




 这篇博客介绍了如何使用Speech2Vid模型将声音直接转化为与音频同步的视频帧。模型通过学习音频和目标脸部的联合嵌入来生成视频,主要由音频编码器、身份编码器和图像解码器组成。训练过程中,使用了VoxCeleb和LRW数据集,并利用预训练的VGG-M网络来提取身份特征。尽管进行了正面化处理,但为了解决对齐问题,还引入了一个去模糊模块。模型通过L1损失进行优化,训练时使用不同时间点的图像作为输入,以生成单帧视频,而不需要严格的时间连续性约束。
这篇博客介绍了如何使用Speech2Vid模型将声音直接转化为与音频同步的视频帧。模型通过学习音频和目标脸部的联合嵌入来生成视频,主要由音频编码器、身份编码器和图像解码器组成。训练过程中,使用了VoxCeleb和LRW数据集,并利用预训练的VGG-M网络来提取身份特征。尽管进行了正面化处理,但为了解决对齐问题,还引入了一个去模糊模块。模型通过L1损失进行优化,训练时使用不同时间点的图像作为输入,以生成单帧视频,而不需要严格的时间连续性约束。
[toc】
前言
- 以往的输出往往都需要借助中间形式, landmarks, 3d models, 这是一个从声音直接映射到视频的方法, 输入是声音和图像, 输出是一段视频。
- 关键思想是学习到target face 和 speech segment的joint embedding, 这个embedding可以被用于产生和音频同步的帧。
Dataset
整个流程如下:

这里canonical face就类似正面化的脸部, 如下图:

这里需要用到一些变换, 因为输入的人脸要变正, 通过放缩, 旋转和平移实现相似变换。这里变换的是鼻子眼睛啥的, 嘴部没有变化。为了保留嘴部运动信息。

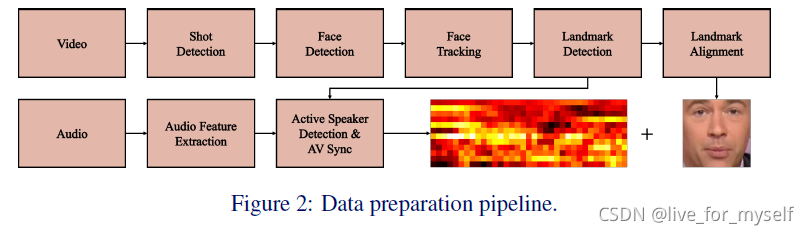
使用了VoxCeleb和LRW数据集, 用DLIB检测landmarks。 作者还提到SyncNet提供了视频中音频和视觉面部序列的联合嵌入, 可以确定好几个人中是谁在讲话, 同时还可以纠正语音同步错误, 我寻思LRW数据集也不用这么折腾····
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5281
5281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











