• 0延迟
• 网络分区导致的脑裂问题,提升复制数据的可靠性
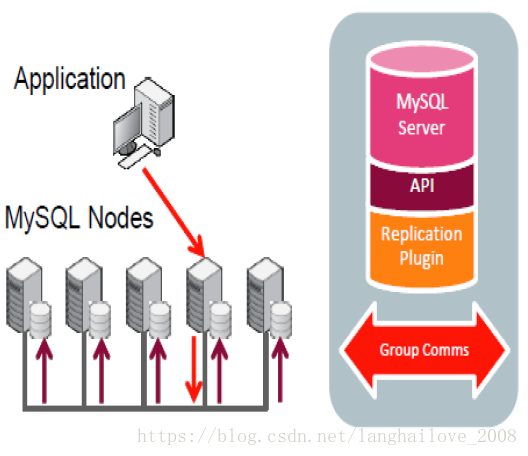
MGR 如何实现failover
◆Single-PrimaryMode
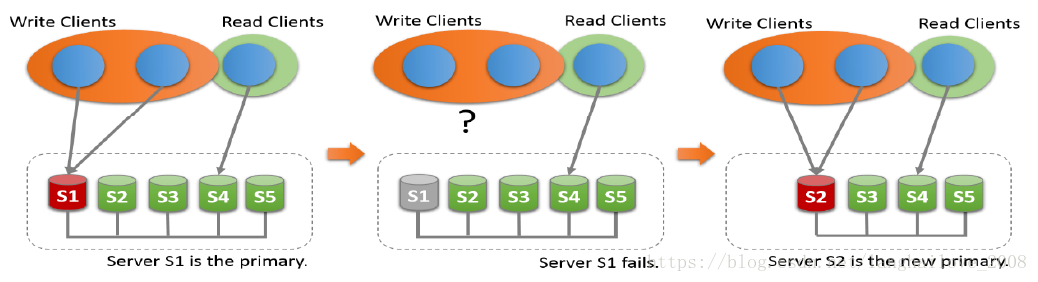
◆Multi-PrimaryMode
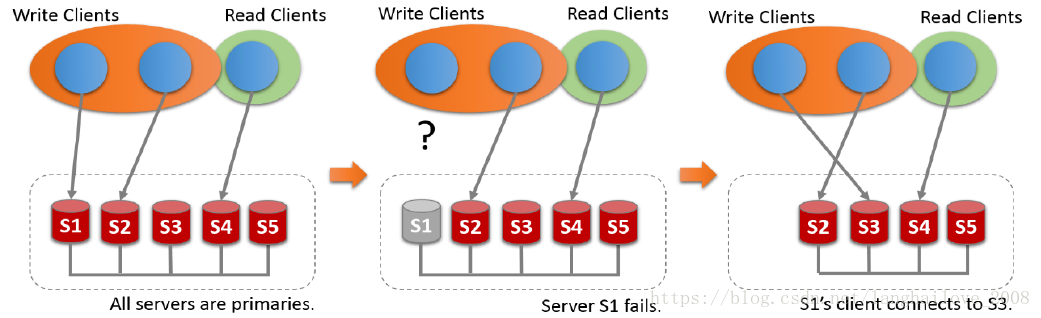
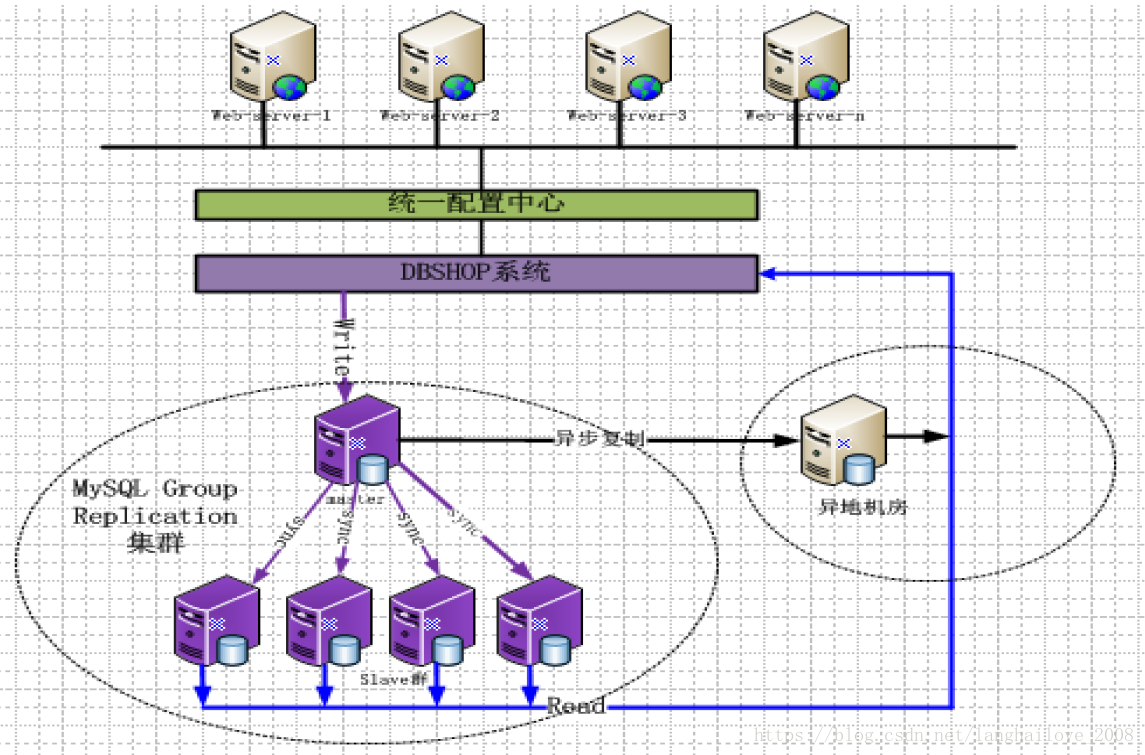
MGR自动化架构优化

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









