



20211101
在 Airbnb 使用机器学习预测房源的价格
https://blog.csdn.net/weixin_33735077/article/details/87976278?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-8.essearch_pc_relevant&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-8.essearch_pc_relevant
自动化机器学习(AutoML)可以帮助机器学习管道中的某些关键组件实现自动化。其中机器学习管道包括数据理解、数据工程、特征工程、模型训练、超参数调整、模型监控等。
在这篇文章中,我将分享 8 个开源的 autoML 框架:
Auto-Sklearn
TPOT
Auto-ViML
H2O AutoML
Auto-Keras
MLBox
Hyperopt Sklearn
AutoGluon
1、Auto-Sklearn
Auto-sklearn 是基于 scikit-learn 软件包构建的开源 AutoML 库。它为给定的数据集找到最佳性能的模型以及最佳的超参数集。它包括一些特征工程技术,例如单点编码,特征归一化,降维等。该库使用 Sklearn 估计器来处理分类和回归问题。
Auto-sklearn 库适用于中小型数据集,不适用于大型数据集。
安装方法
pip install autosklearn
实用示例
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)
2、TPOT

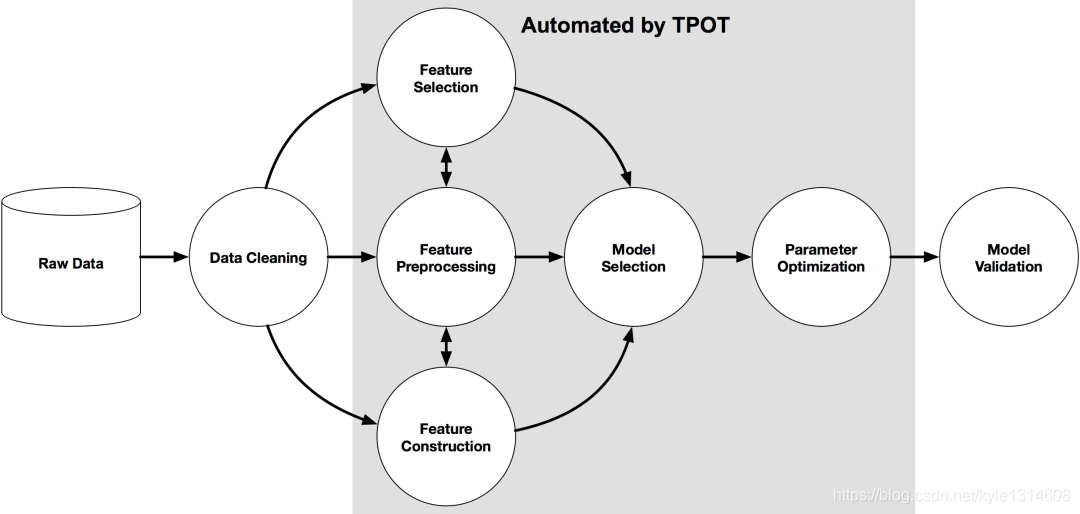
TPOT 是开源的 python AutoML 工具,可使用遗传编程来优化机器学习管道。TPOT 体系结构的数据流可以在下图中观察到。数据清理不在 TPOT 体系结构之内,也就是说,处理缺失值,将数据集转换为数值形式应由数据科学家处理。
安装方法
pip install tpot
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
https://github.com/EpistasisLab/tpot
链接
3、Auto-ViML
Auto-ViML代表自动变体实现机器学习。TPOT AutoML工具的局限性在于它需要数字格式的数据集。任何遗漏的值处理和数据清理工作都应在TPOT实施之前完成。
AutoViML可以解决此问题,因为它可以对数据集进行编码,特征选择和其他数据清理活动。AutoViML相对比TPOT更快,并会生成多个图形结果以及模型选择和超参数优化。
安装方法
pip install autoviml
实用示例
from autoviml.Auto_ViML import Auto_ViML
model, features, trainm, testm = Auto_ViML(
train,
target,
test,
sample_submission,
hyper_param="GS",
feature_reduction=True,
scoring_parameter="weighted-f1",
KMeans_Featurizer=False,
Boosting_Flag=False,
Binning_Flag=False,
Add_Poly=False,
Stacking_Flag=False,
Imbalanced_Flag=False,
verbose=0,
)
4、H2O AutoML
H2O AutoML是 H2O 开发的框架,可用于使机器学习工作流程自动化,包括在指定时限内自动进行模型训练和模型的超参数调整。
H2O AutoML 工具可以进行数据预处理,例如数字编码,缺失值插补和其他预处理工作流程。最后,它会自动进行模型选择和超参数调整,并以模型的排行榜视图及其性能返回。AutoML还提供了随时可用的部署代码。
安装方法
要安装h2o,需要一个Java运行环境,因为h2o是用Java开发的。
!apt-get install default-jre
!java -version
!pip install h2o
实用示例
import h2o
from h2o.automl import H2OAutoML
aml = H2OAutoML(max_models = 10, seed = 10, exclude_algos = ["StackedEnsemble", "DeepLearning"], verbosity="info", nfolds=0)
aml.train(x = x, y = y, training_frame = churn_train, validation_frame=churn_valid)
5、Auto-Keras
Auto-Keras 是基于深度学习框架 Keras 构建的开源 AutoML 库,该框架是由 Texas A&M University 的 Datalab 团队开发的。AutoKeras自动搜索深度学习模型的体系结构和超参数,并使用训练数据对其进行训练,最后返回性能最佳的深度学习模型。Auto-Keras遵循经典的Scikit-Learn API设计,因此易于使用。
