 DuckDB在手机运行TPC-H SF100性能突破
DuckDB在手机运行TPC-H SF100性能突破







https://duckdb.org/2024/12/06/duckdb-tpch-sf100-on-mobile.html#a-song-of-dry-ice-and-fire
TL;DR:DuckDB运行在iOS和Android等移动平台上,比20年前在大铁机上最先进的研究系统更快地完成TPC-H基准测试。
几周前,我们开始进行一系列实验来回答两个简单的问题:
- DuckDB 在新智能手机上运行时,能否完成对 SF100 数据集的 TPC-H 查询?
- 如果是这样,DuckDB 能否在不到 400 秒的时间内完成一次运行,即比研究论文中最初引入矢量化查询处理的系统更快?
这些问题让我们开始了一次有趣的探索。 一路上,我们玩得很开心,并了解了冷跑和真正冷跑之间的区别。 请继续阅读以了解更多信息。
干冰与火之歌
我们的第一次尝试是使用 iPhone,即 iPhone 16 Pro。 这款手机拥有 8 GB 内存和 6 核 CPU,具有 2 个性能核心(运行频率为 4.05 GHz)和 4 个效率核心(运行频率为 2.42 GHz)。
我们使用 DuckDB Swift 客户端实现了该应用程序,并在手机上加载了基准测试,全部为 30 GB。 我们很快发现 iPhone 确实可以毫无问题地运行工作负载——除了它在工作负载期间发热。这促使手机执行热节流,减慢 CPU 速度以减少热量产生。因此,DuckDB 耗时 615.1 秒。不错,但不足以达到我们的目标。
结果让我们思考:如果我们改善手机的散热效果会怎样?为此,我们购买了一盒温度低于-50摄氏度的干冰,并在实验期间将手机放入盒子中。

这帮了大忙:DuckDB 在 478.2 秒内完成。这是 20% 以上的改进——但我们仍然没有设法低于 400 秒。

机器人会梦见电鸭吗?
在我们的下一个实验中,我们选择了一款运行 Android 24 的三星 Galaxy S14 Ultra 手机。这款手机充满了有趣的硬件。首先,它有一个 8 核 CPU,有 4 种不同的核心类型(1×3.39 GHz、3×3.10 GHz、2×2.90 GHz 和 2×2.20 GHz)。其次,它有大量的 RAM——准确地说是 12 GB。最后,其冷却系统包括一个用于改善散热的均热板。
我们在 Termux 终端模拟器中运行了 DuckDB。我们按照 Android 构建说明从源代码编译了 DuckDB CLI 客户端,并从命令行运行了实验。
最后,甚至还差一点。Android 手机在 235.0 秒内完成了基准测试,比我们的基线高出约 40%。
从来都不是阴天
结果让我们思考:结果在云服务器之间如何叠加?我们在 AWS EC2 中选择了两个基于 x86 的云实例,具有实例附加的 NVMe 存储。
这些基准测试的细节远不如以前的基准测试有趣。我们使用 Ubuntu 24.04 启动实例并在命令行中运行 DuckDB。我们发现,一个 r6id.large 实例(2 个 vCPU 和 16 GB RAM)在 570.8 秒内完成查询,这与风冷 iPhone 大致相当。然而,r6id.xlarge(4 个 vCPU 和 32 GB RAM)在 166.2 秒内完成了基准测试,比我们在手机上获得的任何结果都要快。
DuckDB 结果摘要
该表包含 DuckDB 基准测试结果的摘要。
| 设置 | CPU 内核 | 记忆 | 运行 |
|---|---|---|---|
| iPhone 16 Pro(风冷) | 6 | 8 GB | 615.1 秒 |
| iPhone 16 Pro(干冰冷却) | 6 | 8 GB | 478.2 秒 |
| 三星Galaxy S24 Ultra | 8 | 12 GB | 235.0 秒 |
AWS EC2r6id.large | 2 | 16 GB | 570.8 秒 |
AWS EC2r6id.xlarge | 4 | 32 GB | 166.2 秒 |
历史背景
那么,我们为什么要首先进行这些实验呢?
就在几周前,DuckDB 的发源地 CWI 举行了 Dijkstra 奖学金颁奖典礼。 该奖学金授予 Marcin Żukowski,以表彰他在数据库管理系统开发方面的开创性作用以及他成功的创业生涯,从而产生了 VectorWise 和 Snowflake 等系统。
许多源自 Marcin 研究的想法都用于 DuckDB。最重要的是,矢量化查询处理使 DuckDB 能够同时快速和可移植。 他与他的合著者 Peter Boncz 和 Niels Nes 在 CIDR 2005 年的论文“MonetDB/X100:超流水线查询执行”中首次描述了这种范式。
术语矢量化、超流水线和超标量指的是同一个想法:在切片中处理数据,事实证明,这是一次行或一次列之间的一个很好的折衷方案。DuckDB 的查询引擎使用相同的原理。
这篇论文发表于 2005 年 1 月,因此可以肯定地假设它是在 2004 年底定稿的——几乎正好是 20 年前!
如果我们阅读这篇论文,我们会了解到实验是在配备 12 GB 内存的 HP 工作站上进行的(与三星手机今天的内存量相同! 它还有一个 Itanium CPU,看起来像这样:

