




| 符号 | 描述 |
|---|---|
| string1|string | 匹配正则表达式string1或者string2的部分 |
| * | 匹配0次或者多次前面出现的表达式 |
| + | 匹配1次或者多次前面出现的表达式 |
| ^ | 匹配字符串的起始部分 |
| $ | 匹配字符串的终止部分 |
| \ | 将特殊子字符无效化 |
| {N} | 匹配N次前面出现的正则表达式 |
| {M,N} | 匹配M~N次前面出现的正则表达式(N和M中间逗号左右不能有空格,否者什么也匹配不到) |
| [...] | 匹配来自字符集的任意单一字符 |
| [..x-y..] | 匹配x~y中的任意单一字符 |
| [^...] | 不匹次字符集中出现的任何一个字符,包括某一范围的字符 |
字符 | 示例
import re
string='Im 18 years old'
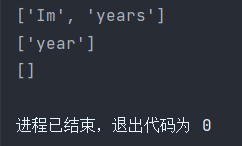
print(re.findall('Im|years',string))
print(re.findall('im|year',string))
print(re.findall('im|Year',string))
程序运行结果:匹配成功会将该字符以列表形式返回,如果全部匹配失败,会返回一个空列表
^示例:
import re
string='Im 18 years old'
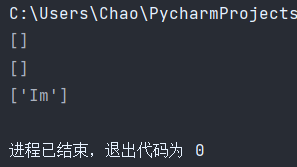
print(re.findall('^Im years',string))
print(re.findall('^Imyear',string))
print(re.findall('^Im',string))
程序运行结果:\A 和^作用相同,
$示例
import re
string='Im 18 years old'
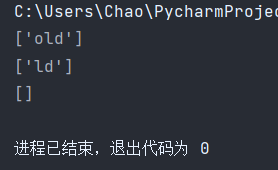
print(re.findall('old$',string))
print(re.findall('ld$',string))
print(re.findall('years old$',string))
程序运行结果
*示例
import re
string='Im 18 # years * ^ @ old'
print(re.findall('\w*',string))
print(re.findall('\w+',string))
运行结果:\w表示只匹配数字字母下划线,*表示匹配0次或者多次,也允许匹配不出来,所以#就变成了空的,

{}示例1
import re
string='Im 18 years old'
print(re.findall('\w{3}',string))
print(re.findall('[a-z]{3}',string))
print(re.findall('\w{2}',string))
print(re.findall('[a-z]{2}',string))
运行结果:{3}表示只匹配3个字符,

{}示例2
import re
string='Im 18 years old'
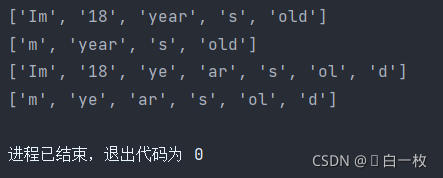
print(re.findall('\w{1,4}',string))
print(re.findall('[a-z]{1,4}',string))
print(re.findall('\w{1,2}',string))
print(re.findall('[a-z]{1,2}',string))
运行结果:
[^..] 代表过滤,[]里面的^不住表示开始
import re
string='Im 18 years old ###'
print(re.findall('[^Im]',string))
运行结果


















 6039
6039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