安装方法
pip3 install autokeras
import autokeras as ak
clf = ak.ImageClassifier()
clf.fit(x_train, y_train)
results = clf.predict(x_test)
6、MLBox
MLBox 是功能强大的 AutoML python库。它提供了以下功能:
快速读取和分布式数据预处理/清理/格式化
高度可靠的功能选择和泄漏检测
高维空间中的精确超参数优化
最新的分类和回归预测模型(深度学习,堆栈,LightGBM等)
用模型解释进行预测
安装方法
pip install mlbox
## or
brew install libomp
实用示例
from mlbox.preprocessing import *
from mlbox.optimisation import *
from mlbox.prediction import *
paths = ['train.csv', 'test.csv'] #to modify
target_name = "target" #to modify
data = Reader(sep=",", header = 0, to_hdf5 = True, to_path = 'save', verbose = True).train_test_split(Lpath = paths, target_name = target_name) #reading
7、Hyperopt Sklearn
HyperOpt-Sklearn 包装了 HyperOpt 库,该库是用于贝叶斯优化的开源Python库。它设计用于具有大量超参数的模型的大规模优化,并允许优化过程跨多个内核和多台机器进行缩放。它允许自动搜索数据准备方法,机器学习算法以及用于分类和回归任务的模型超参数。
安装方法
pip install hyperopt
from hpsklearn import HyperoptEstimator, sgd
from hyperopt import hp
import numpy as np
sgd_penalty = 'l2'
sgd_loss = hp.pchoice(’loss’, [(0.50, ’hinge’), (0.25, ’log’), (0.25, ’huber’)])
sgd_alpha = hp.loguniform(’alpha’, low=np.log(1e-5), high=np.log(1))
estim = HyperoptEstimator(classifier=sgd(’my_sgd’, penalty=sgd_penalty, loss=sgd_loss, alpha=sgd_alpha))
estim.fit(X_train, y_train)
8、AutoGluon
AutoGluon 是为 AWS 开源的深度学习工作负载而开发的 autoML 框架。与其他仅支持表格数据的autoML库不同,它还支持图像分类,对象检测,文本以及跨图像的实际应用程序。
适用于ML初学者和专家,AutoGluon具有如下特点:
用几行代码为您的数据找到深度学习解决方案
自动超参数调整,模型选择/架构搜索以及数据处理
改进现有的定制模型和数据管
安装方法
pip install mxnet
pip install autogluon
实用示例
import autogluon as ag
import pandas as pd
import numpy as np
import os,urllib
from autogluon import TabularPrediction as task
BASE_DIR = '/tmp'
OUTPUT_FILE = os.path.join(BASE_DIR, 'churn_data.csv')
churn_data=urllib.request.urlretrieve('https://raw.githubusercontent.com/srivatsan88/YouTubeLI/master/dataset/WA_Fn-UseC_-Telco-Customer-Churn.csv', OUTPUT_FILE)
churn_master_df = pd.read_csv(OUTPUT_FILE)
size = int(0.8*churn_master_df.shape[0])
train_df = churn_master_df[:size]
test_df = churn_master_df[size:]
train_data = task.Dataset(df=train_df)
test_data = task.Dataset(df=test_df)
predictor = task.fit(train_data=train_data, label=label_column, eval_metric='accuracy')
总结
在本文中,我分享来 8 个开源的AutoML库,这些库可以自动执行重复任务,例如超参数调整和模型选择,以加快数据科学家的工作。


















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