Itanium 于 2001 年发布后,面向高端市场,目标是最终用主要关注 SIMD(单指令、多数据)的新指令集取代当时占主导地位的 x86 架构。虽然这一雄心壮志没有实现,但 Itanium 是当时最先进的建筑。由于专注于服务器市场,安腾 CPU 拥有大量缓存:实验中使用的 1.3 GHz Itanium2 型号具有 3 MB 的 L2 缓存,而当时发布的 Pentium 4 CPU 只有 0.5-1 MB。
该白皮书提供了运行时的详细细分:
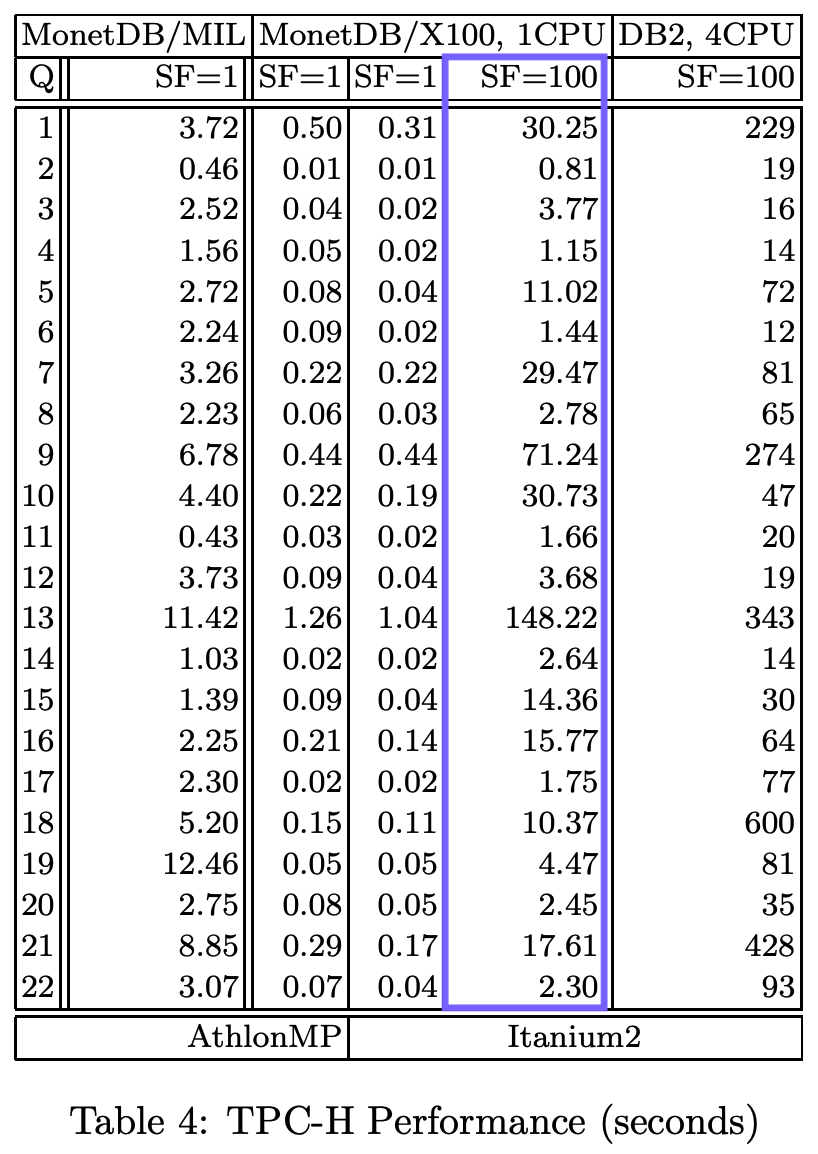
TPC-H SF100 查询的总运行时间为 407.9 秒,因此我们的实验基线。 以下是 Hannes 在活动中展示结果的视频:
以下是在绘图上可视化的所有结果:

结论
从最初的矢量化执行论文到在手机上运行分析数据库,这是一段漫长的旅程。 许多关键创新都实现了这些结果,硬件的重大改进只是其中之一。 另一个关键组成部分是编译器优化变得更加复杂。 因此,虽然 MonetDB/X100 系统需要使用显式 SIMD,但 DuckDB 可以依赖我们(精心构建的)循环的自动矢量化。
剩下的就是回答我们在旅程开始时提出的问题。 是的,DuckDB 可以在手机上运行 TPC-H SF100。 是的,在某些情况下,它甚至可以胜过在 2004 年高端机器上运行的研究原型——在可以放在口袋里的现代智能手机上。
随着更新的硬件、更智能的编译器和尚未发现的数据库优化,未来的版本只会更快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}