






今天跟路飞学习爬虫时,遇到的中文乱码。他提出了一种解决方法,而我在弹幕上也看到了一种方法。
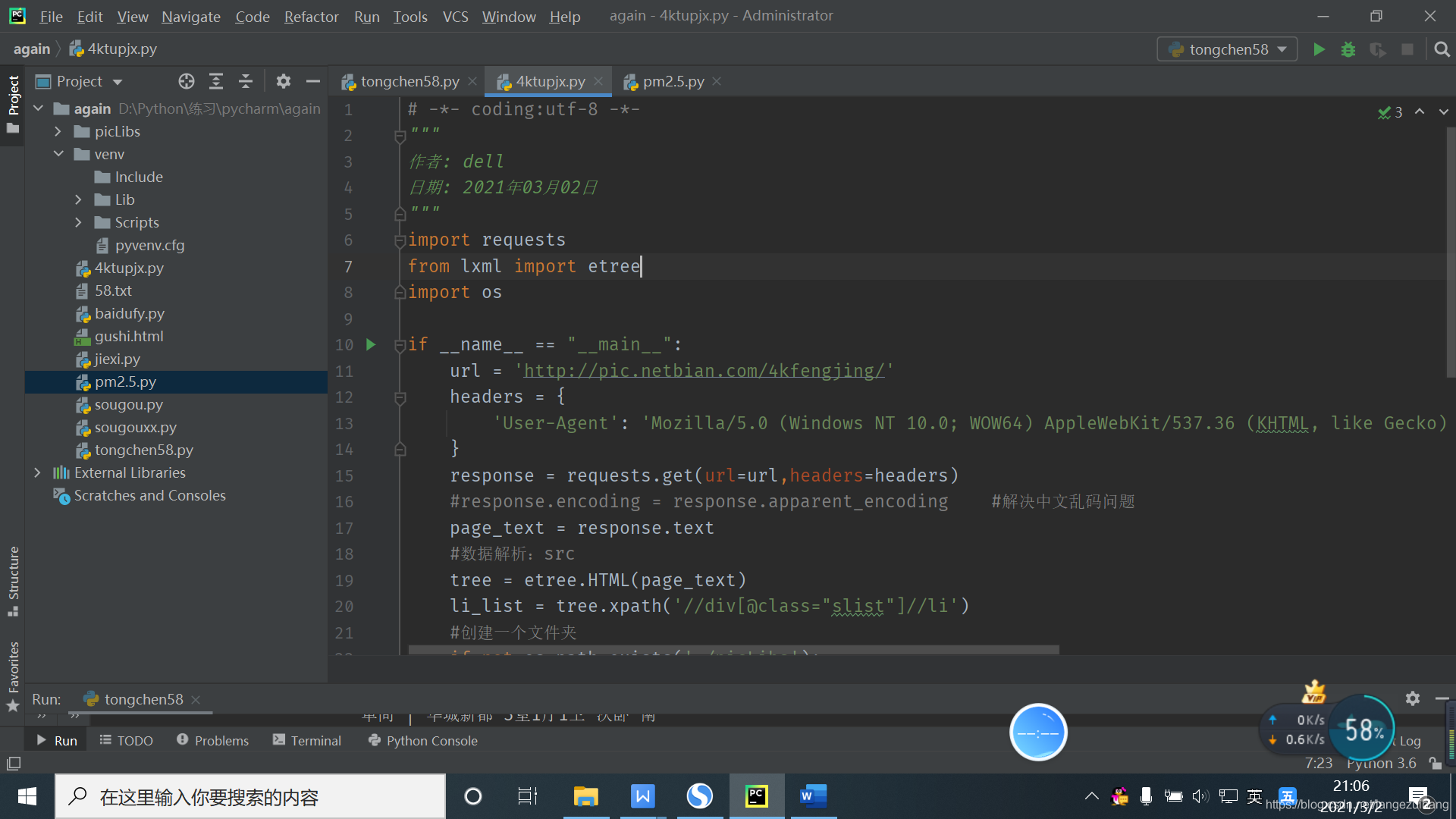
法1:在响应数据时加一句
response.encoding = response.apparent_encoding
法2:
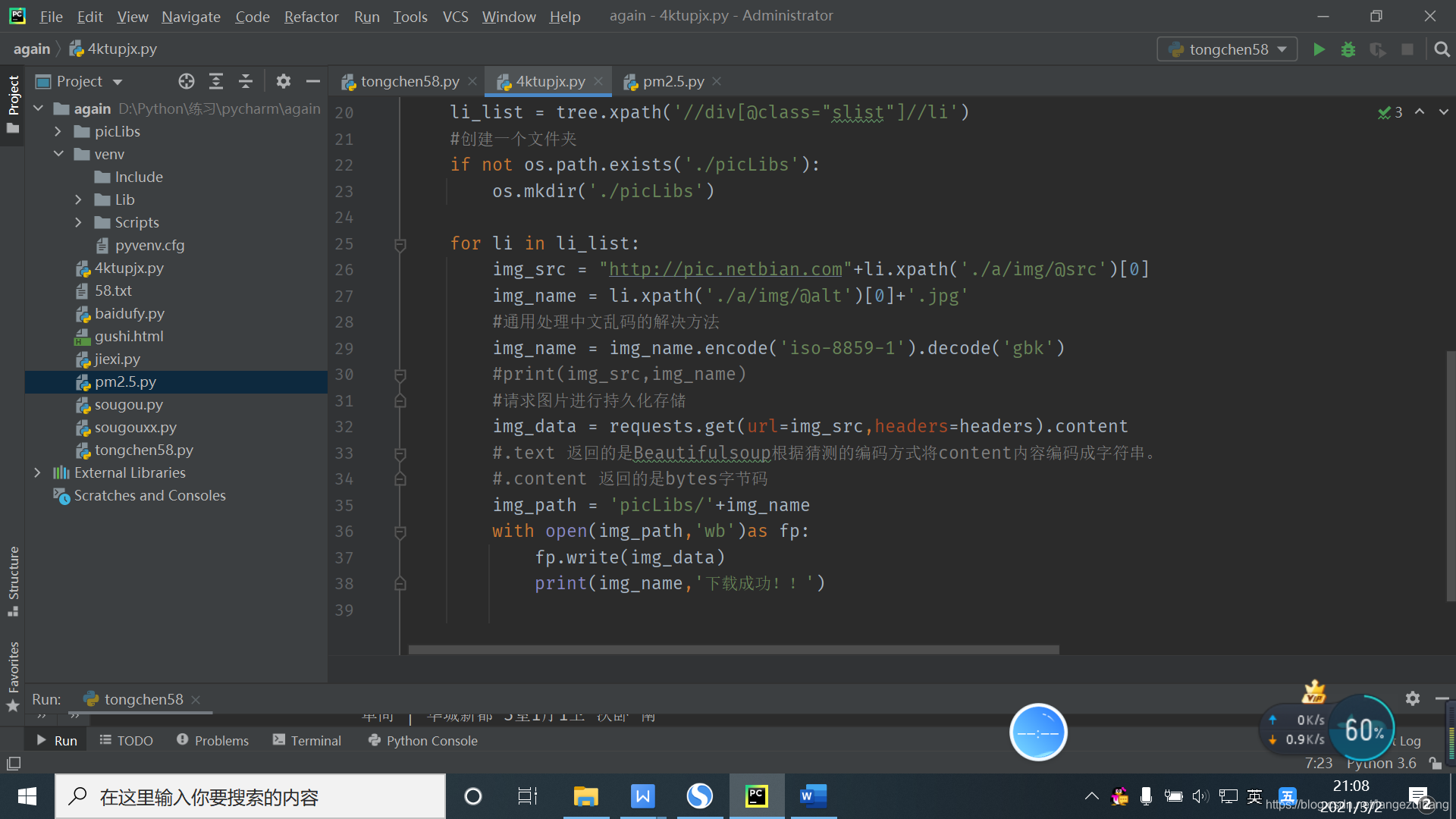
#通用处理中文乱码的解决方法
img_name = img_name.encode('iso-8859-1').decode('gbk')
以上两种方法都可以解决中文乱码问题,不过第二种比较通用。你们可以自由选择。

今天跟路飞学习爬虫时,遇到的中文乱码。他提出了一种解决方法,而我在弹幕上也看到了一种方法。
法1:在响应数据时加一句
response.encoding = response.apparent_encoding
法2:
#通用处理中文乱码的解决方法
img_name = img_name.encode('iso-8859-1').decode('gbk')
以上两种方法都可以解决中文乱码问题,不过第二种比较通用。你们可以自由选择。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1414
1414





