






文章出处
- Home / Database / Oracle Database Online Documentation 11g Release 2 (11.2) / Database Administration
- http://docs.oracle.com/cd/E11882_01/server.112/e40540/indexiot.htm#CNCPT721
前提
- 在前一篇中提到,说要先读后面的体系结构,仔细想了想,我当初就是从体系结构开始学的,现在又要按照这个套路,显然不合适,所以还是决定按官方文档的顺序读读,而且接下来也不会做详细的翻译,只是做”笔记”
索引概述
索引简介
- 索引是schema对象
- 索引是一个可选的结构
- 可以在表或者表簇中建立索引
- 可以为一列建索引,也可以为列的组合建索引
- 建立索引可以提高数据访问效率,是一种减少io的方法
- 如果没有索引,在访问heap组织表时会进行全表(FTS,full table scan)扫描
- 有下列情况建议建立索引:
- 索引列频繁被访问,并且返回的数据是一小部分
- 引用完整性约束索引列或列的组合,这样能减少全表锁
- 有唯一约束
- 索引具有如下特性:
- 和实际数据独立,如果索引发生了变化(被删除了),实际的对象数据不会变,只是进行访问数据时可能会变慢
- 索引被数据库自动维护
- 可用性
- 可见性
- 键是建立索引时的一组列或者表达式,例如:
CREATE INDEX ord_customer_ix ON orders (customer_id);- customer_id列就是索引键
- 复合索引:在多列上建立的索引,组合顺序不同(数目相同也是允许的),索引也不同
- 唯一索引和非唯一索引
- ascending index:按照索引值从小到大组织数据
- descending index:按照索引值从大到小组织数据
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC);- Key Compression:索引值压缩,可以压缩B树索引或者索引组织表的主键值
--一开始的数据
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt
--压缩后
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt
--或者
online
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
3,AAAPvCAAFAAAAFaAAq
3,AAAPvCAAFAAAAFaAAt
- 索引类别
- B-tree索引
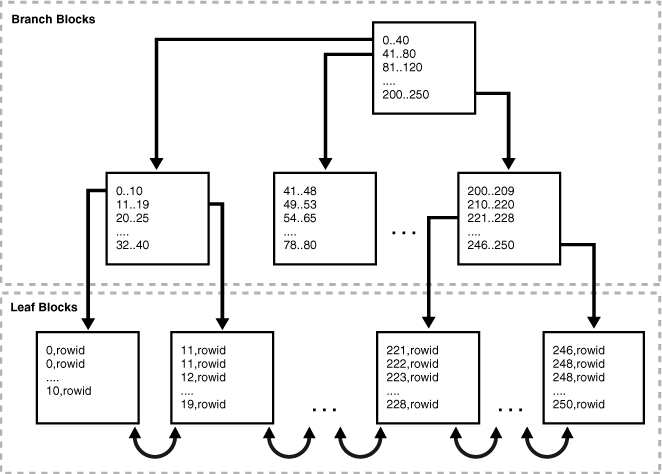
- Index-organized tables
- Reverse key indexes
- Descending indexes
- B-tree cluster indexes
- bitmap索引
- 基于函数索引
- Application domain indexes
- B-tree索引
- Index Storage(索引的存储):存储在索引段中,相应的表空间,是默认的表空间或者是使用create index语句的用户的表空间,当然,也可以为索引建立专门的表空间
索引扫描
- Full Index Scan(FIS)
- 当sql语句有where语句时,可以使用FIS来进行扫描,FIS这种扫描方式可以防止数据进行排序,原因在于,数据已经在索引中排好序了
- Fast Full Index Scan(FFIS)
- FFIS只有在访问的数据只是索引而不需要访问表的条件下才会使用,具体条件如下
- 索引必须包含所有要查询的列
- 列要有not null约束或者在where语句中限制没有null值
- FFIS只有在访问的数据只是索引而不需要访问表的条件下才会使用,具体条件如下
- Index Range Scan (IRS)
- IRS是范围索引扫描,比如说1~100范围的数据,这个时候就会用到(通常这都涉及到逻辑运算符,大于小于等等,内部实现其实就是利用这些运算得出布尔值来扫描的)
- Index Unique Scan(IUS)
- 索引唯一扫描,指定相应key的扫描,key必须是索引
Index Skip Scan(ISS)
- 在一张建有复合索引的表中,如果只是搜索其中非第一个列的信息,那么在复合索引中的第一列将被“忽略”,这种忽略其实是全部考虑
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.com';- 上面的例子中,如果复合索引是(cust_gender, cust_email),那么将被转化为
SELECT * FROM sh.customers WHERE cust_gender = 'F' AND cust_email = 'Abbey@company.com' UNION ALL SELECT * FROM sh.customers WHERE cust_gender = 'M' AND cust_email = 'Abbey@company.com';
- index clustering factor:一种用来度量与索引值有关的行的排序程度,如果行存储得越有序,那么这个值就越低。一般情况下,如果这个值越高,那么索引查询需要IO就会越高;这个值越低,说明在进行索引扫描时,读取的记录都会尽可能地在同一个block,从而IO次数会减少

SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2Reverse Key Indexes
- 是一种B树索引,在物理上翻转了索引键的bytes,例如,20这两个byte存储为十六进制的C1,15,翻转后为15,C1。
- 这样做的意义:减少B树叶子节点的数据块竞争。
位图索引(Bitmap Indexes)
- 位图是什么?请自行查看数据库原理相关书籍或者其它资料
- B树索引的每个索引entry指向一行,而位图索引的每个索引键值指向多行
- 使用场景:列的基数比较小(例如一般情况下,性别只有男和女,这样基数就很低),相应的表最好是只读的
SQL> SELECT cust_id, cust_last_name, cust_marital_status, cust_gender
2 FROM sh.customers
3 WHERE ROWNUM < 8 ORDER BY cust_id;
CUST_ID CUST_LAST_ CUST_MAR C
---------- ---------- -------- -
1 Kessel M
2 Koch F
3 Emmerson M
4 Hardy M
5 Gowen M
6 Charles single F
7 Ingram single F
7 rows selected.
位图连接索引(Bitmap Join Indexes)
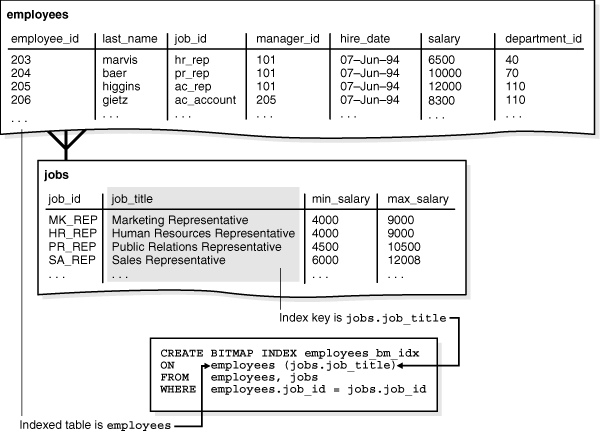
位图存储结构
- 使用B树来存储位图
基于函数的索引(Function-Based Indexes)
- 函数可以是表达式也可以是PL/sql等等
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);
CREATE INDEX emp_fname_uppercase_idx
ON employees ( UPPER(first_name) );
CREATE INDEX cust_valid_idx
ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END );基于函数的索引优化
- 在查询中,利用到基于函数的索引,优化器会使用索引范围扫描。
Application Domain Indexes
- 是为特定应用而定制的索引
索引组织表(index-organized table)
- 数据存储在B树中,不只是索引值(一般的表,数据是存储在堆中的,关于堆和B树,都是数据结构,可自行查看一些数据结构的资料)
- 是基于主键的索引
- 不能存储long类型的数据
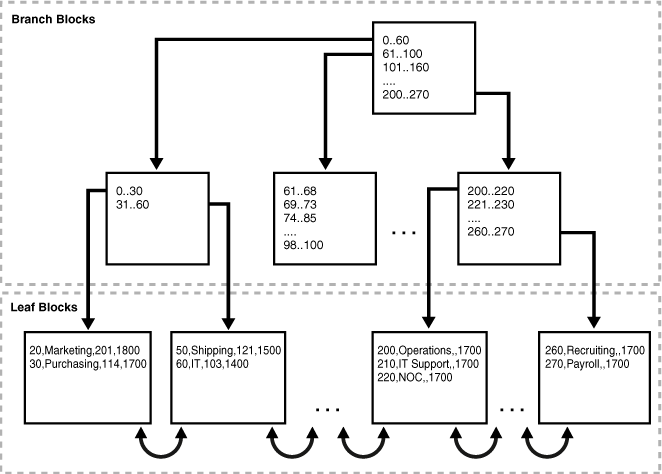
- 可以设置Row Overflow Area,这个区域是一个独立的segment(段),这样索引组织表就包含了两个部分:
- index entry:保存了索引键值,物理的rowid指向overflow part
- overflow part:存储非键值的行数据
索引组织表里的二级索引
- 就是索引组织表上建立的索引
- 逻辑rowid,是一种用base64编码的表达形式,代表表的主键(复习一下:物理rowid是用在堆组织表,表簇,表或索引的分区上的;而逻辑rowid是用在索引组织表上的;foreign rowid是用在非oracle数据库上的数据上的,是一个相对的概念)
- 逻辑rowid包含了physical guess,这个东西是物理rowid的索引entry
在索引组织表上建立位图索引
- 在索引组织表上的二级索引可以是位图索引


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









